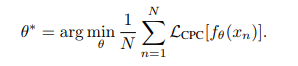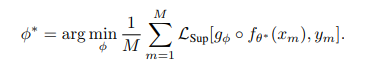-
News Message
DeepMind新半监督模型超越AlexNet
- by wittx 2019-06-18
.jpeg)
DeepMind 近期的一项研究利用对比预测编码(Contrastive Predictive Coding,CPC)来解决这一难题,该方法是一种从静止图像中抽取稳定结构的无监督方法。得到的结果是一种表征,使用该表征和简单的线性分类器在 ImageNet 上可实现优于其他方法的分类准确率,性能超越全监督 AlexNet 模型。即使给出少量标注图像(每个类别 13 张标注图像),该表征也能保持强大的分类性能,Top-5 准确率超出当前最优的半监督方法 10%,超出当前最优监督方法 20%。
此外,研究发现,该无监督表征可作为有效组件用于在 PASCAL-VOC 2007 数据集上的图像检测任务,且性能堪比使用全标注 ImageNet 数据集训练得到的表征。研究人员表示,希望该研究可以帮助在缺乏标注数据的现实视觉任务中,使用无监督表征来替代监督表征。
主要贡献
具体而言,DeepMind 的这项研究改进了 CPC 模型 [49],并基于此提出一种相对直接的方法。首先,研究人员对 CPC 进行架构优化,使其特征编码器扩展为较大的网络,便于从无标注数据中提取更有用的信息,从而得到可以提高图像分类准确率的特征。具体来看,他们基于这些表征训练的线性分类器在 ImageNet 上的 Top-1 准确率和 Top-5 准确率均优于全监督 AlexNet [37]。
其次,研究人员尝试使用该表征进行基于少量标签(标注数据仅为 ImageNet 数据集的 1%)的分类。在该设置下,DeepMind 提出的半监督方法的 Top-5 准确率比当前最优监督方法高出 20%,比当前最优半监督方法高出 10%。与之前的半监督结果不同,该方法在标注样本增加的情况下仍能保持强大性能,在使用完整 ImageNet 训练集时,其性能堪比全监督性能,这表明该方法学得的特征可以迁移到在线学习环境中。
第三,DeepMind 研究人员探索了该表征的迁移学习能力。使用该无监督表征作为特征提取器在 PASCAL 2007 数据集上执行图像检测任务,得到的性能超越其他自监督迁移方法。重点是,这一性能结果接近专为监督迁移学习构建的方法。
最后,研究人员探索了不同的半监督学习方法,发现标准端到端精调方法并不一定是最优的。该研究发现,CPC 特征可在未经重训练的情况下使用,基于固定特征训练深度网络。该方法的性能堪比精调后的模型性能,且其计算成本大大减少。这个结果很有意思,因为它复刻了自然语言处理领域的结果,NLP 领域中无监督特征(如 word2vec [42] 和 BERT [13])可在未经重新训练的情况下在多个任务中取得强大性能,从而简化训练流程、减少计算成本。
什么是对比预测编码
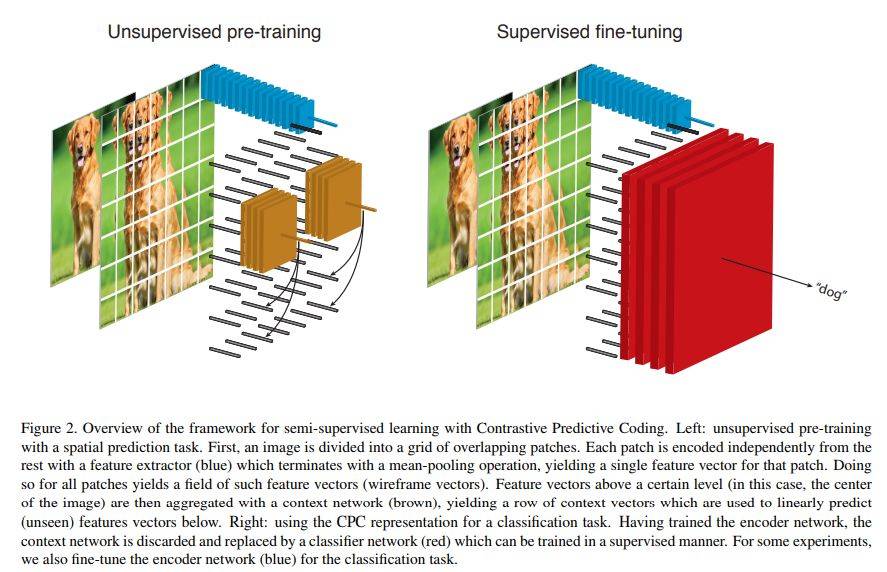
对比预测编码(CPC)是一种自监督方法,它基于之前观测结果的表征预测未来观测结果的表征,从而从序列数据中学习。当应用到图像数据时,CPC 基于特定级别以上的图像块表征预测该级别以下的图像块表征(如图 2 所示)。然后使用对比损失(contrastive loss)评估这些预测,在这一过程中网络必须从一组无关的「负」表征中正确分类出「未来」表征。这避免了无效解,如用常数向量表示所有图像块(在使用均方误差损失时会出现这种情况)。
图 2:使用 CPC 进行半监督学习的框架图。左:使用无监督预训练执行空间预测任务。右:使用 CPC 表征执行分类任务。
方法详解
利用 CPC 进行无监督学习
最近的研究表明,增加网络容量和训练规模可以提高性能。DeepMind 研究人员对现有 CPC 算法的第一个改进就是将网络扩大。CPC 原来使用 ResNet-101-style 架构来表示每个图像块,他们则为该任务开发了一个更深、更广的 ResNet。
然而,大型架构更加难以高效训练。由于 CPC 必须在图像块上进行,这一问题变得更加严重。早期关于图像块语境预测的工作利用批归一化来提高训练速度。但 DeepMind 研究人员发现,对于大型架构来说,利用批归一化得到的性能比较差。于是,他们利用层归一化来弥补批归一化的训练效率。
有了更加高效、高容量的架构之后,研究者开发了一个有挑战性的任务来对其进行训练。他们首先通过向上预测(即对空间位置较低的图像块进行聚合以预测空间位置较高图像块的表征)和向下预测(CPC 最初只使用向下预测)来加倍每张图像中的监督信号。这两种方向的预测使用不同的语境网络。研究人员发现,额外的图像块增强可以带来显著的性能提升。首先,他们利用了 [14] 中的「color dropping」方法,该方法在每个图像块中随机丢弃三个颜色通道的两个。他们随机对图像块进行水平翻转。他们还随机将一个完整的图像块裁剪为 56x56 大小的多个图像块,并将它们重新拼为原来的大小,从而在空间上对其进行抖动。
增加任务的复杂度之后,CPC 的目标变得非常困难,即使对于如此高容量的模型来说也是如此。在实践中,研究者发现增加任务难度竟然提高(而不是降低)了模型在下游任务中的性能。实际上,如果网络可以学习利用低级图案(如变化缓慢的颜色,或图像块之间的连续直线)来完成任务,那么该网络就无需学习任何语义上有意义的语境。通过增加图像块之间的低级可变性,研究者移除了这些低级特征,同时也加大了任务难度,迫使网络通过抽取高级特征来解决问题。
利用 CPC 进行半监督学习
研究者探索了两种方式来将 CPC 与有监督分类任务结合在一起。第一种固定范式包括专为 CPC 优化一个特征提取器 f_θ。然后固定其参数并优化分类器 g_φ,以区分上述特征提取器的输出。从公式上来说,给定一个含有 N 张图像的数据集 {x_n},得到:
给定一个含有 M 张标注图像的数据集 {x_m, y_m}(这个数据集可能要小得多),得到:
研究者还探索了一种微调机制,这种机制允许特征提取器适应有监督目标。确切点说,研究者利用在上述学习阶段得出的解 θ^∗ 和 φ^∗ 初始化特征提取器和分类器,并为有监督目标微调整个网络。为了确保特征提取器不偏离 CPC 指定的解太多,研究者应用了更小的学习率和早停。
但 CPC 要求特征提取器 f^θ 独立应用在叠加的图像块上,在半监督学习阶段,它可以直接应用在整个图像上。这将整体计算量减少了 2/3-3/4,因此可以加速训练并减少内存占用。为了减小图像块上的无监督学习与整幅图像上的监督微调之间的域不匹配,研究者在所有的卷积中使用了对称填充,并在无监督预训练过程中使用了空间抖动。
针对图像分类任务对模型进行训练时,分类器 g^φ 是一个 11-block ResNet 架构,拥有 4096 维特征图和 1024 维瓶颈层。监督损失函数 L_Sup 是模型预测和图像标签之间的交叉熵。当对模型进行图像检测训练时,研究者使用了 Faster-RCNN 架构和损失函数,没有做任何修改。
实验
在 ImageNet 上的分类性能
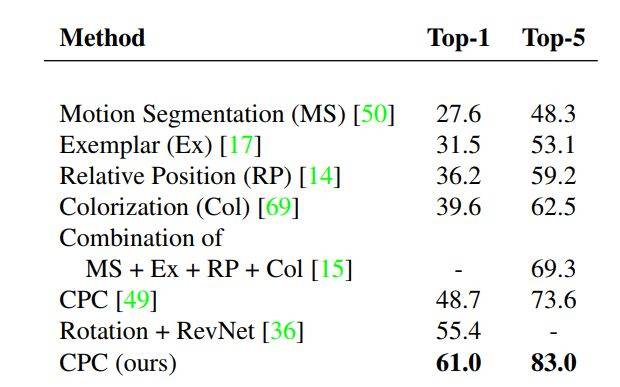
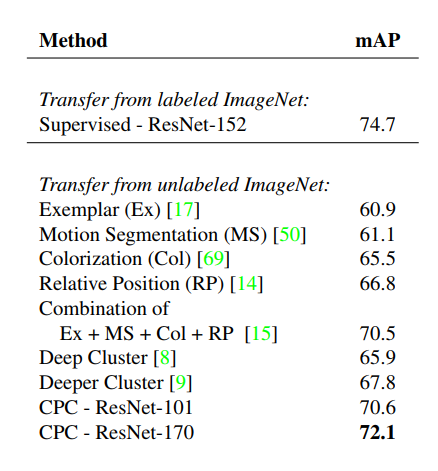
该研究首先探索了该模型线性分割图像类别的能力,这是无监督表征学习的标准基准测试。实验结果表明,改进版的 CPC 架构性能显著超过之前公开方法的性能结果,如下表 1 所示:
表 1:该研究提出的方法与其他自监督方法的线性分割能力对比。在所有实验中,特征提取器都以无监督的方式进行优化,线性分类器使用 ImageNet 数据集中的所有标签进行训练。
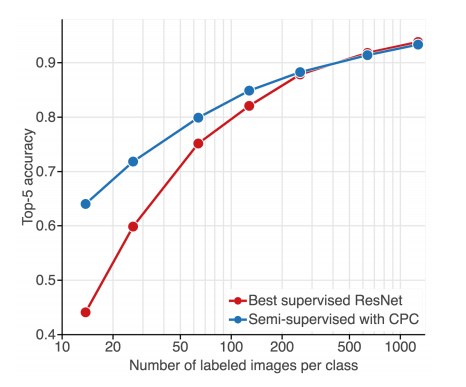
接着,研究人员在 ImageNet 数据集上评估全监督网络在具备不同数量标注训练数据时的性能。
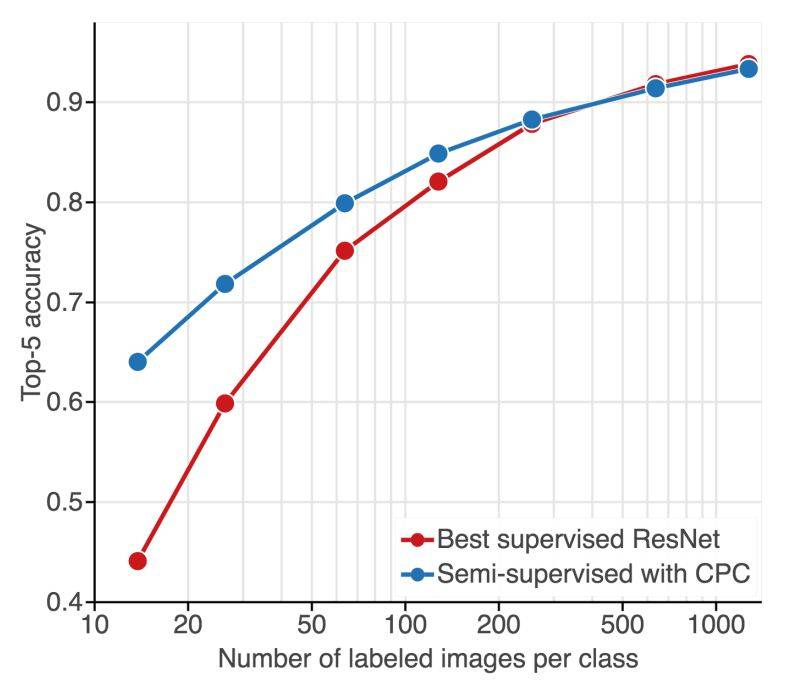
图 1:分类准确率 vs. 标注样本数量。监督方法(红色线)的性能随着标注数据数量下降而急剧下滑;使用大量无标注样本(蓝色线)对这些方法进行正则化可以极大地缓解性能的下降。
如图 1 所示,随着数据量下降,全监督模型过拟合愈发严重。尽管研究者相应地提升了正则化,但该模型的性能从 93.83% 的准确率下降到了 44.10%(前者是在整个数据集上进行训练的结果,后者是在 1% 的数据上进行训练的结果,见图 1 和图 3 的红线)。
最后,研究者对比了他们提出的方法和全监督基线模型。研究者在整个无标注 ImageNet 数据集上预训练特征提取器,学习分类器,并使用标注图像的子集进行模型精调。图 1 和图 3 中的蓝线展示了该方法的结果。
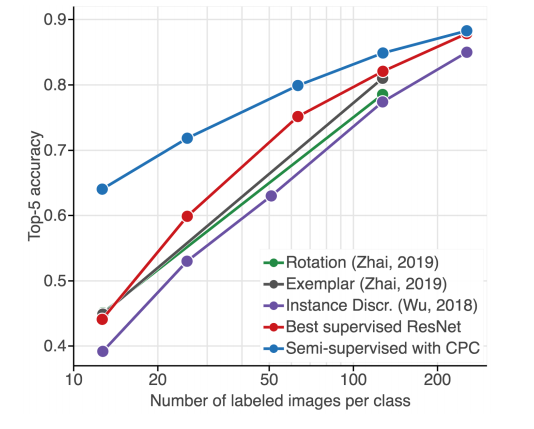
之后,研究者对比了他们提出的方法和其他半监督学习方法。下图 3 展示了这些方法没能显著改善基线监督模型,CPC 方法是唯一超过监督学习模型的方法。
图 3:该研究提出方法与使用自监督学习和监督精调模型的半监督学习方法的对比。蓝色线:使用 CPC 的半监督学习。紫色线:使用 instance discrimination 的半监督学习 [64]。绿色线:使用 rotation prediction 的半监督学习 [68]。灰色线:使用 exemplar learning 的半监督学习。红色线:监督基线方法。
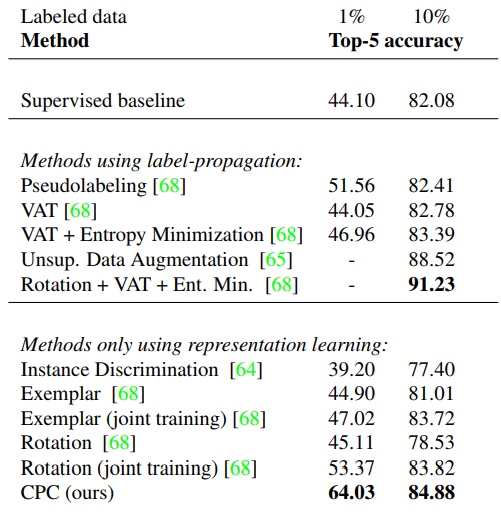
表 2:在使用 1% 或 10% 标注数据时的半监督学习方法性能对比。表征学习方法以无监督方式学习表征,并将表征用于分类。分类器仅考虑标注样本,且仅局限于监督式方法。
迁移到 PASCAL 后的图像检测性能
有用的无监督学习方法所训练的表征可以很好地迁移到新数据集和任务。为了调查 CPC 所学表征是否具备该能力,研究人员在 PASCAL 数据集上评估其图像检测性能。下表 3 展示了该方法与其他方法的对比结果:
表 3:在 PASCAL 2007 数据集上执行图像检测任务时,不同迁移方法的性能对比结果。第一类模型从无标注 ImageNet 数据中学习,并针对 PASCAL 图像检测任务进行精调。第二类模型在迁移之前先基于整个标注 ImageNet 数据集学习。所有结果均以 mAP 来衡量。
参考链接:https://arxiv.org/pdf/1905.09272.pdf
Share Http URL: http://www.wittx.cn/get_news_message.do?new_id=225

Best Last Month
Information industry by show
Information industry by wittx
Information industry by wittx

Information industry by wittx

Information industry by wittx
Information industry by wittx

Information industry by wittx

Information industry by wittx
Information industry by 未注册用户发布
Information industry by wittx