研究者在 GRIDWORLD 和 AI2-THOR 上进行了大量实验,结果表明新提出的模型可以有效地在 400 个(Env, Task)组合之间成功迁移,而模型的训练只需要这些组合的大概 40%。
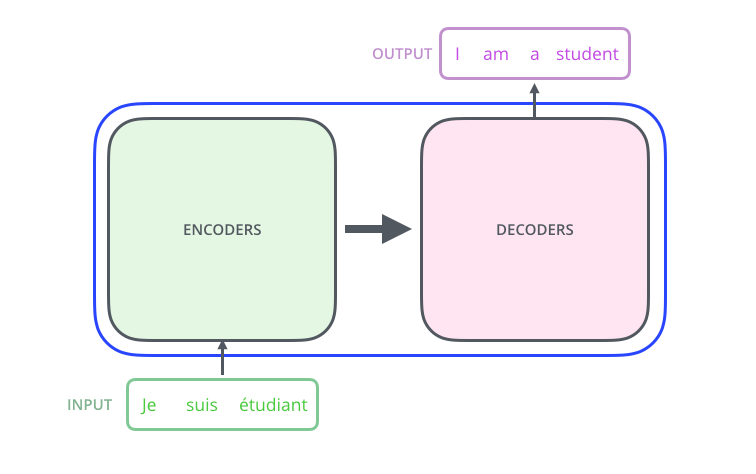
方法简介
传统的强化学习在同一个环境下试图解决同一个任务——比如 AlphaGo,我们希望把这种受限情况下的进展推广到更一般的情况:多个环境(比如不同的迷宫),多个任务(比如逃离迷宫、找到宝藏、收集金币等不同任务)。
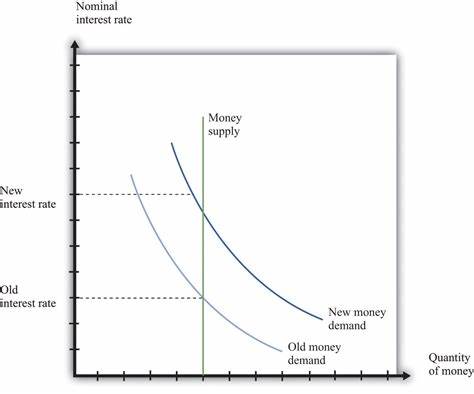
如上图所示,红色代表训练阶段见到的环境与任务组合,灰色代表只在测试阶段才会见到的组合:
(a)是最简单的情况,尽管有一些组合在训练阶段没见过,但是每个环境(同理,每个任务)都在训练的时候出现过;
(b)相对复杂一些,在测试阶段出现的新的组合里面,或者任务是新的——训练时候没有见过,或者环境是新的;
(c)是最复杂的情况,在测试阶段出现的新组合里面,任务和环境都是以前没有见过的。
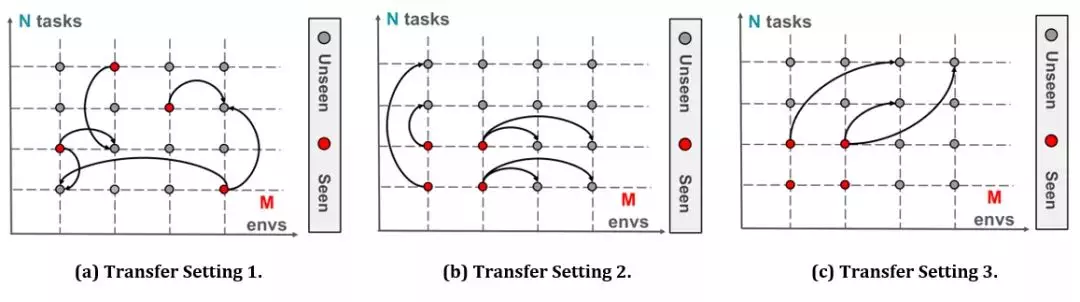
我们提出一个统一的框架来解决上述三个问题,这个框架的关键在于同时学习环境和任务的描述子以及如何从这些描述子构建规则。
我们的基本假设是规则的构建方式对于不同的(环境、任务)组合是相通的:于是,当智能体在测试阶段给定了新的(环境、任务)组合时,针对(a)它可以利用以前学习到的描述子构建相应的规则;针对(b)和(c),也就是存在新的以前没见过的环境或/和任务,我们允许智能体做少量的交互来快速学习描述子——一旦环境和任务描述子学习完成,它就可以构建规则,不需要像传统的强化学习那样重新学习规则。
具体来说,我们提出的框架如下:
虽然上述框架具备了我们要求的同时学习规则以及环境与任务描述子的功能,但是在学习阶段有一个陷阱:很可能,规则和描述子会耦合在一起,使得智能体在见到的(环境、任务)组合上表现很好,但是没办法在测试阶段处理新的组合。
为了解决这个问题,就需要把规则构建方式和描述子解耦,使得描述子确实可以有效描述和区分不同的环境与任务,同时又能帮助构建有效的规则。相对应的,在训练的时候,除去传统的用于完成任务的奖励函数,我们还加上针对描述子特有的用于分类的奖励函数——基于描述子的状态描述应该能成功区分不同环境和任务。
实验设定
我们分别在走迷宫和室内导航上进行了实验。以下主要描述走迷宫;关于室内导航的实验请见论文。
如下图所示,我们假定智能体在迷宫中行走的时候,视野范围只有 3 x 3。

实验结果
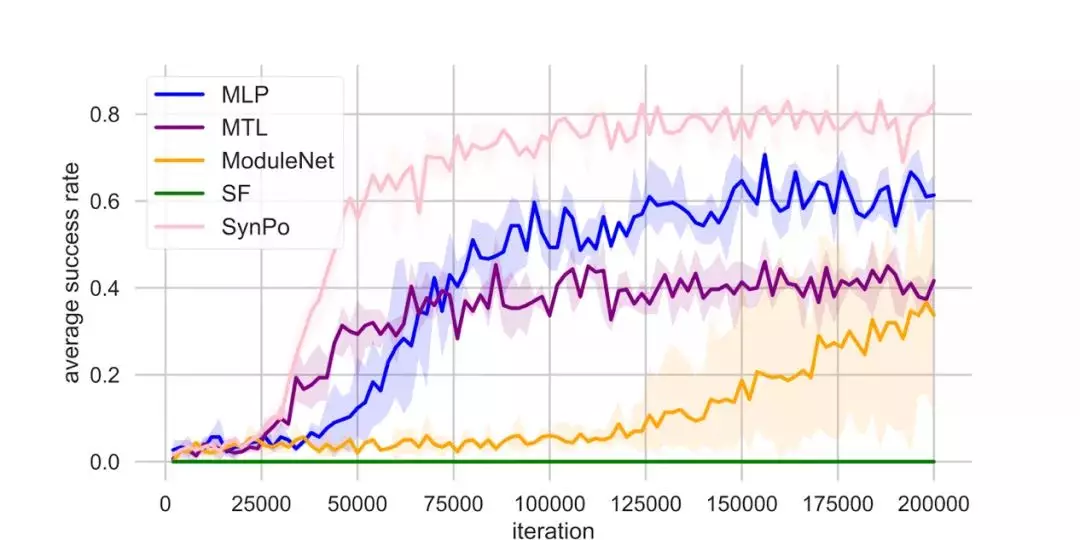
如下图所示,我们的方法(SynPo)成功的超过了最近提出的几个方法,包括多任务神经网络(MTL),模块化神经网络(ModuleNet),专门用于迁移学习的 SF,还有一个我们自己方法的简化版(MLP)。
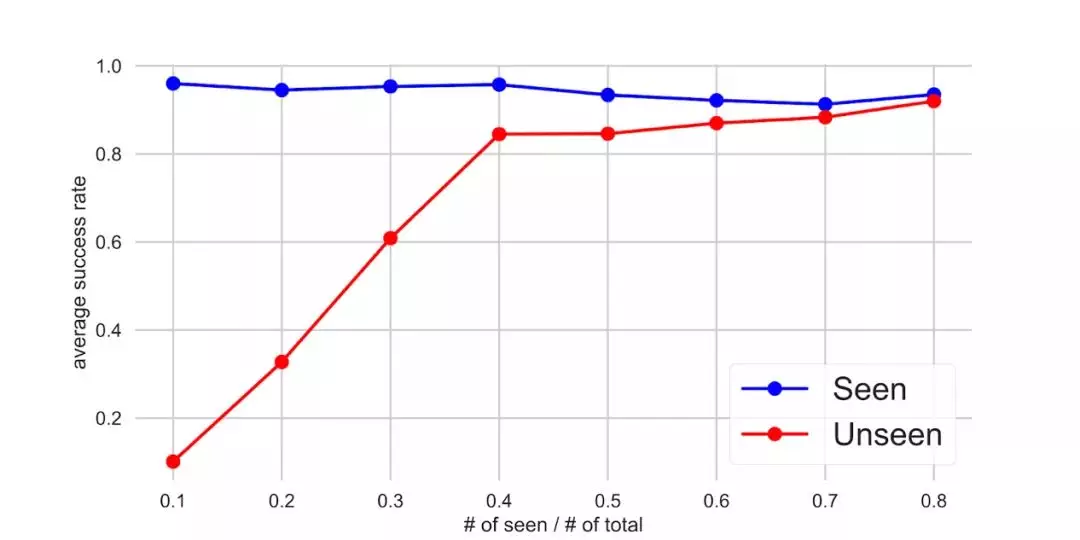
另外,我们也分别研究了智能体在见过和没见过的(环境、任务)组合上的表现。如下图所示,对于智能体在训练阶段见过的组合,它在测试阶段始终表现不错;对于没见过的组合,它只需要在 40% 的组合上学习,就能达到很好的效果。
最后,我们给出在 10 个环境和 10 个任务组合上训练,然后在 20 个环境和 20 个任务上做测试的结果。如下图所示,每一行代表一个任务,每一列代表一个环境,其中左上角的 10 个环境和任务是用于训练的。
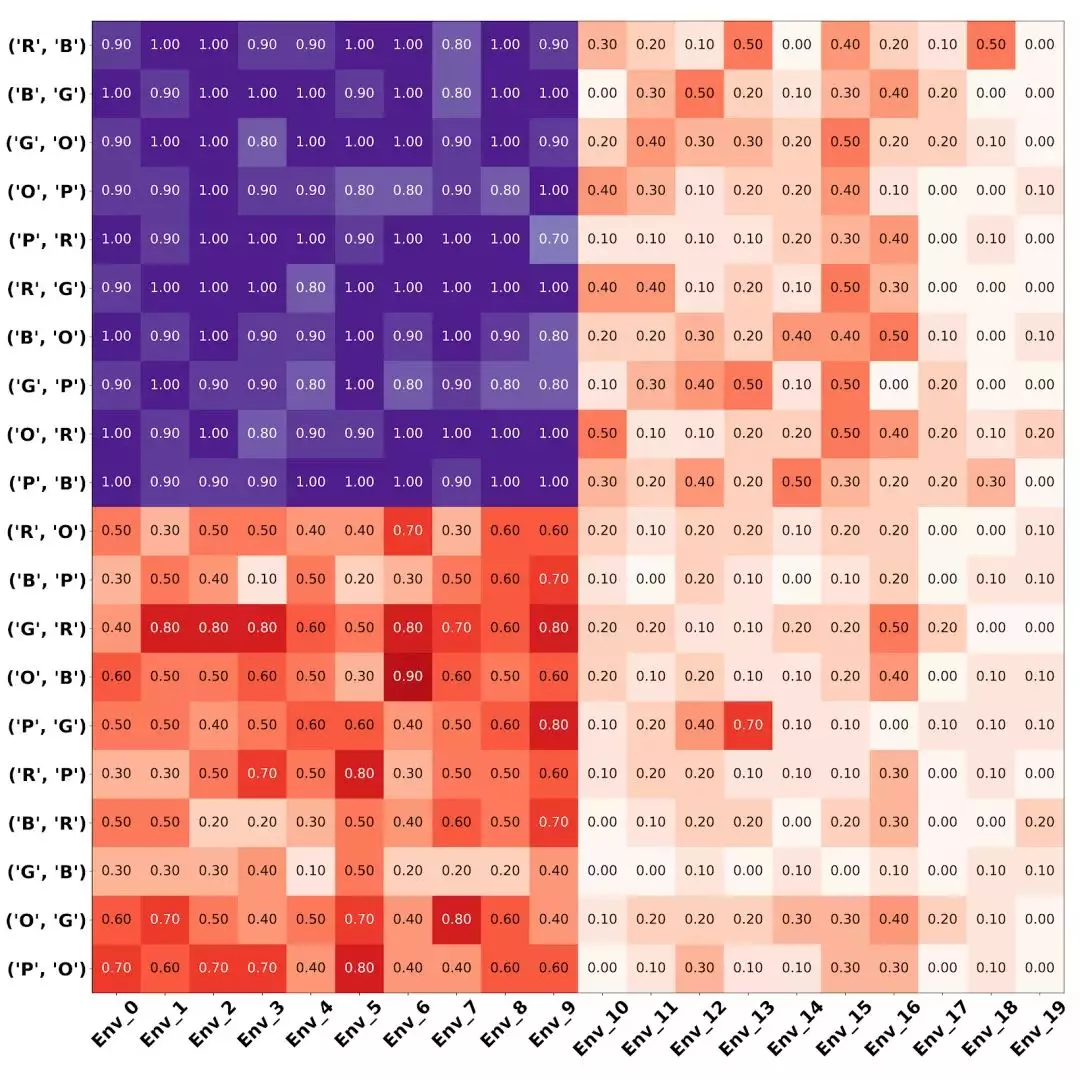
测试阶段,为了拓展到新的环境(右上角),我们允许智能体和环境做少量交互,用于得到环境的描述子,然后构建规则;为了拓展到新的任务(左下角),我们如法炮制,得到任务的描述子。
得到所有描述子以后,我们就可以构建针对任意组合的规则了。在相应规则指导下,智能体完成任务的表现如上图,深色代表高成功率,浅色代表低成功率。我们可以看到向新的任务迁移比向新的环境迁移容易一些,而两者都是以前未见的时候,迁移是最难的。





.jpg)