
-
News Message
准确率达 95%,机器学习预测复杂新材料合成
- by wittx 2022-01-03
科学家和机构每年都投入非常多的资源来发现新材料,以期为燃料提供催化剂。随着自然资源的减少,以及对更高价值和先进性能产品的需求增长,研究人员越来越多地关注到纳米材料。但识别新材料的连续实验方法对材料发现施加了不可逾越的限制。
近日,美国西北大学和丰田研究所(TRI)的研究人员应用机器学习来指导新纳米材料的合成,消除了材料发现相关的障碍。这种训练有素的算法,可通过定义数据集来准确预测可用于清洁能源、化学和汽车行业燃料的重要催化剂。
该研究以「Machine learning–accelerated design and synthesis of polyelemental heterostructures」为题,于 2021 年 12 月 22 日发表在《Science Advances》杂志上。
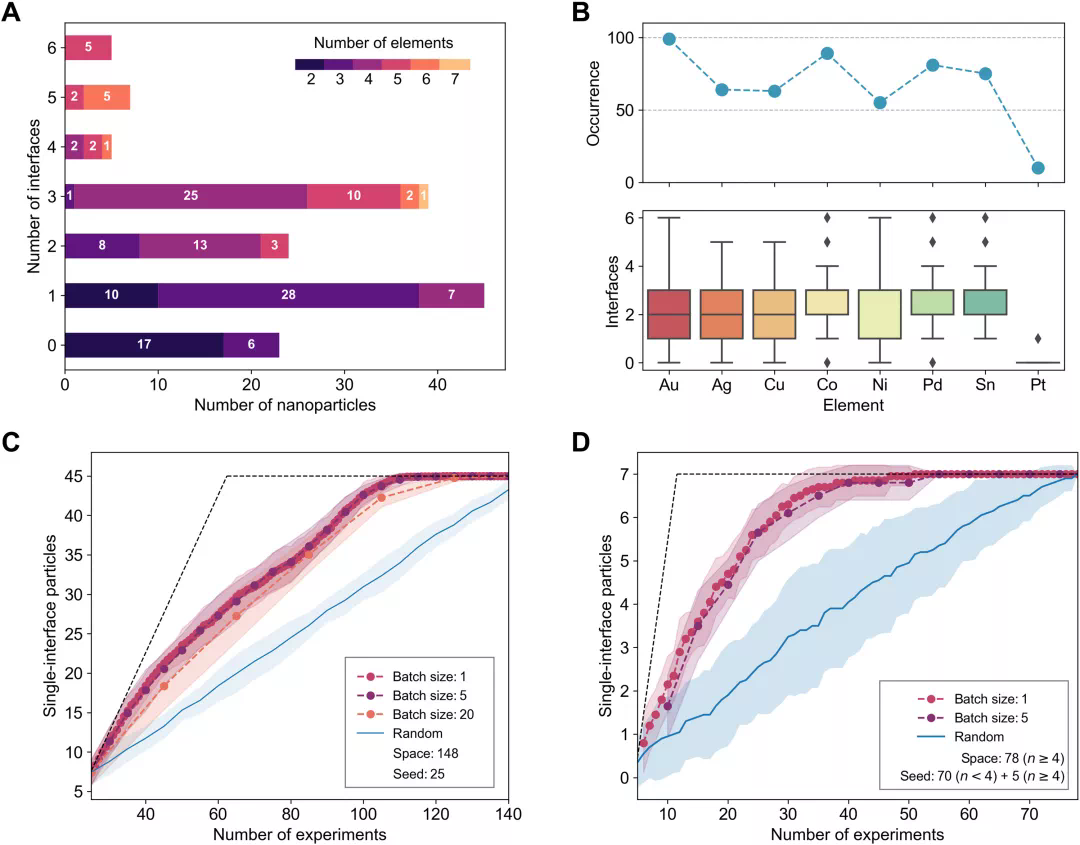
西北大学纳米技术专家、该论文的通讯作者 Chad Mirkin 说:「我们让这个模型告诉我们,多达七种元素的混合物会可以制造出以前没有过的东西。机器预测了 19 种可能性,在对每种可能性进行实验测试后,我们发现其中 18 种预测是正确的。」
绘制材料基因组
Mirkin 此次发明的名为「Megalibrary」(巨库)的数据生成工具极大地扩展了研究人员的视野。每个 Megalibrary 都包含数百万甚至数十亿个纳米结构,每个纳米结构的形状、结构和成分都略有不同,所有这些都在 2×2 平方厘米的芯片上进行了位置编码。迄今为止,每个芯片包含的新无机材料比科学家收集和分类的还要多。
Mirkin 的团队通过使用一种称为扫描探针嵌段共聚物光刻(SPBCL)的技术开发了 Megalibraries,这是一种大规模并行纳米光刻工具,能够每秒对数十万个特征进行特定位置的沉积。
NP 数据集和模拟优化活动的统计数据。
在绘制人类基因组图谱时,科学家的任务是识别四种碱基的组合。但「材料基因组」包括元素周期表中任何可用的 118 种元素的纳米粒子组合,以及形状、大小、相形态、晶体结构等参数。以 Megalibraries 的形式构建更小的纳米粒子子集,将使研究人员更接近完成材料基因组的完整图谱。
「即使我们能比地球上任何人都更快地制造材料,这仍然是可能性的海洋中的一滴水。」Mirkin 说。「我们想定义和挖掘材料基因组,我们的方法是通过人工智能。」
机器学习应用程序非常适合解决定义和挖掘材料基因组的复杂性,但受限于创建数据集以在空间中训练算法的能力。Mirkin 表示,Megalibraries 与机器学习的结合可能最终会解决这个问题,从而了解哪些参数会驱动某些材料特性。
化学家无法预测的材料
如果 Megalibraries 提供地图,则机器学习提供图例。
Mirkin 表示,使用 Megalibraries 作为用于训练 AI 算法的高质量和大规模材料数据的来源,使研究人员能够摆脱通常伴随材料发现过程而来的「敏锐的化学直觉」和连续实验。
在这项研究中,该团队编译了先前生成的由具有复杂成分、结构、尺寸和形态的纳米粒子组成的 Megalibrary 结构数据。他们使用这些数据来训练模型,并要求它预测会产生某种结构特征的四个、五个和六个元素的组成。在 19 次预测中,机器学习模型正确预测了 18 次新材料——准确率约为 95%。
用于发现四元金属 SINP 的闭环优化。
由于对化学或物理学知之甚少,仅使用训练数据,该模型就能够准确预测地球上从未存在过的复杂结构。
「正如这些数据所表明的,机器学习的应用,结合 Megalibrary 技术,可能是最终定义材料基因组的途径。」TRI 的高级研究科学家 Joseph Montoya 说。
金属纳米粒子显示出催化工业关键反应的前景,例如析氢、二氧化碳(CO2)还原和氧还原和析出。该模型在西北大学建立的大型数据集上进行了训练,以寻找具有围绕相位、尺寸和其他结构特征设置参数的多金属纳米粒子,这些参数会改变纳米粒子的特性和功能。
Megalibrary 技术还可能推动对未来至关重要的许多领域的发现,包括塑料升级回收、太阳能电池、超导体和量子比特。
该团队现在正在使用该方法寻找对清洁能源、汽车和化工行业的燃料过程至关重要的催化剂。确定新的绿色催化剂将使废物和大量原料转化为有用物质。生产催化剂还可用于替代昂贵且稀有的材料。
论文链接:https://www.science.org/doi/10.1126/sciadv.abj5505
相关报道:https://phys.org/news/2021-12-machine-synthesis-complex-materials.html
Share Http URL: http://www.wittx.cn/get_news_message.do?new_id=885

Best Last Month

Information industry by wittx

Information industry by wittx
Information industry by wittx
Information industry by wittx
Information industry by wittx

Water conservancy and hydropower by wittx

Information industry by wittx

Information industry by wittx

Information industry by wittxAccelerating process development for 3D printing of new metal alloys
Information industry by wittx



