
-
News Message
深度神经网络 ResNet ResNeSt
- by wittx 2020-11-01
2015年ResNet在ImageNet上取得了非常惊艳的效果,以3.57%的error rate取得那年的第一名。作为神经网络发展史上具有里程碑意义的网络结构,引起了很多人的关注和研究,从而发展出很多改进版本,包括ResNetV2,Wider-ResNet,Dilated ResNet,ResNeXt,SENet,ResNeSt等等。因此,去认真学习ResNet一路的发展历程非常有必要和意义。本文参考了相关论文以及一些优秀博客,整理一下这些网络结构改进的思路,方便日后回顾学习。
ResNet的诞生
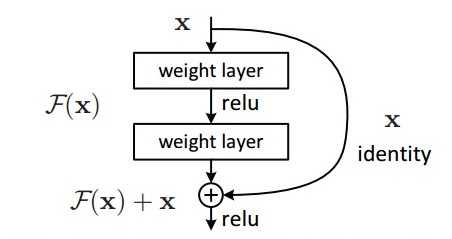
从AlexNet开始,网络结构逐渐向越来越深的方向发展,大家直观地认为随着网络深度的增加,网络的特征拟合能力会越来越强,因此更深的模型理应取得更好的效果。但是人们发现随着网络深度的增加,模型的精度不是一直提升的,而且训练的误差和测试的误差都变高了,这显然不是过拟合的问题。另外,batch normalization的提出也基本解决了网络梯度消失和梯度爆炸问题。作者认为这应该是一个优化问题,即随着网络的加深,网络优化会变得更加困难。解决方案就是引入了short connection,它的思想就是与其让stack layer去直接学习潜在映射,不如去学习残差,这样会更容易优化,因此ResNet诞生了。

ResNet网络主要由两种block堆叠构成,一种是Basic Block,另一种是Bottleneck Block。

少于50层的ResNet由Basic Block组成,大于50层的ResNet由Bottleneck Block组成。

ResNet网络结构具有如下的一些特点
- 受VGG的启发,卷积层主要是3×3卷积;
- 每个网络结构都包含三部分:输入部分、输出部分、中间卷积部分(中间卷积部分包含4个stage),尽管ResNet的变种很多,但是都遵循上述结构特点,网络之间的不同主要在于中间卷积部分的block参数和个数差异;
- 输入部分:数据进入网络后先经过输入部分(conv, bn, relu, maxpool)conv是一个size=7x7,stride=2的大卷积核,maxpool是一个size=3x3,stride=2的最大池化,经过输入部分,特征图为输入图像的1/4;
- 中间卷积部分:四个stage的block,通过3x3卷积的堆叠实现信息的提取,同一stage,具有相同数量的3x3滤波器;每个stage通过stride为2的卷积执行下采样,而且这个下采样只会在每一个stage的第一个卷积完成,有且仅有一次;在降采样的同时feature map数量加倍;
- 输出部分:如果是分类,经过avgpool, fc(一般fc用1x1卷积代替)得到输出;如果是分割或特征提取则返回最后以及中间各个stage的feature map;
- 整个ResNet不使用dropout,每个卷积层之后都紧接着BatchNorm layer。
常规改进
原始的ResNet在数据进入网络后会经过一个stride=2的7x7卷积,有大量的特征没有被利用,因此可以将stride=2改成stride=1来减少信息损失,增大特征尺寸,但是会减小感受野。7x7卷积也可以拆成3个3x3卷积来减少计算量,增加模型非线性。
另外在每个stage的第一个卷积都是stride=2的卷积,这样也会导致有3/4的特征没有被利用,也是可以改进的,一种改进是将下采样交给3x3卷积去做,减少信息大量损失。进一步将identity部分的下采样交给avgpool去做,也可以避免1x1卷积和stride同时造成信息流失。

ResNetV2
主要是对ResNet中各个部件顺序的进一步调整。因为原来在相加后进入relu,那么残差块的输出永远是非负的,制约了模型的表达能力,故将Relu放到残差块内部。v2提出了pre-activation,即进入每一个block时先进行BN+ReLU再接卷积,实验表明这样的调整是网络更加容易优化,并且网络越深效果越明显。

Wider ResNet
使用ResNet可以实现上千层网络的训练,并且实验结果表明,增加网络的深度可以提高效果,但是随着网络不断加深,每提高一点都需要大幅增加网络深度,而且越深的网络训练越慢。那么是不是网络越深越好呢,WRN探讨了宽度(所谓宽度就是每个卷积层输出的通道数)对网络的影响,发现增加网络的宽度同样能够提升网络的性能,而且宽的网络相比深的网络计算更加高效(尽管参数量更多,但是硬件加速效果更好)。本文还在两个卷积层中间增加dropout来抵抗过拟合。


Dilated ResNet
在CNN进行图像分类时会逐渐降低分辨率,从而丢失位置信息,这样会限制分类的准确性,故将Dilated Convolution引入ResNet中来来增大特征图的分辨率,在不增加模型参数的情况下提高网络性能,并验证在无论是在图像分类还是目标检测、图像分割中都是有效的。另外引入去网格方法去除Dilated Conv带来的网格效应(当特征图的频率含量高于扩张卷积的采样率时,就会出现网格伪影)。
- 本文将ResNet的最后两个stage换成Dilated Conv,因为作者认为这样图像的细节基本都能保留了,另外就是考虑到如果全部stage都换成Dilated Conv硬件能力要求太高。
- 因为max pooling会保留大量高频信息,所以去掉开始的max pooling,并用两个残差模块替代;在网络最后增加两个去掉short connection的模块进一步去除网格效应(之所以去掉short connection是因为发现它也会带来网格效应)。

ResNeXt
将inception的思想与ResNet相结合,证明除了增加网络的深度和宽度外,还可以通过增加cardinality来提升模型的性能。将ResNet中各stage中的3x3卷积换成分组卷积便构成了ResNeXt。
这里提一句将inception和ResNet相结合的还有inception-v4。
SE-ResNet
SENet是在通道纬度上做attention,使模型更加关注信息量大的通道特征,作为通用的模块,当然也是可以被用在ResNet上的,将SE模块插在residual和short connenction相加之前,效果也很不错。
SE模块是在通道上用attention,其整体思路如下:


SKNet
SKNet也是一种通用模块,它是让模型自己去学习选择卷积核的大小,同样的可以被用在ResNet中,将ResNet中四个stage中的conv换成SK conv即可。(SK在分类和分割上效果不错,貌似在检测上不是很好)
SK模块是在不同卷积核分支上用attention,其整体思路如下:


ResNeSt
在SENet,SKNet,ResNeXt的基础上提出了Split-Attention模块,用于替换ResNet中四个stage的conv。在分类、检测、分割上都有非常明显的提升。
Split-Attention是在每个分组内用attention,其整体思路如下:

参考文献
- Deep Residual Learning for Image Recognition
- Identity Mappings in Deep Residual Networks
- Wide Residual Networks
- Dilated Residual Networks
- Squeeze-and-Excitation Networks
- Selective Kernel Networks
- Aggregated Residual Transformations for Deep Neural Networks
- ResNeSt: Split-Attention Networks
- Bag of Tricks for Image Classification with Convolutional Neural Networks
- https://www.cnblogs.com/shine-lee/p/12363488.html
- https://cloud.tencent.com/developer/article/1627402
Share Http URL: http://www.wittx.cn/get_news_message.do?new_id=540

Best Last Month

Information industry by wittx

Information industry by wittx

Information industry by wittx

Information industry by wittx

Information industry by wittx
Information industry by wittxAn artificial intelligence accelerated virtual screening platform for drug discovery
Information industry by wittx
.jpg)
Computer software and hardware by wittx

Information industry by wittx

Traffic by wittx




