
-
News Message
Hash算法以及暴雪Hash
- by show 2021-02-15
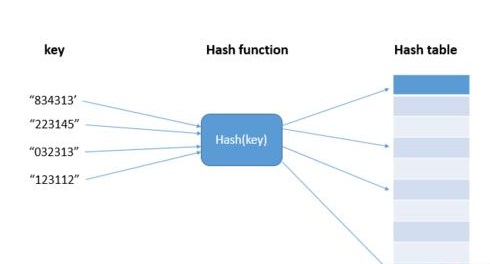
Share Http URL: http://www.wittx.cn/get_news_message.do?new_id=693

Best Last Month

Information industry by wittx
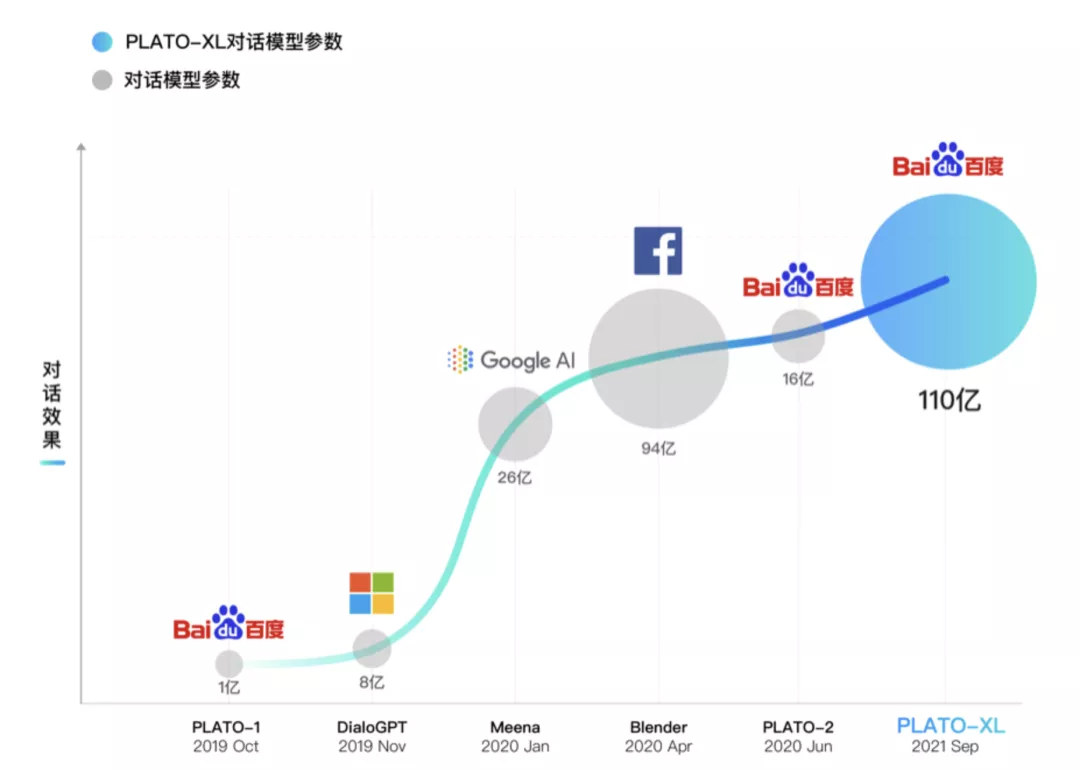
Information industry by wittx
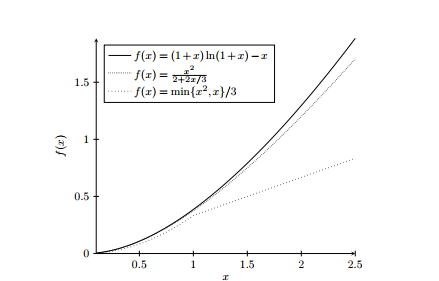
Information industry by wittxTheory of Evolutionary Computation – Recent Developments in Discrete Optimization
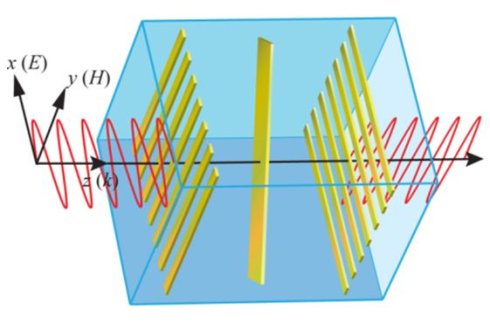
Information industry by wittx
Information industry by wittx
Information industry by wittx
Information industry by wittx
Information industry by wittx
Information industry by wittx
Information industry by wittx

