
-
News Message
自动驾驶运动规划算法
- by wittx 2020-06-07
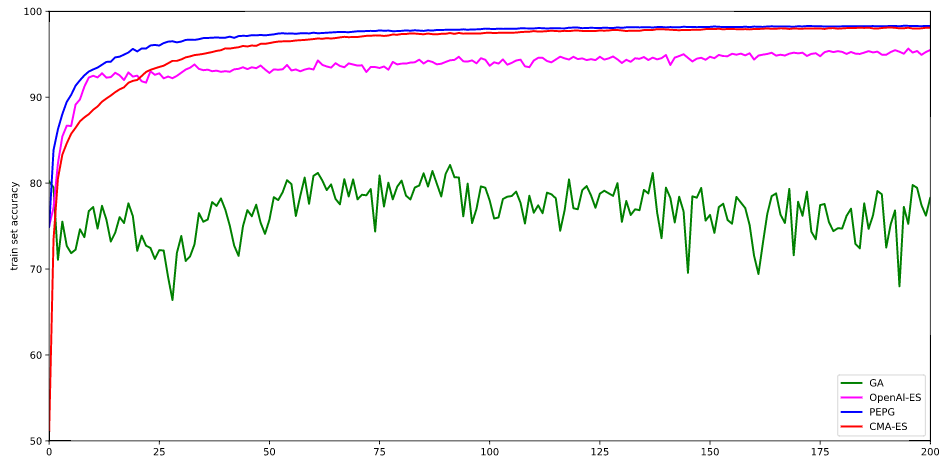
Hybird A*算法保证生成的路径是车辆可实际行驶的,但它仍然包含很多不必要的车辆转向操作,我们可以对其进行进一步的平滑和优化。
Objective Function
对于Hybird A*生成的车辆轨迹序列:
![[公式]](/images/download/1591511316756_81288.png) ,论文【1】中提出如下的目标优化函数(Objective Function):
,论文【1】中提出如下的目标优化函数(Objective Function):![[公式]](/images/download/1591511317121_44135.png)
该优化函数是Voronoi Term、Obstacle Term、Curvature Term和Smoothness Term四个部分的加权平均:第一个部分引导车辆尽可能的避开障碍物区域;第二个部分惩罚车辆与障碍物的碰撞行为;第三部分约束规划的每个点的最大曲率,并提供车辆非完整约束的保证;第四个部分是轨迹的平滑性约束。
![[公式]](/images/download/1591511317363_43157.png) 、
、![[公式]](/images/download/1591511317502_24431.png) 、
、![[公式]](/images/download/1591511317637_31950.png) 、
、![[公式]](/images/download/1591511317787_10652.png) 分别是这四个部分的权重因子。
分别是这四个部分的权重因子。1、Voronoi Term
Voronoi Term中引入了Voronoi Field的概念,Voronoi Field是机器人Motion Planning领域两种经典算法Voronoi Diagram和Potential Field的结合。
此处采用Voronoi Field的定义如下:
![[公式]](/images/download/1591511318305_41577.png)
其中
![[公式]](/images/download/1591511318538_62359.png) 和
和![[公式]](/images/download/1591511318674_91519.png) 分别是路径点(x,y)到最近障碍物的距离和到最近Voronoi Diagram的边的距离。越靠近障碍物,
分别是路径点(x,y)到最近障碍物的距离和到最近Voronoi Diagram的边的距离。越靠近障碍物,![[公式]](/images/download/1591511318822_62707.png) 的值越大,越接近1;越靠近Voronoi Edge,
的值越大,越接近1;越靠近Voronoi Edge,![[公式]](/images/download/1591511318956_61320.png) 的值越接近0。
的值越接近0。
上图图左一为Voronoi Field的实际效果,上图右一是标准Potential Field的实际效果。可以看到,Voronoi Field对狭窄通道的效果要明显优于Potential Field。

2、Obstacle Term
Obstacle Term中
![[公式]](/images/download/1591511319553_56400.png) 是路径点坐标位置,
是路径点坐标位置,![[公式]](/images/download/1591511319691_65524.png) 是附近障碍物的位置,
是附近障碍物的位置,![[公式]](/images/download/1591511319827_37456.png) 是决定Obstacle Term是否影响路径Cost的阈值。当路径点距离障碍物的距离小于
是决定Obstacle Term是否影响路径Cost的阈值。当路径点距离障碍物的距离小于![[公式]](/images/download/1591511319959_50057.png) 时,Obstacle Term才会对轨迹的Cost进行惩罚。距离障碍物越近,
时,Obstacle Term才会对轨迹的Cost进行惩罚。距离障碍物越近,![[公式]](/images/download/1591511320059_12227.png) 的值越小,Obstacle Term的值就越大,整个轨迹的Cost也就越大。这样就达到了使得平滑后的路径远离障碍物的效果。
的值越小,Obstacle Term的值就越大,整个轨迹的Cost也就越大。这样就达到了使得平滑后的路径远离障碍物的效果。这里
![[公式]](/images/download/1591511320204_36432.png) 一般使用二次函数。即:
一般使用二次函数。即:![[公式]](/images/download/1591511320344_34502.png)
3、Curvature Term
对于一系列的点
![[公式]](/images/download/1591511320541_17242.png) ,
,![[公式]](/images/download/1591511320686_23312.png) ,即为规划路径的方向向量;
,即为规划路径的方向向量;![[公式]](/images/download/1591511320826_48705.png) 为路径点的方向角变化。
为路径点的方向角变化。![[公式]](/images/download/1591511320956_93815.png) 为
为![[公式]](/images/download/1591511321092_63434.png) 处的曲率。与Obstacle Term类似,Curvature Term也设置了一个最大允许的路径曲率
处的曲率。与Obstacle Term类似,Curvature Term也设置了一个最大允许的路径曲率![[公式]](/images/download/1591511321234_67200.png) ,当曲率大于
,当曲率大于![[公式]](/images/download/1591511321366_92611.png) 时,Curvature Term才会对路径的Cost施加惩罚。
时,Curvature Term才会对路径的Cost施加惩罚。4、Smoothness Term
平滑项利用当前点前后两个方向向量的差值来衡量,方向向量既可以衡量方向的改变,也可以体现轨迹点的分布变换。
5、梯度下降
确定Objective Function函数之后,就可以利用Conjugate Gradient(CG,共轭梯度法)或者Gradient Descent求解最优路径。

代码参见:
https://github.com/teddyluo/hybrid-a-star-annotation/blob/master/src/smoother.cpp
平滑后的路径如下:

Non-Parametric Interpolation
对路径进行非线性优化后,我们得到一条比Hybird A*算法路线更加平滑的路径,但是这条路径仍然由一段段的折线组成。在论文【1】中提到在它们的实现中组成路径的折线大约在0.5m-1m,这些折线仍然会导致车辆会出现非常生硬的转向,所以需要使用插值算法进一步平滑路径。
参数化的插值算法对噪声非常敏感,比如当路径中两个顶点非常接近时,三次样条曲线(Cubic Spline)算法的输出就会产生非常大的震荡。
【1】中提出通过固定原始路径顶点,然后在固定顶点之间插入新的顶点,最后使用Conjugate Gradient(CG,共轭梯度法)最小化曲率的非参数插值(Non-Parametric Interpolation)方法对曲线进一步平滑,平滑效果如下:

参考资料
1、Practical Search Techniques in Path Planning for Autonomous Driving。Dmitri Dolgov,Sebastian Thrun,Michael Montemerlo,James Diebel.
2、Path Planning in Unstructured Environments, A Real-time Hybrid A* Implementation for Fast and Deterministic Path Generation for the KTH Research Concept Vehicle.
Share Http URL: http://www.wittx.cn/get_news_message.do?new_id=283

Best Last Month

Information industry by show
Information industry by wittx
Information industry by wittx
Information industry by wittx
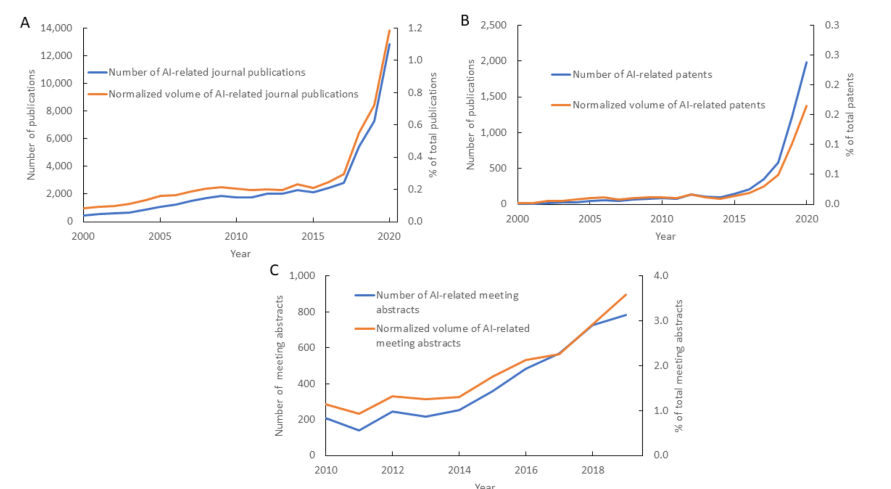
Information industry by wittxArtificial Intelligence in Chemistry: Current Trends and Future Directions
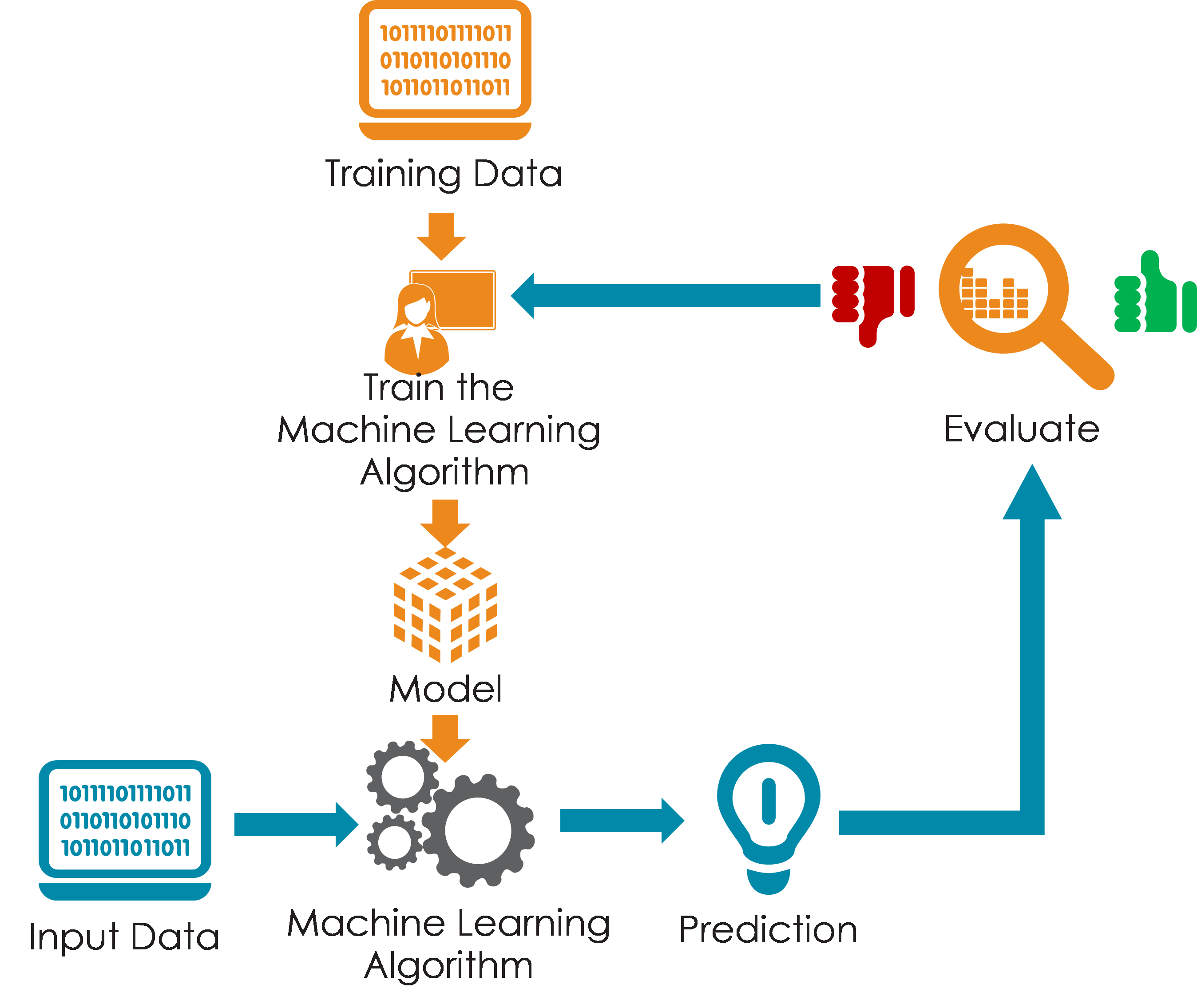
Information industry by wittxA Data-Driven Automatic Design Method for Electric Machines Based on Reinforcement Learning and Evol

Information industry by wittx
Information industry by wittx

Electronic electrician by wittx

Information industry by wittx


