
-
News Message
ViTAEv2 ImageNet Real 91.2%最高准确率
- by wittx 2022-03-19
以超大规模模型和无监督预训练方法为代表的超级深度学习技术,正在深刻地影响着人工智能领域的研究进展,在机器视觉、自然语言处理、多模态分析等多个领域不断取得突破。超级深度模型因其强大的表征能力和高效的样本效率,被寄予厚望用来帮助解决低资源和零资源情况下的一些挑战性任务,降低数据标注成本、加速算法开发周期、简化模型部署,赋能和促进新一代自动化机器学习技术的研发和落地。
目前,针对视觉主干神经网络的规模扩展性以及在各类下游任务上的适用性的研究成为了研究热点,吸引了学术界和工业界越来越多的注意力。探索研究院联合国际、国内著名大学在Vision Transformer骨干网络[1,2,12]、下游任务[7,8,9,13]、训练方法[10]等领域取得了一系列研究成果,其中视觉骨干网络ViTAE模型的研究工作发表在国际顶级学术会议NeurIPS 2021,探索了归纳偏置(Inductive Bias)在Vision Transformer的作用。
近期探索研究院联合悉尼大学在上述研究基础上进一步提出了更大规模、更优效果、对各类视觉任务具有更好适应性的新型视觉主干网络ViTAEv2。其中,具有6亿参数的ViTAE-H模型在不依赖任何外源数据的情况下,在ImageNet Real数据集达到了91.2%的分类准确度,在目前已知方法中排名世界第一。喜欢本文记得收藏、点赞、关注。
【注】文末提供技术交流群
【论文链接】
https://arxiv.org/abs/2202.10108
【代码链接】
https://github.com/Annbless/ViTAE
01、研究背景
图1 ViTAE模型结构图
Vision Transformer模型通过使用attention对划分成小块的图像进行建模,得到了很好的效果。在ViTAE[2]中,我们从模型设计的角度在transformer中引入了归纳偏置,并提出两种新的基础模块,即reduction cell (RC)和normal cell (NC), 如图1所示。Reduction cell使用多尺度卷积来为transformer模型引入尺度不变性。Normal cell使用并行的卷积分支,在不影响transformer全局建模能力的情况下引入局部归纳偏置。通过引入这样的两种机制,ViTAE模型取得了较好的数据效率和分类准确度。
然而,随着视觉领域超级深度学习的进一步发展,视觉主干网络呈现出往大规模网络发展的趋势。此外,视觉主干网络也需要适用于各种下游视觉任务,包括检测,分割,姿态估计等任务。为了进一步探索归纳偏置在大规模Vision Transformer网络中的作用,并改进ViTAE模型使其能广泛地适用于多种视觉任务,我们研究了模块堆叠方法,将ViTAE模型进一步拓展到600M规模,并采用先进的自监督预训练方法和迁移学习方法对ViTAE大模型进行训练,取得了比同类模型更高的分类准确率。进一步,我们提出了将上述两种基本组件按照多阶段(Multi-stage)方式进行堆叠的ViTAEv2模型。相关技术细节如下文所述。
02、大规模模型设计
为了探索归纳偏置在大规模Vision Transformer模型中的作用,我们参考ViT[3]的设计,对所提出的ViTAE模型进行了扩展,并对应的提出ViTAE-B (89M),ViTAE-L(311M),和ViTAE-H(644M)模型,分别包含12个NC模块,24个NC模块,和36个NC模块。我们相信ViTAE模型可以进一步扩展到10亿参数规模,并将在未来工作中进一步研究。然而,当模型规模过大时,ImageNet-1K的数据量不足以支撑模型的全监督训练,导致其容易过拟合到ImageNet-1K的训练数据,这使得我们难以分析所引入的归纳偏置在大规模模型情况下是否仍然有帮助。因此,我们采用了自监督学习方法MAE[4]中的预训练-微调范式对大规模ViTAE模型的训练方式进行优化,并基于此对ViTAE模型的效果进行了分析。
然而,MAE在预训练阶段采用随机采样的图片块作为输入。这样高度稀疏的离散图片块缺失了空间连续信息,难以让NC中的卷积分支学到合适的空间特征表示。受之前研究工作[5]的启发,在预训练过程中,我们将卷积分支的卷积核大小由3x3降到1x1,使得卷积分支更多地关注学到更好的特征表示而非过度关注空间信息。在微调阶段,我们使用zero-padding的方式在卷积分支将1x1的卷积核重新改变为3x3大小的卷积核并进行训练。
03、大规模模型效果
1).分类效果
表1 大规模ViTAE模型的图像分类效果
*表示使用PyTorch+GPU进行复现的结果,†表示使用ImageNet-22K进行额外微调
我们所提出的大规模ViTAE模型的效果如表1所示,引入归纳偏置的ViTAE-B模型相对于不包含归纳偏置的ViT-B模型有0.4%分类准确度的提升。类似的,对于更大尺寸的模型,例如ViTAE-L(311M),引入归纳偏置仍然可以带来0.3%分类准确度的提升。如果使用ImageNet数据集本身提供的22k版本进行微调,大规模的ViTAE模型还可以有1.0%左右准确的提升。此外,仅仅使用ImageNet-1K数据集进行训练时,我们所提出的ViTAE-H(644M)模型在ImageNet-Real数据集上达到了91.2%的分类准确度,超过了使用额外数据进行训练的3B规模的ViT-G[6]模型,在目前已知方法中排名世界第一。[https://paperswithcode.com/sota/image-classification-on-imagenet-real]
2).少样本学习效果
图2 大规模模型的少样本学习效果
此外,我们还探索了大规模ViTAE模型的少样本学习能力。我们分别使用1%,10%,和100%的数据对大规模ViTAE模型进行了微调。结果如图2所示,仅仅使用10%的数据进行训练,ViTAE-H模型的分类准确度达到了82.4%,超过了小规模模型ViTAE-13M使用100%数据进行全监督训练的准确度(81.0%)。这说明了大规模模型具有很强的少样本学习能力。
04、多阶段模型设计
图3 多阶段ViTAEv2模型的结构
为了探索引入归纳偏置在多个视觉任务上的效果,我们将所提出的RC和NC使用多阶段的方式进行堆叠并提出了多阶段的ViTAEv2模型,如图3所示。ViTAEv2模型能够输出多尺度的特征,这使得ViTAEv2模型可以和当前大多数用于检测、分割、姿态估计等任务的模型兼容,大大提升了ViTAE模型在下游任务的易用性。然而,最初版本的ViTAE模型采用原始的全注意力机制对输入图片进行操作。在输入图片尺寸变大的情况下,这样的全注意力机制会以图像尺寸的平方的级别增加计算复杂度,因此制约ViTAE模型的实际应用。为了降低这样的计算消耗并进一步引入归纳偏置,我们参考Swin Transformer [11],在ViTAEv2模型中额外引入了窗口注意力计算机制(window attention),使得注意力计算的代价和图像尺寸呈线性关系。具体来说,在注意力计算时,我们将图片划分成不重叠的窗口,并在每个窗口内部独立进行注意力的计算。
表2 多阶段模型注意力机制对比P代表Performer注意力机制,F代表全注意力机制,W代表窗口注意力机制
然而,引入这样的窗口注意力机制会制约Vision Transformer模型对长距离信息的建模能力。为此,我们探索了在不同阶段使用窗口注意力机制对模型表现和计算代价的影响,结果如表2所示。在表2中,P代表使用performer进行注意力计算,F表示使用全注意力机制,W表示使用窗口注意力机制。我们发现,在前两个阶段使用窗口注意力机制,后两个阶段使用全注意力机制可以取得性能和计算代价的最佳权衡。因此,我们采用了“WWFF”的方式对ViTAEv2模型进行了设计。此外,需要注意的是,ViTAEv2模型并不需要Swin Transformer中采用的额外相对位置编码和窗口移动(window shift)机制即可得到较好的效果,这归功于ViTAE模型中卷积模块已经能够提供位置信息并促进跨窗信息融合。对相对位置编码和窗口移动机制的消融实验结果如表3所示。
表3 窗口注意力机制中相对位置编码和窗口移动机制的消融实验
05、分类任务效果分析
表4 多阶段ViTAEv2模型的分类效果比较
我们首先在ImageNet-1K数据集上评估了所提出的ViTAEv2模型的分类任务表现能力。结果如表4所示。所提出的ViTAEv2模型在各个模型尺寸下均取得了SOTA的分类任务表现,并以更少的参数量取得了超越非多阶段堆叠方式的ViTAE模型。这验证了所引入的归纳偏置在多阶段的堆叠方式下的有效性。
06、下游任务效果分析
我们在物体检测、分割、和姿态估计三个下游任务上,对所提出的ViTAEv2模型的效果进行了分析和比较。我们使用MS COCO数据集进行检测任务的评估,使用ADE20K数据集对分割任务进行评估,以及使用AP10K数据集对动物姿态估计任务的表现进行评估。结果如表5(物体检测和实例分割任务),表6(语义分割任务),和表7(动物姿态估计任务)所示,我们所提出的ViTAEv2模型在各个下游任务上均取得了SOTA的效果,并显著高于其他同期模型。
表5 ViTAEv2在物体检测和实例分割数据集MS COCO上的效果比较
表6 ViTAEv2 在语义分割数据集ADE20k上的效果比较
表7 ViTAEv2在动物姿态估计数据集AP-10k上的效果比较
07、推理速度分析
表8 ViTAEv2推理速度比较
我们进一步评估了所提出的ViTAEv2模型的推理速度和模型表现。我们选取了模型规模相似的模型,并对所有模型使用TensorRT进行加速。结果如表8所示。我们可以发现,和Swin Transformer相比,ViTAEv2慢了10%左右的速度但是有1.3%分类准确度的显著提升。相较于T2T-ViT-24模型,ViTAEv2模型在推理速度和分类准确度上均有优势。
08、总结&未来工作
在本项研究工作中,我们探索并验证了归纳偏置在大规模Vision Transformer模型中的有效性,并取得了ImageNet Real上91.2%的最佳分类准确度。此外,使用多阶段堆叠方式的ViTAEv2模型在分类、检测、分割、姿态估计等任务上取得了SOTA的效果。这进一步说明了面对多种下游任务场景,归纳偏置对于提升Vision Transformer模型性能仍然效果显著。目前,我们主要探索了局部性和尺度不变性归纳偏置在Vision Transformer中的作用,未来还可以探索更多的归纳偏置的影响,如视角不变性等。由于ViTAE模型采用了并行的卷积和注意力分支的结构,尽管在推理过程中ViTAE模型可以利用并行计算的方式得到加速,但是使用基于动态图技术的深度学习框架(例如PyTorch)训练并行结构的效率会有下降。这个问题可以采用基于静态图技术的深度学习框架(例如TensorFlow)进行解决。如何从训练方法、模型架构设计进一步提升ViTAE模型的性能、降低训练和推理代价是值得未来进一步探索的研究方向。
参考文献
[1] Zhang Q, Xu Y, Zhang J, et al. ViTAEv2: Vision Transformer Advanced by Exploring Inductive Bias for Image Recognition and Beyond. arXiv preprint arXiv: 2202.10108, 2021.
[2] Xu Y, Zhang Q, Zhang J, et al. Vitae: Vision Transformer advanced by exploring intrinsic Inductive Bias. Neurips, 2021.
[3] Dosovitskiy A, Beyer L, Kolesnikov A, et al. An image is worth 16x16 words: Transformers for image recognition at scale. ICLR, 2021.
[4] He K, Chen X, Xie S, et al. Masked autoencoders are scalable vision learners. arXiv preprint arXiv:2111.06377, 2021.
[5] Zhang J, Cao Y, Wang Y, et al. Fully point-wise convolutional neural network for modeling statistical regularities in natural images. ACM MM, 2018.
[6] Zhai X, Kolesnikov A, Houlsby N, et al. Scaling Vision Transformers. arXiv preprint arXiv:2106.04560, 2021.
[7] Wang W, Cao Y, Zhang J, et al. FP-DETR: Detection Transformer Advanced by Fully Pre-training. ICLR, 2022.
[8] Lan M, Zhang J, He F, et al. Siamese Network with Interactive Transformer for Video Object Segmentation. AAAI, 2022.
[9] Wang W, Cao Y, Zhang J, et al. Exploring Sequence Feature Alignment for Domain Adaptive Detection Transformers. ACM MM, 2021.
[10] Xu Y, Zhang Q, Zhang J, et al. RegionCL: Can Simple Region Swapping Contribute to Contrastive Learning?. arXiv preprint arXiv:2111.12309, 2021.
[11] Liu Z, Lin Y, Cao Y, et al. Swin transformer: Hierarchical Vision Transformer using shifted windows. ICCV, 2021.
[12] He L, Dong Y, Wang Y, et al. Gauge equivariant transformer. Neurips, 2021.
[13] Yu H, Xu Y, Zhang J, et al. AP-10K: A Benchmark for Animal Pose Estimation in the Wild. Neurips, 2021.
Share Http URL: http://www.wittx.cn/get_news_message.do?new_id=920

Best Last Month
Information industry by wittx
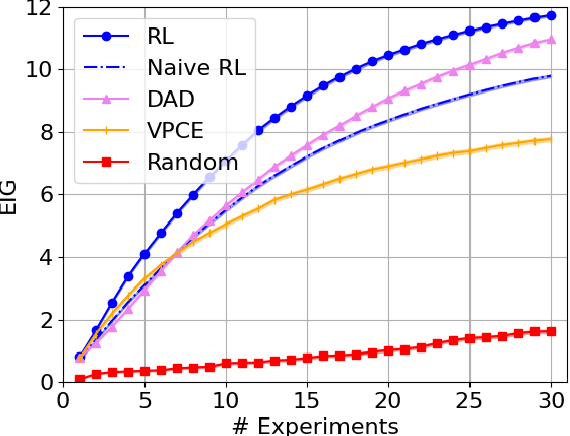
Information industry by wittxOptimizing Sequential Experimental Design with Deep Reinforcement Learning

Information industry by wittx
Medical science by wittx
Information industry by wittxInstitute for Theoretical Physics G¨ oteborg University and Chalmers University of Technology G¨ ote
Information industry by wittx
Information industry by wittx

Electronic electrician by wittx

Information industry by wittx

Information industry by wittx













