
-
News Message
多智能体强化学习中使用attention机制
- by wittx 2020-10-06
.方法
直接上方法部分,前面的有时间再补。
1.1. Multiagent下的Attention机制
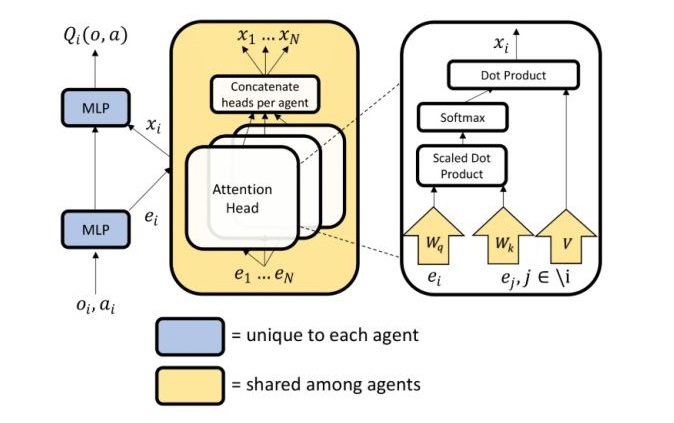
主要思路:为每一个agent learn一个critic来选择性的关注来自其他agent的信息。
形式化:
第
![[公式]](/images/download/1601967853782_20292.png) 个agent的Q函数表示为
个agent的Q函数表示为 ![[公式]](/images/download/1601967853817_91377.png) 其中
其中![[公式]](/images/download/1601967853869_80492.png) ,
, ![[公式]](/images/download/1601967853911_74444.png) 。
。 ![[公式]](/images/download/1601967853951_34080.png) 是一个双层的densenet,
是一个双层的densenet, ![[公式]](/images/download/1601967853991_41676.png) 是一个单层embedding函数。来自其他智能体的贡献通过加权求和后用
是一个单层embedding函数。来自其他智能体的贡献通过加权求和后用 ![[公式]](/images/download/1601967854018_40394.png) 表示:
表示:![[公式]](/images/download/1601967854061_17958.png) 很容易看出,
很容易看出, ![[公式]](/images/download/1601967854140_51292.png) 就是智能体
就是智能体 ![[公式]](/images/download/1601967854173_15177.png) 对
对 ![[公式]](/images/download/1601967854212_82614.png) 的影响,
的影响,![[公式]](/images/download/1601967854251_96582.png) 是加权系数。那这个
是加权系数。那这个 ![[公式]](/images/download/1601967854277_29353.png) 到底怎么计算?系数
到底怎么计算?系数![[公式]](/images/download/1601967854305_19292.png) 怎么确定?
怎么确定?先说用于描述其他智能体信息的
![[公式]](/images/download/1601967854338_18108.png) ,实际上是对智能体
,实际上是对智能体 ![[公式]](/images/download/1601967854368_52661.png) 的embedding,表达式为
的embedding,表达式为 ![[公式]](/images/download/1601967854400_81162.png) 。这里面的
。这里面的 ![[公式]](/images/download/1601967854444_42635.png) 和式(1)里面的定义的embedding函数是一样的,其输出左乘一个矩阵
和式(1)里面的定义的embedding函数是一样的,其输出左乘一个矩阵 ![[公式]](/images/download/1601967854488_62900.png) (相当于变换
(相当于变换 ![[公式]](/images/download/1601967854516_74877.png) 作用于嵌入函数)。而
作用于嵌入函数)。而 ![[公式]](/images/download/1601967854542_10737.png) 函数则是逐元素的激活函数(文章里面使用的leaky ReLU)。
函数则是逐元素的激活函数(文章里面使用的leaky ReLU)。再说注意力机制的权重
![[公式]](/images/download/1601967854566_79070.png) ,直接看定义
,直接看定义 ![[公式]](/images/download/1601967854598_89135.png)
即通过比较智能体
![[公式]](/images/download/1601967854672_76674.png) 与
与 ![[公式]](/images/download/1601967854702_68793.png) 的嵌入
的嵌入![[公式]](/images/download/1601967854749_96585.png) ,
,![[公式]](/images/download/1601967854782_91362.png) 来确定,其中
来确定,其中 ![[公式]](/images/download/1601967854812_11252.png) 。具体来说,
。具体来说, ![[公式]](/images/download/1601967854859_28169.png) 将
将 ![[公式]](/images/download/1601967854893_77118.png) 变为一个query,
变为一个query, ![[公式]](/images/download/1601967854923_74748.png) 将
将 ![[公式]](/images/download/1601967854957_41784.png) 变为一个key。(看表达式,列向量转置变成行向量,与经过两个变换后的行向量相乘,形式上就得到了标量,因为
变为一个key。(看表达式,列向量转置变成行向量,与经过两个变换后的行向量相乘,形式上就得到了标量,因为 ![[公式]](/images/download/1601967854991_89490.png) 和
和 ![[公式]](/images/download/1601967855033_18655.png) 基于相同的嵌入函数因此有相同的维数,且元素为二进制)。最后再来个softmax,并使用两个矩阵的维数进行归一化,防止梯度消失。
基于相同的嵌入函数因此有相同的维数,且元素为二进制)。最后再来个softmax,并使用两个矩阵的维数进行归一化,防止梯度消失。现在可以放Q函数的结构图了

1.2. 损失函数和策略更新
Critic更新是通过最小化联合回归函数实现的
![[公式]](/images/download/1601967855469_52204.png)
其中
![[公式]](/images/download/1601967855538_40776.png) ,
, ![[公式]](/images/download/1601967855607_31531.png) 和
和 ![[公式]](/images/download/1601967855638_83392.png) 表示目标Critics和目标policies,
表示目标Critics和目标policies, ![[公式]](/images/download/1601967855669_70869.png) 用来平衡最大熵和回报。
用来平衡最大熵和回报。Policy的更新的梯度计算方法为
![[公式]](/images/download/1601967855699_50764.png)
上面这个公式,最基本的形式是
![[公式]](/images/download/1601967855841_26691.png) (原理参考这里),式(6)中基本思路是用
(原理参考这里),式(6)中基本思路是用 ![[公式]](/images/download/1601967855891_21083.png) 代替
代替 ![[公式]](/images/download/1601967855936_26677.png) ,实际使用了多智能体场景下的优势函数[1]
,实际使用了多智能体场景下的优势函数[1]![[公式]](/images/download/1601967855965_24676.png) 其中,
其中,![[公式]](/images/download/1601967856024_44872.png)
多说一句这个
![[公式]](/images/download/1601967856083_26858.png) ,表示固定其他智能体动作下某个动作的值函数的期望,这也是一种多智能体贡献分配的解决方案。进一步,在计算时是这样求期望的
,表示固定其他智能体动作下某个动作的值函数的期望,这也是一种多智能体贡献分配的解决方案。进一步,在计算时是这样求期望的![[公式]](/images/download/1601967856141_24780.png)
2. 实验
2.1 Setup
(1)设计实验study the scalability
这部分实验使用的是Cooperative Treasure Collection这一env。这个环境以及后面另一个实验的环境都是基于multiagent particle environment framework。

(2)设计实验evaluate attention mechanism
这部分实验使用了一个叫做Rover-Tower的env

2.2 Baselines
2.3 Results and Analysis
results
直接贴两个实验中Mean Episode Rewards训练曲线。

analysis
(1)Impact of Rewards and Required Attention分析了attention的作用并解释了右边的曲线中uniform MAAC比MADDPG差的原因:cooperative下rewards是all agents共享的,因此单个智能体的critic不需要聚焦来自其他智能体的信息来获取更高的reward(这一解释。。。感觉一般吧,可能是我没看懂\狗头);此外单个智能体的局部信息用来预测已经可以得到很好的分数了(既然足够了,MAAC还是比uniform MAAC好啊,这个回头再去看看代码)。
实验1(Cooperative Treasure Collection)中,场景设定是完全合作,每个智能体可以观察到全局的信息。在代码中,n_visible=7,表示每个智能体可以看到7个其他智能体和treasure。那么partial obsevation会不会使性能变差呢?于是分别设定n_visible=1、2、3、4、5、6,7,得到曲线如下。结果显示部分可观测时的回报比全部观测更高,这不符合常识,我们一般认为完全观测做出的决策会更优。代码里面有一个距离远近的排序,对于collector而言,知道离自己最近的几个treasures和agents已经足够了,所以n_visible=1、2、3的时候回报比较高?

(2)scalibility
直接看图,,,

3. 代码分析
3.1 代码结构
MAAC --algorithms ----attention_sac.py#算法 --envs ----mpe_scenarios ------fullobs_collect_trasures.py#从名字就能看出,这个是完全观测的,不是partial obs ------multi_speaker_listener.py#这两个场景和maddpg里面的场景基本一样 --utils ----agents.py ----buffer.py ----critic.py ----env_wrappers.py ----make_env.py ----misc.py ----policies.py --main.py
2.1 Scenarios
(1)Cooperative treasure collections
场景描述:包含8个智能体(6个hunter(代码里面叫做collector),2个bank),其颜色和不同treasure颜色相对应(一样)。treasure有6个,每一个被收集者收集后会随机重生。hunter的任务就是收集treasure然后deposit(跑过去)到bank,而bank的任务就是尽可能多的收集hunters的treasure。
奖励设置:
对于hunter而言,既有共享奖励,又有属于自己的奖励:(a)收集到treasure它自己会得到全局的reward;(b)deposit会使得所有agents获得reward; (c)碰到其他agents则惩罚。
观测空间:np.concatenate([[位置(x,y)], [速度(v_x,v_y)], [收集到的treasure的类型编码(bank没有这个元素)], [离其他智能体的距离、速度、agent编码], [到treasures的距离、treasure类型编码]]),hunter的obsp一般是86维,bank的obsp是84维。
动作空间:one-hot:[上,下,左,右,stay]。
参考
- ^abFoerster, J., Farquhar, G., Afouras, T., Nardelli, N., and Whiteson, S. Counterfactual multi-agent policy gradients. In AAAI Conference on Artificial Intelligence, 2018.
- ^Lowe, R., Wu, Y., Tamar, A., Harb, J., Abbeel, O. P., and Mordatch, I. Multi-agent actor-critic for mixed cooperative-competitive environments. In Advances in Neural Information Processing Systems, pp. 6382–6393, 2017.
Share Http URL: http://www.wittx.cn/get_news_message.do?new_id=475

Best Last Month
Information industry by wittx
Information industry by wittx

Information industry by wittx
Information industry by wittx
Information industry by wittx

Information industry by wittx

Information industry by show

Traffic by wittxThree Small Stickers in Intersection Can Cause Tesla Autopil
Information industry by wittxINTRODUCTION TO PROBABILITY AND STATISTICS FOR ENGINEERS AND SCIENTISTS
Information industry by wittx
