-
News Message
量子概率驱动的神经网络
- by wittx 2019-06-19

今天要介绍的文章与当前大火的 BERT 同获最佳论文,摘得 NAACL 2019 最佳可解释NLP论文(Best Explainable NLP Paper)。NAACL 与 ACL 和 EMNLP 并称之为 NLP 三大顶会,去年 ELMO 获得 outstanding paper,今年一共有五篇最佳论文,分别是 Best Thematic Paper,Best Explainable NLP Paper,Best Long Paper 以及最佳短文和最佳 resource 论文。
目前用深度学习的方法来做 NLP 任务已经越来越火了,很多具有复杂结构的神经网络被声称在给定规范良好的输入和输出的某些数据集有着更好表现。但是神经网络本身的可解释性的问题,像一颗定时炸弹,始终萦绕在大家心头。
如果始终在 how 的问题上,在应用上下猛药,也可能像炼丹术一样,有可能并没有对准病症。而 why 的问题,也就是它为什么 work 的机制,是一个更难的问题,正吸引越来越多的研究者从不同的角度和视野去挑战。
哈士奇还是狼?
对于神经网络的工作原理,有一个形象的例子,那就是哈士奇还是狼(husky or wolf)的问题[1]。大部分人都可以很正确地判断出左图中的动物是狼,而右图中的动物是哈士奇,这两个图对人而言还是相对不难。不出意外地,神经网络模型也能够把这两张图分得很准。
当让神经网络模型分下面这张图,它就凌乱了,认为下图是狼。
原来神经网络模型分类这两个类别,靠的是背景,而不是真的知道哈士奇和狼之间细微的区别。换句话说,一旦哈士奇大哥偶尔跑到雪地上,神经网络就傻眼了。如果有一天用户或者产品经理跑过来说,这只站在雪地里的哈士奇,一定要在下一个版本被正确地分类,那么这时候负责模型设计人员多半会手足无措。
提到这一个例子的目的是说明,因为神经网络内部本身的约束非常少,神经元的值可以在任意的取值区间,这使得神经网络只是被当做一个黑盒子去拟合输入输出,其内部的机制并不能够被大家所清晰地理解。因此,目前的神经网络往往并不是十全完美的解决方案,而需要改进结构的设计便于人们理解其内部的机制。
可解释性 (Interpretation)
可解释性的问题较早就有人提出来,有着不一样的叫法,比如 interpretable, explainable, intelligible, transparent 和 understandable,不一而足。
值得提到的是此处的可解释性与推荐系统的推荐理由或多或少有一些联系和细微的区别,本文提到的可解释性并不限于对于机器学习某个预测(某个特定 case)的理由,更多的理解为对这个模型的通用(general)的理解。无论何种理解,可解释性都与最终的性能关系并不紧密。
通常,可解释性是人们在机器学习模型中寻求的各种特征的代理。这些辅助的特征可能是公平性(Fairness,能否减轻各类偏见 bias?),可靠性(Reliability),因果(Causality,是一种相关性还是因果性?如分类哈士奇和狼是靠的两种类别之间的差异,还是由于背景带来的相关性),可信度(Trust,模型能够知道预测本身的置信度如何?)。
本文主要参考 Lipton 的说法 [2],主要解释为透明度 Transparency 和事后解释性 Post-hoc Explainability。
前者 Transparency 主要关心模型的运作机制和功能。这样方便人类去做检查,比如人工剔除模型的一些显著的弱点。一旦发现了 bad cases,人类有办法按照自己预期的目标,去干预和改变它的预测。在实时的应用中,数据可能包含比标注语料更多的噪音,所以透明性更加重要。
事后解释性通常在模型训练完成之后的马后炮解释。在模型训练之后,比如对一些组件做一些统计分析,像对 CNN 核的可视化,对机器翻译 attention 的可视化 [3][4]。
CNM复值匹配网络
值得注意的是,本文提到的可解释网络并非标准范式,本文作者给出一些新的神经网络范式,从新的角度去阐述可解释性。
本文提到的网络不同于多层感知机,卷积神经网络和循环或递归神经网络。从网络结构本身,可以理解为一个玩具(toy)网络(代码开源在 Github 上),因为目前它是一个较浅的神经网络,在结果本身并没有太大的竞争力,关注的是可解释性。
透明度和事后解释性解释为两个稍微具体一点的研究问题:
1. Transparency – 模型怎么工作的?网络由什么驱动来给出最终预测?
2. Post-hoc Explainability – 神经网络学到了什么?网络中每一层某个神经元的激活值大或者小意味着什么?
对于这两个问题,在本文的网络架构里姑且给出一个可能的思路就是:
1. 由量子概率来驱动网络来做出预测;
2. 将同一个希尔伯特空间的状态(state)来一统不同粒度的语言单元。包括可学习组件也将嵌入到与词语相同的希尔伯特空间,这样人们有机会去通过人类易于理解的语言单元(比如词级别)来诠释学习到的组件
动机
量子物理认为微观粒子可以同时处于不同的状态(量子叠加),这种有别于经典物理的常识,比如在没有观测之前,人们难以想象一个同时处于死了和或者的猫。不仅如此,一对纠缠粒子可以在相聚很远的时候,其中一个粒子的测量的结果可以影响到与之纠缠的另外一个粒子。
从量子物理发展来描述物理系统中的不确定的数学语言,是否对语言的形式化描述也有所裨益?这是本文关心的问题。在语言本身,词语存在一些不确定性,比如 apple 这个英文单词可以是一种水果,也可以一个生产 iPhone 和 Mac 的公司。如果把水果和生产 iPhone 和 Mac 的公司定义成基本语义单元,那么 apple 这个词就可以认为是这些基本语言单元的叠加态。
此外,词语与词语之间并不是完全独立的,有人做过一个词汇联想实验,有论文尝试将这种词汇联想可以用量子纠缠来解释 [5],更有相关的学者尝试用量子力学的数学框架来构建认知模型,比如霍金的导师 Penrose 推崇的量子大脑这类大胆想法(当然也招来大量批评)。
本文的出发点是受上述观点的启发,作者声称,量子力学去建模不确定的数学形式化是通用的(general),而且相对成熟,有潜力在建模语言的场景去尝试。在语言中的不确定性首先体现在单词级别的一次多义的场景里;次之,在语义组合的级别(意即如何组合多个词的意思成一个词组或者更大语义单元),也存在不同的组合方法。
用概率来驱动神经网络
通常对神经网络的批评来自于人们无法理解神经元到底有什么物理含义,当一个神经元的值变大或者变小对当前实例而言究竟是有什么意义。一个可行的方案是不在单独去看一个神经元,而是把神经元组成一个簇(可以参看 Capsule Network [6]),对神经元簇去做一个整体,每个神经元簇是一个向量,向量的方向表征着不同的特性,长度可以对应一些强度(或者说未经归一化前的概率)。
在量子的上下文下,将这一类的簇称之为状态。量子概率是一套基于投影几何的概率理论,可以看做是一个更加 general 的概率理论。这些所有的状态都是由一些基本基态组成的,这些基态被称之为不可分割且互不相关的语言基本单元(义原),形式化为一些 one-hot 向量。一个越加丰富复杂的语言体系,应有更多这样的 one-hot 向量。
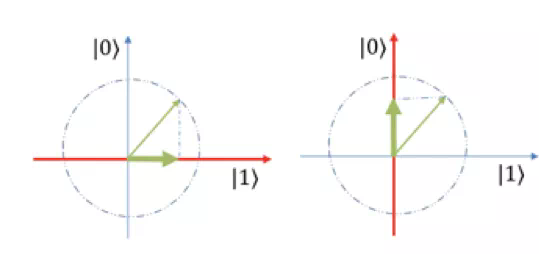
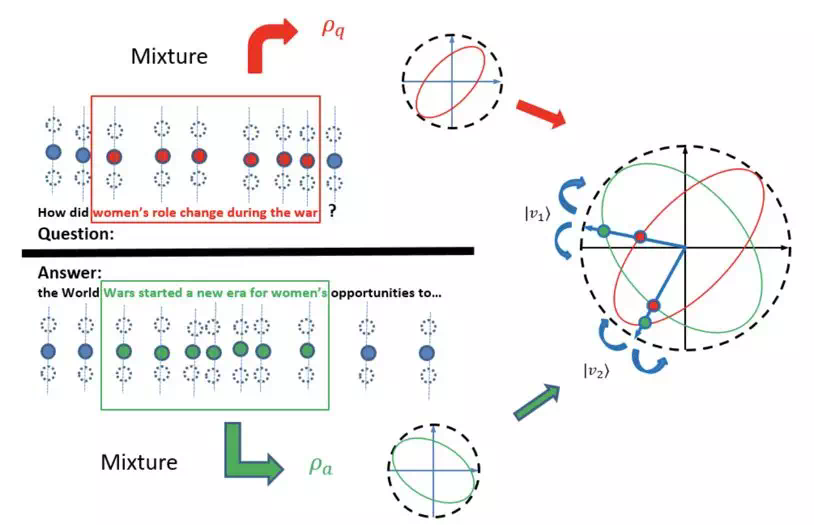
比如图中是一个简化的例子,比如某种原始的动物语言只有两个基本义原,比如 yes 和 no,分别对应于 |0> 和 |1>,分别是 one-hot 的向量 [1,0] 和 [0,1]。
在该动物的意识深处永远处于一种纠结的状态,它“汪”一声只能表示其中两种意思的混合状态,但是有着不同程度,有时候是非常想说 yes 但是只是有一点不情愿,有时候是想说 no,这种不确定性可以由投影来测量,测量长度的平方对应于概率。
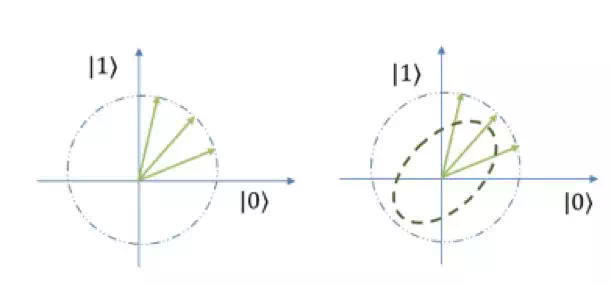
但是当把三个这样的原始动物聚在一起,每个动物都有着不情愿的程度,意即图中不同的处于叠加的状态。上帝问“今天愿意去祭祀吗?”(上帝的语言系统好像比大家都复杂丰富很多)。
这样三只动物就一起“汪汪汪”就一起叫了起来,上帝把它们的状态都往 (x 轴表示 yes)投影,然后对投影长度的平方求平均,就知道这些动物愿不愿意去祭祀的情况。
更有趣的是,上帝仗着自己语言系统比较丰富,突然玩起了花样,不再是问“愿意还是不愿”,上帝问“你们三个是不是都是半情愿半不情愿(50%-50%)”,然后把所有的状态朝着 x 轴正方向和 y 轴正方向之间的 45 度角方向投影,投影最后的结果照样把三个投影长度的平方平均一下就可以得到最后的结果。
所以再推而广之,那么对所有的方向都可以去做投影,最后的结果就类似图中的虚线椭圆(虚线与实线向量相接的点描述投影的长度,它的数学描述来自后文提到的密度矩阵)。
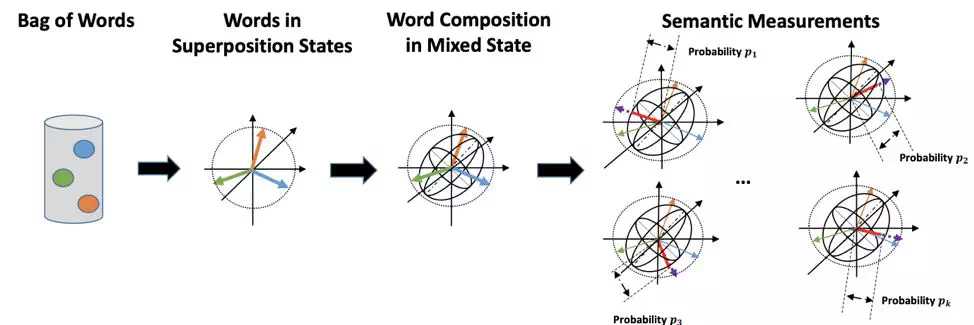
于是就把这样的基于投影几何的概率理论尝试搬到语言建模中来。单词被认为是纯的状态叠加态,就像图中的单位向量。很多单词一起的的混合系统就像图中三个动物一起的小集体,这样的小集体的概率描述是一个图中的虚线椭圆来描述(也就是密度矩阵),对混合系统的测量(就像上帝问的问题)的结果就呈现平均的结果。
如果选一组完备且正交的测量向量去测量这样的混合系统(实际上本文用数据驱动的方式去找一些更有判别力的测量向量),可以得到一组概率分布(即概率和为 1)。值得注意的是,所有状态都是单位的,而且这样的状态向量都是复数的。
希尔伯特空间一统不同粒度的语言单元
上文对量子概率有了一个简短的描述,为了方便大家接受,丢弃了几乎所有的数学形式化符号,全部同简单的投影几何的语言描述量子概率理论是如何在两维的空间运作。但是实际上语言本身应该是更复杂,所以这样互斥的基本语言单元的数量(也就是空间维度)的数量会更大,意即空间的维度更大。
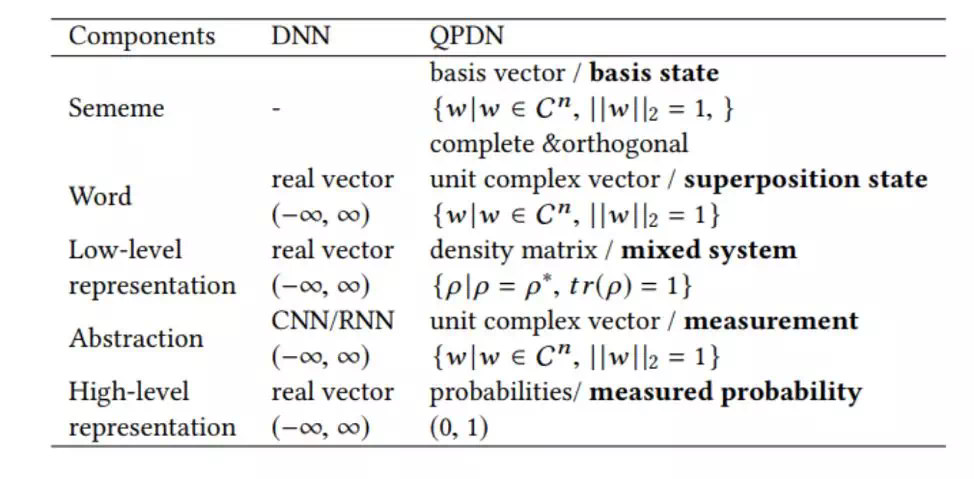
这样自然语言于物理形式化的语言的类比如下:
义原(不可分割的语言单元) <--> 基态
词 <--> 叠加态
词组/N-gran <--> 混合态
语义测量 <--> 投影算子 (投影方向对应于网络里面任意的一个叠加态)
句子 <--> 和投影算子一一对应的一组概率值
所有一些对应的内容均是有着良好的归一化和数学约束,如下表所示:
几乎每一个组建都有着相对较好的约束的定义,与之对应的好处是,在整个神经网络中出现的神经元要么是一个单位状态的一个元素,抑或是概率值。
语义匹配
文本匹配是自然语言处理和信息检索很常见的任务,目标是匹配两个对象。源对象和目标对象可以是查询和文档,问题和答案,假设和推论,以及对话系统里两个 utterance。通常的做法是先对两个文本对象构建一个对称的表示层,然后再在得到两个表示上做一个交互层。
如图所示,词就像粒子一样(同时处于不同的位置,有一个波函数来描述它出现的不同地方的概率,但是义原是离散的,所以它实际上是一个离散的概率分布来描述),被认为是嵌入在希尔伯特空间的一个状态,也就是一个复数的单位状态向量,一个在基本语义单元空间的复值权重的线性叠加(对应在基本语义单元的一个概率分布)。
与 CNN 类似,本文用滑动窗口来对一些列 N-gram 来构建一个混合系统,这样混合系统的的概率属性由一个密度矩阵来描述。本文模型将需要匹配的两个文本对象各自的 N-gram 同时向一个投影平面投影,投影的长度的平方对应混合系统投影到该投影平面的概率。
根据投影长度来判断两个文本对象是否匹配。如果两个文本对象是匹配(比如该答案对应正确的问题),希望找到一些投影方向让两个密度矩阵投影后的长度相近;反之希望投影长度相差更大。
因为投影平面是由一个向量张成的子空间,该投影向量跟词语同时嵌入在同一个希尔伯特空间,所以可以通过最靠近该投影向量的词向量来理解投影向量可能蕴含的含义。
选取了其中五个投影向量,将起最近的五个词展示出来。由图中学到的测量向量的含义可以通过词语来描述。如下图:
复值语义组合
将词向量相加来表示句子一个非常常见的做法,在一些文本分类的任务中,直接对文本的所有词的词向量平均然后接一个全联接层就可以得到不错的结果。但是这种直接加法是一种粗糙的做法,因为其有一个非常强的假设,那就是由词组成的词组/句子/文档的含义是由其包含的词线性相加得到的。
一个简单例子“artificial intelligence”的含义就是像人一样工作的智能,基本可以由两个词的含义的线性叠加。另外一个例子是“ivory tower”的组合起来的意思,并不是一个由象牙做成的塔,而是心无旁骛追求自己目标(通常为智慧方面)的乐土,这样一个组合起来的意思并不能由象牙和塔的直接线性叠加。
复值(形如 z=a+bi 或者 z=r(cos θ+i sin θ))的表示可以隐式地表达更加丰富的语义组合。与传统的实值词向量相比,本文词向量是由复值向量。每一个复数由一个实部和虚部组成,可将其转换成振幅和相位的形式,振幅 (r) 对应经典的传统的实数词向量的值,而相位 (θ) 可能表征一些高阶的语义。
当对两个复数相加时,不是直接对振幅进行相加,同时会考虑它们的相位信息,有的时候振幅相加会得到增益的效果,有时候可以得到相消的结果。这时候相位就像一种经典的门的机制,它能够控制如何让两种信息源如何融合起来。在组合大粒度语义单元时,这样额外的相位(作为一个种门机制)可以有潜力隐式建模非线性的语义组合。
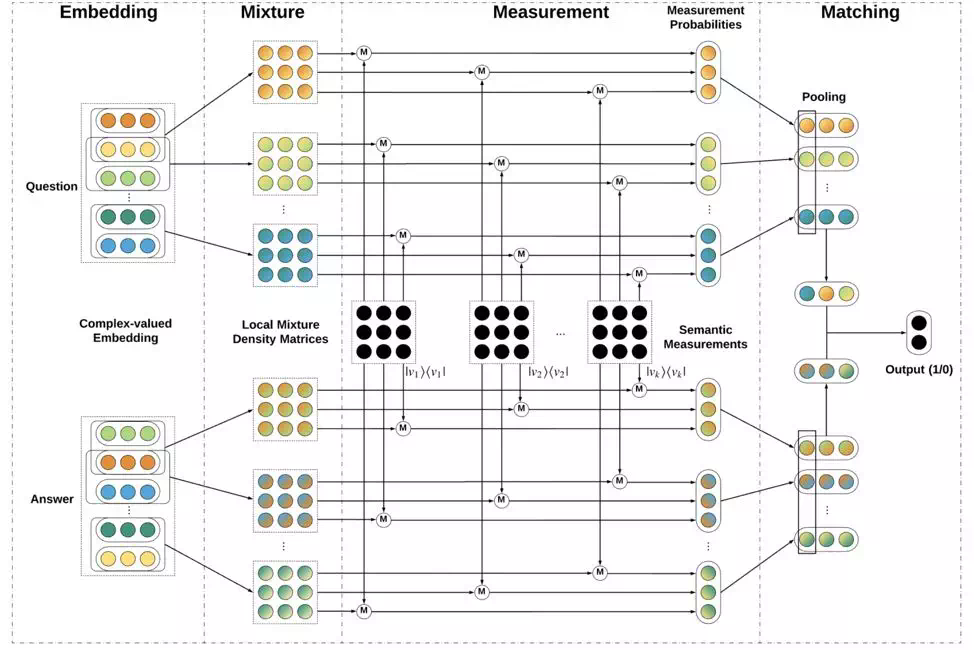
网络的结构
网络的结构跟上文形式化建模一致,模型不涉及显式的全联接层,不包含卷积网络,不包循环或递归的神经网络单元。
本文模型用滑动的窗口构建两个文本对象的 N-gram 的密度矩阵表示,然后采用一组测量投影操作,同时测量两个文本对象所有的 n-gram 窗口里的混合系统(由密度矩阵描述)。最后通过一组 max pooling 操作得到每个测量向量在所有 n-gram 最大的投影概率,最后通过向量的 cosine 距离得到匹配的分数。
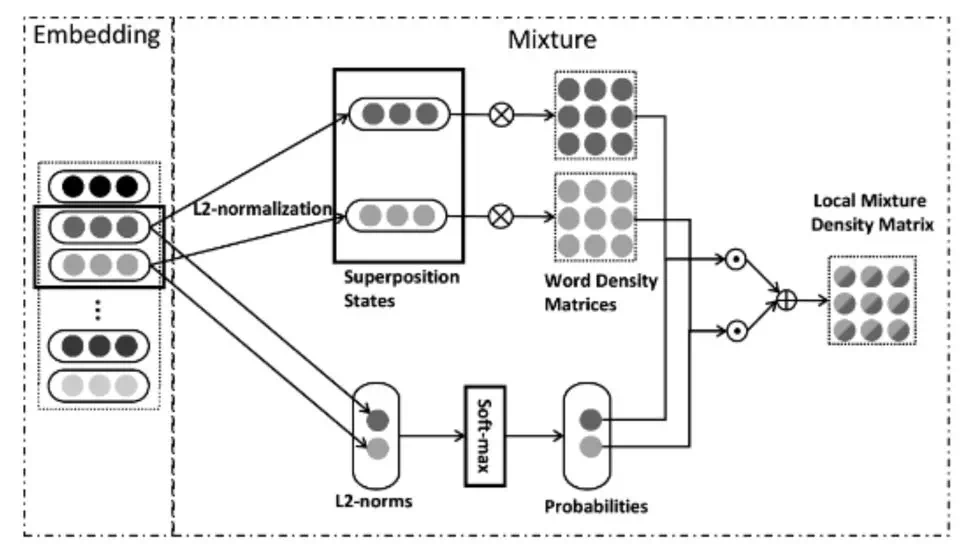
其中自底向上构建密度矩阵的操作,也就是从 embedding 层到 mixture 层的做法如下(叉操作是外积/张量积,点操作是一个标量乘以矩阵的每一个元素,加操作是矩阵点对点加法):
首先对选取的一个 N-gram 窗口,对其中每一个词向量用 l2-norm 归一化(也就是直接除以它的长度),然后计算该归一化向量与其共轭转置的外积(外积操作,如 x=[a,b], 外积是一个 22 的矩阵为 x=[[aa†,ab†],[a†b,bb†]] 大家常见的内积操作的结果是一个标量 ab†,† 是共轭转置)。
由于向量经过了归一化,得到的外积矩阵有着良好的性质,对角线元素是实数且和为 1,非对角线元素是复数。然后把所有外积矩阵加权起来得到的是一个密度矩阵,权重是由词向量的模经过 softmax 得到的一组和为 1 的向量,所以也能保证密度矩阵也是单位的(对角线元素和为 1)。其中一个好处是对网络对不同的词有着显式的权重,这样权重依赖于局部的上下文。
对于这样一个的一个对词向量本身的外积,在机器学习领域也是比较常见的操作,类似于推荐系统里面的特征交叉。对一个词而言,其特征是其词向量的每一个元素
,传统的神经网络的假设空间简化为
,采取外积操作后的矩阵相当于构造了一个二阶的特征交叉矩阵作为新的特征,新的假设空间为 。
与本文自底向上构建密度矩阵不同的是,也可以通过最大似然估计来得到密度矩阵,这类的方法最出名的当属发表在 2013 年 SIGIR 的 Alessandro Sordoni,Jianyun Nie 和 Yoshua Bengio 的量子语言模型 [7],本文自底向上构建密度矩阵是能够轻量地直接结合在神经网络里面。
Case Study
基于一个局部窗口构建基于词袋模型的密度矩阵表示,对于下列的 case 显得更加有效。
文句和答句同时包含来某个实体(president of chief executive of Amtrak 与 Amtrak’spresident and chief executive),但是它们的顺序有可能有一些颠倒,其中颠倒的本身会有一些词的变化,比如从 of 变成 ’s。
密度矩阵在一个 local 的窗口内是位置不敏感的,所以可以处理 Amtrak 与 president/chief executive 的交换的情况;而且有着显式的词权重建模,of 与 ’s 之类的词由于本身词频高,可以与很多词同时出现,假想其应该有更小的权重(实验结果基本支持该假想)。
第二个例子是一个稍难一点的例子,因为两个需要匹配的两个文本片段,包含有一些不重叠的词。这类匹配例子寄希望于词向量的软匹配能力。
结果
实验结果取得与一些经典模型可比较的结果。由于评测的数据集相对比较小,在结果上提供的贡献比较有限。相比较 CNN 和 RNN,本文模型相对较浅且参数有限,贡献更多是体现提供一个新的视角来看待神经网络。
代码已经开源见:https://github.com/wabyking/qnn
展望
短期看,暴力拟合数据会取得更好的结果。最近伯克利的研究人员声称,儿童只需要 18M 的存储空间来掌握它们的母语 [10],整个社区还有很长的路要走。大数据大模型的红利总有一天会吃完,未来人们不得不去摘取高枝上的果实,啃难啃的骨头。
长期看,社区或许能从数学或者物理的角度来理解和分析深度学习中受益,或者结合语言特性本身,来设计一些具有较强动机(而不是完全从经验结果出发)的模型和方法。
当然实现这样长期的一些目标,也需要行业内的科研和工程从业人员对一些有好的思路和想法有更多的宽容,在一个宽松的环境不再要求所有的论文的方法都去追求 the state of art;在一个良好设置的基准线上能够验证论文本身的观点(即便是 toy model),就应该是科学的论文;刷榜固不可少,小清新也别有风味。
一个有潜力的物理启发的研究方向是从当前的一个低维的角度朝向指数高维度的张量空间,某些传统神经网络,被认为是对应于特定假设空间里高维参数张量的分解。例如单层 CNN 被认为对应于 CP 分解;某种特定设置下的多层 CNN 对应于层次化Tucker分解 [8];RNN 则与张量链分解(Tensor Train Decomposition)有关 [9]。
通过分析不同张量分解模型来理解其能近似的张量的秩(rank)能够很好地了解神经网络的表达能力。不仅如此,基于高维张量空间的视角,有很大的潜力去指导设计神经网络结构。
参考文献
[1] Ribeiro, Marco Tulio, Sameer Singh, and Carlos Guestrin. "Why should i trust you?: Explaining the predictions of any classifier." Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining. ACM, 2016.
[2] Lipton, Zachary C. "The Mythos of Model Interpretability." Queue 16.3 (2018): 30.
[3] Zeiler, Matthew D., and Rob Fergus. "Visualizing and understanding convolutional networks." European conference on computer vision. springer, Cham, 2014.
[4] Ding, Yanzhuo, et al. "Visualizing and understanding neural machine translation." Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2017.
[5] Bruza, Peter, et al. "Is there something quantum-like about the human mental lexicon?." Journal of Mathematical Psychology53.5 (2009): 362-377.
[6] Sabour, Sara, Nicholas Frosst, and Geoffrey E. Hinton. "Dynamic routing between capsules." Advances in neural information processing systems. 2017.
[7] Sordoni, Alessandro, Jian-Yun Nie, and Yoshua Bengio. "Modeling term dependencies with quantum language models for IR." Proceedings of the 36th international ACM SIGIR conference on Research and development in information retrieval. ACM, 2013.
[8] Cohen, Nadav, Or Sharir, and Amnon Shashua. "On the expressive power of deep learning: A tensor analysis." Conference on Learning Theory. 2016.
[9] Khrulkov, Valentin, Alexander Novikov, and Ivan Oseledets. "Expressive power of recurrent neural networks." arXiv preprint arXiv:1711.00811 (2017).
[10] https://news.berkeley.edu/2019/03/27/younglanguagelearners/
Share Http URL: http://www.wittx.cn/get_news_message.do?new_id=230

Best Last Month

Information industry by wittx

Information industry by wittx
Information industry by wittxCoCa: Contrastive Captioners are Image-Text Foundation Models
Information industry by wittx

Information industry by wittx
Information industry by wittx
Information industry by wittx

Information industry by wittx
Information industry by wittx
Information industry by wittx