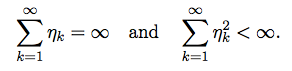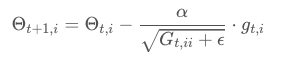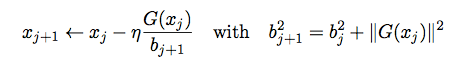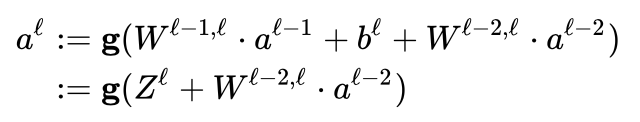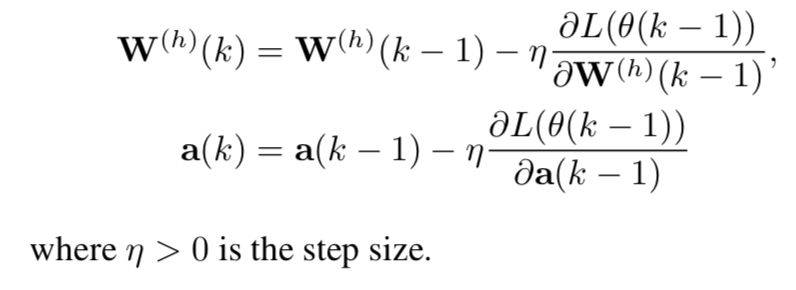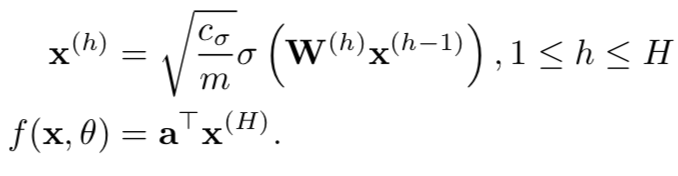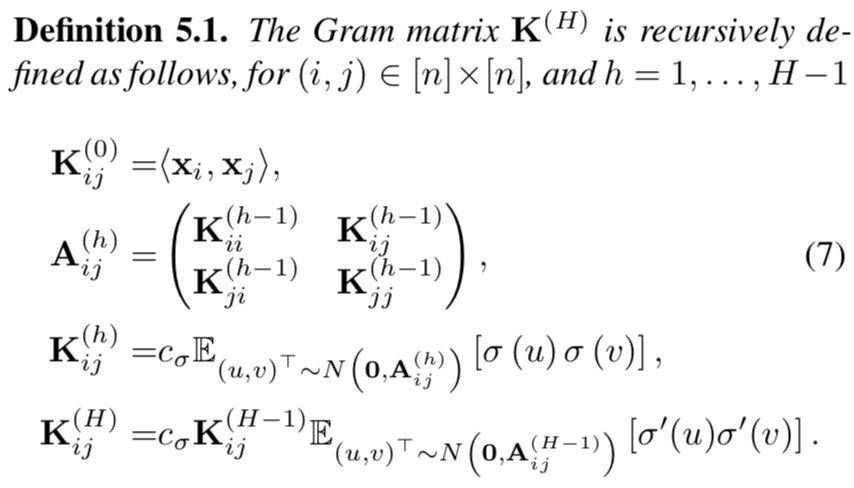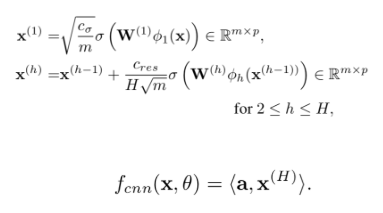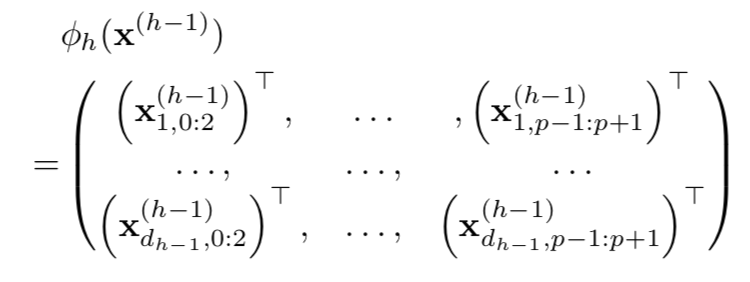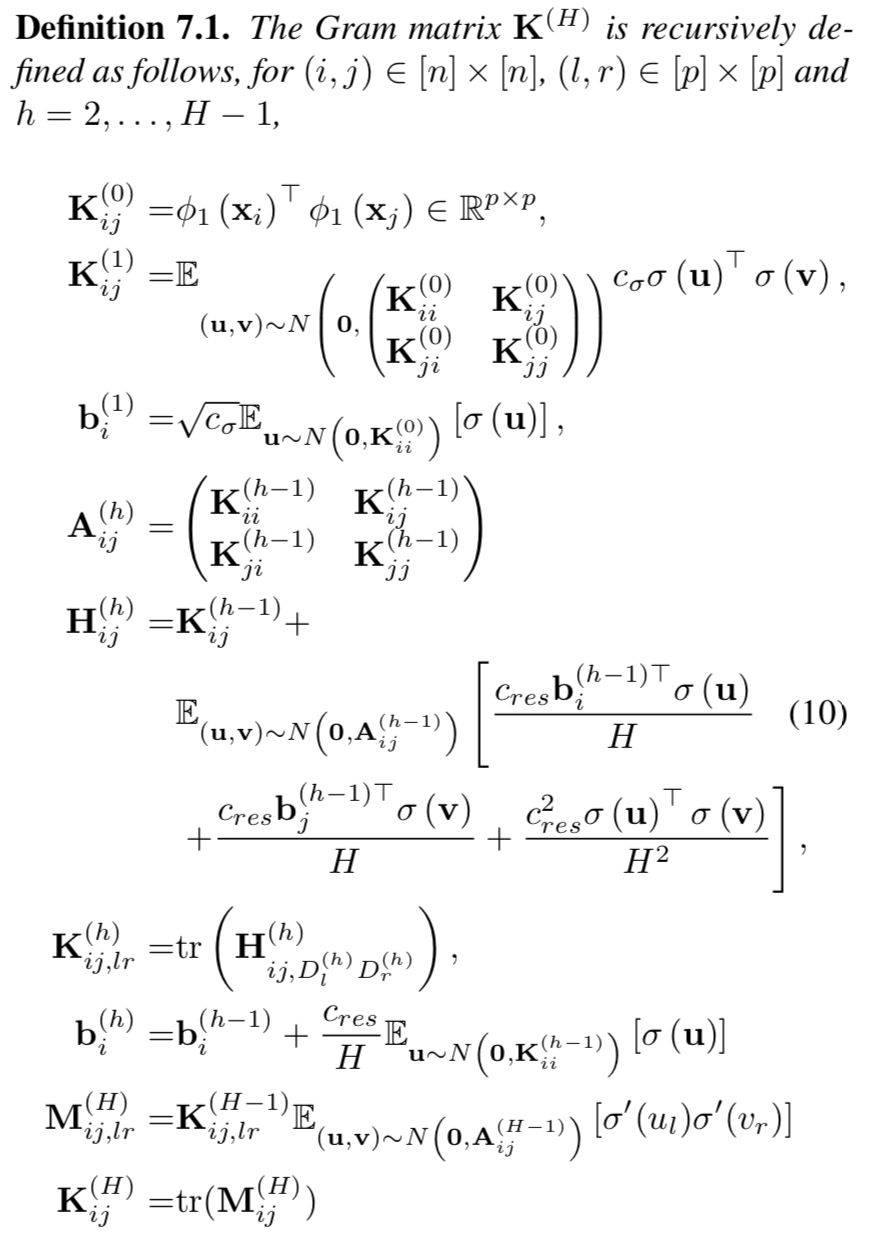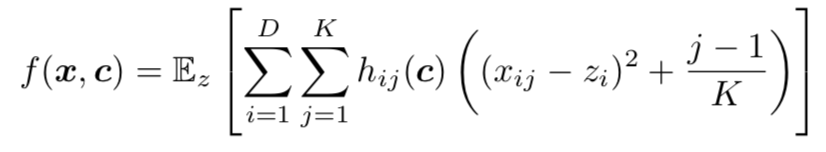-
News Message
随机优化算法的证明以及在架构搜索上的应用
- by wittx 2019-06-19

ICML 全称是 International Conference on Machine Learning,由国际机器学习学会(IMLS)举办,是计算机人工智能领域的顶级会议。今年的 ICML2019 是第 36 届的会议,将于 6 月 9 日至 15 日在加州的 Long Beach 的举办,此次会议共收录了 236 篇文章。而在本年的 ICML 网站上,也公布了下一届 ICML 将于 7 月 13-18 号在奥地利的维也纳举办。
本文将分析 3 篇今年 ICML 的文章,重点在优化算法上。前两篇是用数学方法证明了随机算法的收敛性、在寻找全局最优解的优势。而后一篇是对于随机梯度法在架构搜索上的应用。
因此,本文所讨论的 3 篇论文有:
AdaGrad stepsizes: sharp convergence over nonconvex landscapes, from any initialization
Gradient Descent Finds Global Minima of Deep Neural Networks
Adaptive Stochastic Natural Gradient Method for One-Shot Neural Architecture Search
论文 1:AdaGrad stepsizes: sharp convergence over nonconvex landscapes, from any initialization
作者:Rachel Ward,Xiaoxia Wu,Léon Bottou
1)文章概述:
本文是一篇从数学上证明优化算法的文章,主要证明了 AdaGrad 算法在非凸拓扑上能够很好地收敛。AdaGrad 是自适应的梯度算法之一,因自动根据之前的梯度计算学习率且不需要手动微调(fine-tuning)学习率而被广泛应用于神经网络的优化。现有的理论可以证明 Adagrad 算法在在线优化和凸优化的条件下可以收敛。本文为 AdaGrad 的拓展之一,AdaGrad-Norm,在平滑的非凸拓扑上优化的收敛提供证明。在随机的设置下,AdaGrad-Norm 以 O(log(N)/√(N)) 的速率收敛至驻点。在批量(非随机)的设置下,以 O(1/N) 的速率收敛。收敛的精确度极高,且针对不同的超参有很强的鲁棒性。对比随机梯度下降法,其收敛主要取决于如何将步长调整为 Lipschitz 平滑常数和梯度的随机噪声水平。在现有的最先进模型中应用 AdaGrad-Norm,此优化算法显示出了很好的鲁棒性,且并没有对模型的泛化性造成影响。
2)作者简介:
本文的作者来自美国 Texas at Autstin 大学和 Facebook AI Research,所有的研究都于 Facebook 完成。Rachel Ward 是 Texas at Austin 大学 Oden 计算工程与科学研究所的数学副教授,主要研究领域有数学信号处理、应用谐波分析、压缩传感、理论计算机科学和机器学习。Xiaoxia Wu 也是 Texas at Austin 大学的数学系助教(Google Scholar Profile:https://scholar.google.com/citations?user=Ry0Bdt8AAAAJ&hl=en)。Léon Bottou 是 Facebook 的研究总负责人(research lead),在 2015 年加入 Facebook 前曾在 AT&T 贝尔实验室,AT&T 实验室,NEC 美国实验室和微软研究院任职。主要研究领域是人工智能,尤其是深度神经网络和学习系统的因果推断(causal inference)。
3)文章背景介绍、关键词解析:
Adagrad 算法是基于随机梯度下降法(SGD)方法之上,对于学习率的更新方法进行了改变。原本的随机梯度下降法是目前应用最广泛的标准优化算法,其对于权重的更新方式是:
即学习率 α 是固定的,不随梯度的变化和更新的次数调整。g 是随机梯度满足 E[g(t,i)] = ∇F(t,i)。因此在使用 SGD 算法的时候,选择一个合适的学习率是非常重要的,直接决定了一个算法在收敛速度甚至是准确度上是否有好的表现。
文中提到了 Lipschitz 常数(L)。在数学分析中,以鲁道夫·利普希茨(Rudolf Lipschitz)命名的 Lipschitz 常数的定义是:存在一个实数,使得对于该函数的图上的每对点,连接它们的线的斜率的绝对值不大于这个实数,最小的这种界限称为函数的 Lipschitz 常数。在文中,Lipschitz 常数是代表损失方程拓扑的超参,用来证明 AdaGrad-Norm 在不同损失方程下皆可收敛。
Nesterov 早在 1998 年 [1] 证明,在 SGD 算法中,当学习率固定时,只有在学习率α≤ 1/L 时,优化的方程可以收敛,反之,即使学习率仅翻一倍,优化的方程极有可能震荡或发散。因此,一个确定的学习率很有可能给优化算法的有效性带来挑战。Robbins/Monro 理论 [2] 可对优化率的选择范围提供一些指导,理论认为如果要使方程解出最优解,则学习率 η 符合以下条件:
然而这一范围并没有给学习率的选择提供指导性的作用。手动选择学习率不仅非常繁琐耗时,而且没有强理论的支持,因此,如何选择学习率是一个非常重要的研究课题。
而 Adagrad 方法在 SGD 算法的基础上进行了更新,使学习率不再由手动选择,而是通过算法进行构架,新的权重的更新方法是:
其中 G 是对角矩阵,矩阵第(i,i)项为θi 从第 1 轮到第 t 轮梯度的平方和。在无噪声的情况下,取值梯度值,在有噪声的情况下,取值梯度的无偏估计 E[G] = ∇F(x)。ϵ取一极小值,为平滑项,作用是防止分母为零。由此可知随着优化的递进,学习率将不断降低,因此不需要手动调节学习率,是一种自适应的梯度算法。缺点是随着遍历次数的增加,学习率趋近于零,权重有可能提前结束更新。
Adagrad 在凸优化中的收敛性质早在 2011 年在 [3] 中有证明。之后,由一系列带和不带动量的基于 AdaGrad 的算法被开发,包括 RMSprop、AdaDelta、Adam、AdaFTRL、SGD-BB、AdaBatch、SC-Adagrad、AMSGRAD、Padam 等。这些算法是否能证明收敛性是非常有意思的课题。
本文使用的是 AdaGrad 系列里的一种优化算法——Adagrad-Norm。算法的数学表达式在下面列出:
在 [4] 中,AdaGrad-Norm 在凸优化中的收敛已被严格地验证,但在非凸的情况下,关于其收敛性无法通过 SGD 的收敛性推算证明。本文即提供了这一证明。
关于 AdaGrad—Norm 的伪代码可以从下图看到:
图 1:AdaGrad-Norm 的伪代码
4)文章详解:
文章针对 AdaGrad-Norm 算法的自适应学习率进行了讨论,目标是在机器学习模型的中使用此优化算法,使其在不同的超参(例噪声等级以及 Lipschitz 常数)中皆能收敛,而收敛速度非本文的讨论重心。
证明的假设包括以下几点:
Eξk [G(xk,ξk)] = ∇F(xk) 是∇F (xj )^2 的无偏估计
随机矢量ξk, k = 0, 1, 2, . . .,是互相独立的且对 xk 独立
Eξk[∥G(xk,ξk)−∇F(xk)∥^2]≤σ^2
∥∇F(x)∥^2 ≤ γ^2
在此基础上催生出以下定理:
结果显示 AdaGrad-Norm 在任何学习率大于零且 b0>0 的情况下收敛。由此派生出新的定理。
证明显示,SGD 算法的常数学习率在大于 2/L 的情况下无法收敛,但 AdaGrad-Norm 可在任何值的 b0 和 η 下收敛。
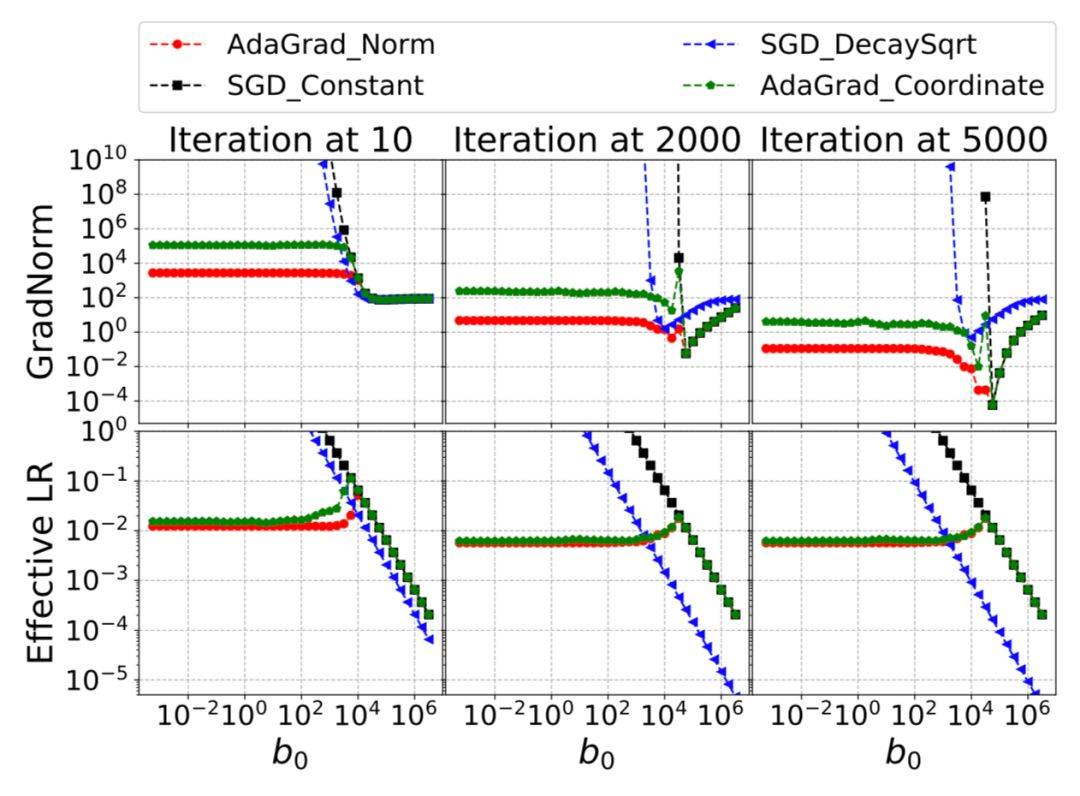
作者接着对证明出收敛性的算法进行了一系列的实操实验,在使用合成数据的线性回归中得到了如下的结果:
图 1:高斯数据在随机设置下优化器的表现。
由图 1 所示,AdaGrad-Norm 和 AdaGrad-Coordinate 自动调整学习率来逼近 Lipschitz 常数,且在大范围的 b0 值中收敛,较 SGD 方法有更好的收敛性。即使在 b0 值初始过小的情况下,AdaGrad-Norm 和 AdaGrad-Coordinate 也会收敛且速度很快。当 b0 的初始值过大的情况下,AdaGrad-Norm 和 AdaGrad-Coordinate 会以 SGD-Constant 相同的速度收敛。
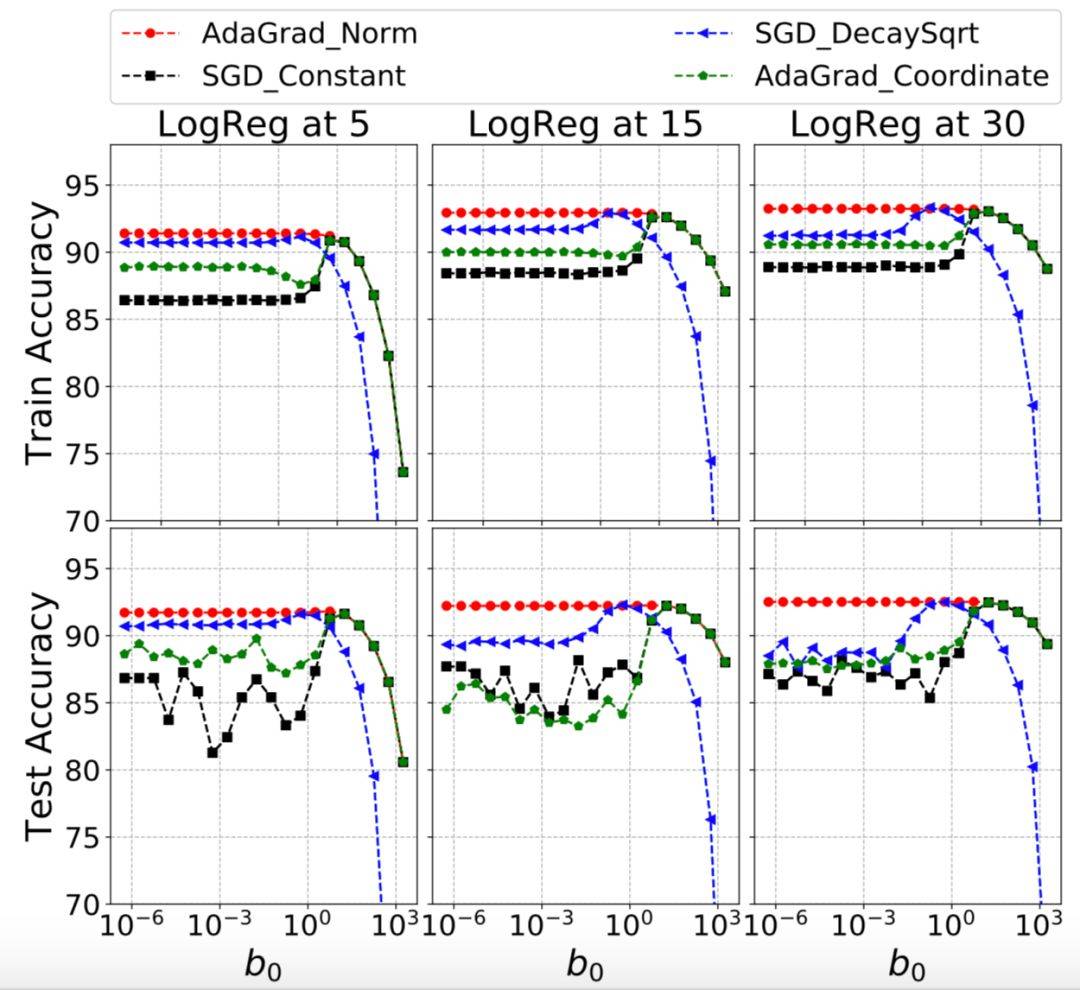
图 2:MNIST 数据集,竖轴是 AdaGrad-Norm 在训练数据集和测试数据集上的准确度。
图 2 是在 MNIST 数据集上的使用效果,由图 2 所示,为了使之前的假设成立,网络没有使用正则化、归一化,AdaGrad-Norm 自动找到学习率,其测试的准确率一直高于其他被测试的算法。
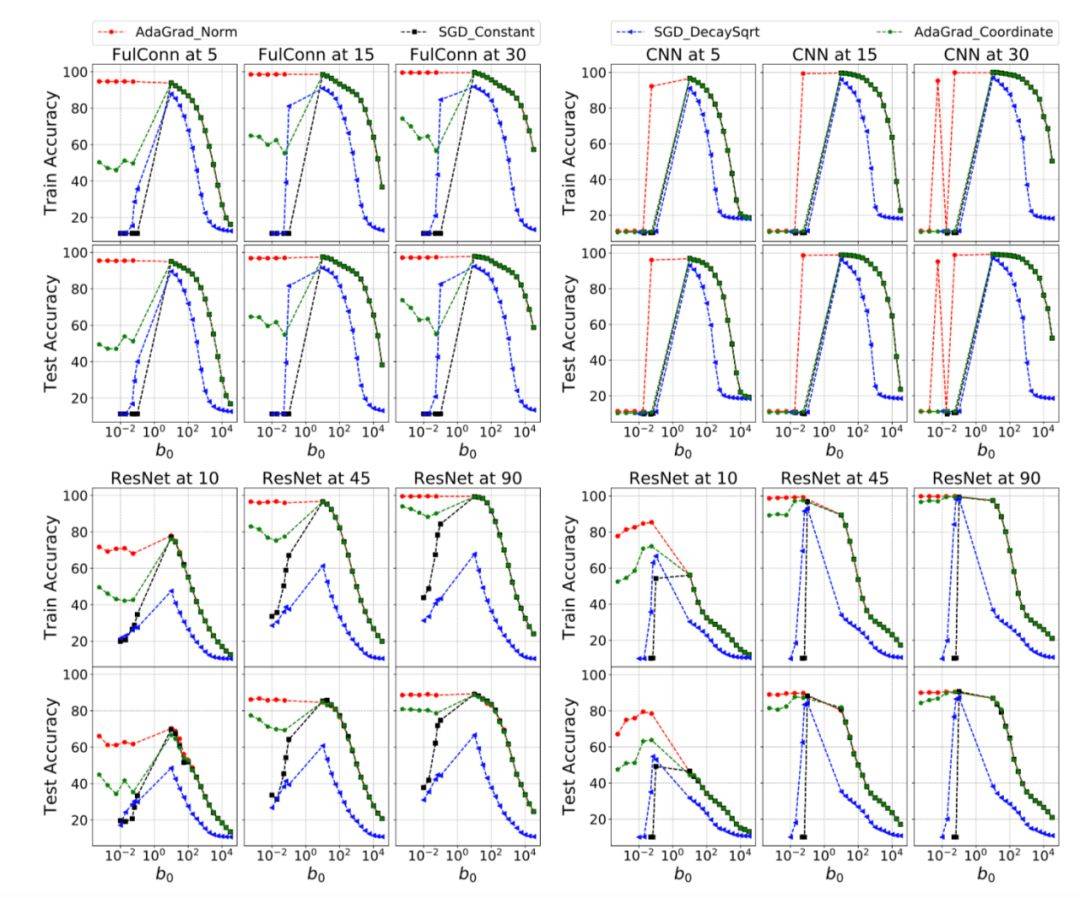
图 3:左上 6 图为 MNIST 数据集使用两层全连接神经网络所生成的结果,右上为使用 CNN 在 MNIST 上面跑的结果,左下为使用 ResNet-18 在 CIFAR10 上跑的结果且不使用可学习参数,右下为 ResNet-18 在 CIFAR10 使用默认的批量梯度下降法。
如图 3 所示,AdaGrad-Norm 的收敛具有很强的鲁棒性,尤其是针对与 b0 的选择上。当 b0 以很大范围的数值初始化时,AdaGrad-Norm 的收敛性达到 SGD 的收敛性。在 CNN 和 ResNet 的表现上,AdaGrad-Norm 表现也十分出色,在图 3 的右上角,AdaGrad 的非收敛性可以解释为梯度规范的无边界性。而 18 层和 50 层的 ResNet 都针对 b0 的值有很好的鲁棒性。
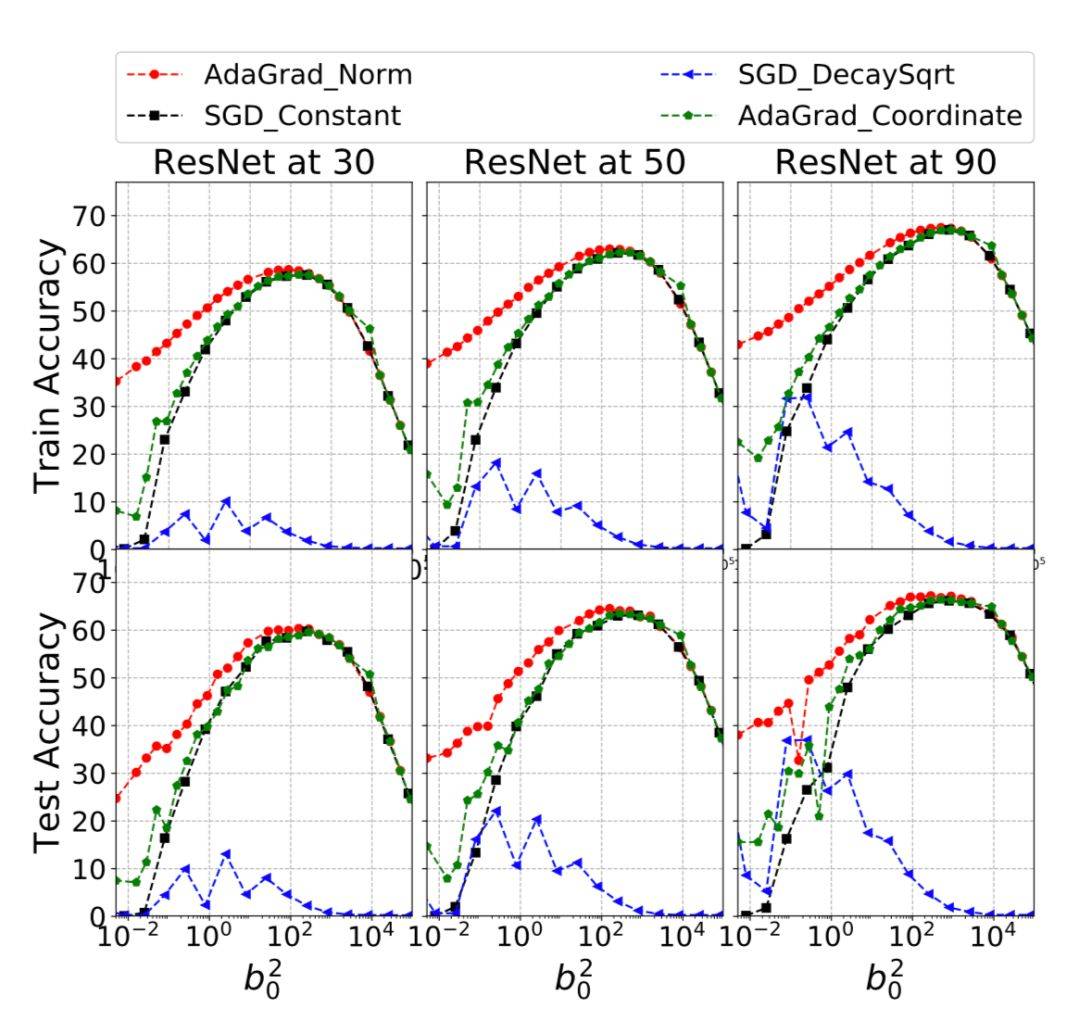
图 4:ImageNet 使用 ResNet-50 进行训练,y-轴是平均的训练和测试准确度。训练增加了动量。
在文章的最后,作者给 SGD 算法加入了动量来证明自适应方法在有动量的情况下的鲁棒性。文中使用了动量为 0.9 的默认值,结果显示 AdaGrad-Norm 在有动量的情况下对 SGD 初始化有着很强的鲁棒性。当 b0 比 Lipschitz 常数更大的时候,带动量的 SGD 比 AdaGrad-Norm 表现更好。当 b0 小于 Lipschitz 常数时,AdaGrad-Norm 的表现比 SGD 好。
5)文章亮点:
文章带领我们再次回顾了随机优化中使用自适应学习率的算法,焦点在于 AdaGrad-Norm 算法的收敛性证明。
文章出色地证明出了 AdaGrad-Norm 的收敛性优于 SGD,即使在初始值过大或过小的情况下,收敛性依然很好。
证明出的收敛率在真实和虚构的数据集上均有很好的表现,针对与 b0 不同的初始化值有极强的鲁棒性。
6)分析师见解:
文章的数学论证严谨,很好地证明了 AdaGrad-Norm 算法的收敛性及鲁棒性。
文章的立意是非常有价值的,通过证明一个常用的自适应学习优化算法数学上的收敛性以及在数据集上的收敛性,很好的推广至带动量 SGD 自适应算法的收敛性。
文章的考虑十分周到,从理论的证明到实例的应用,从模拟数据集到真实的 MNIST 和 ImageNet 数据集,都有很严谨的实验和论证,给优化算法的证明类型的论文提供了很好的模版。
7)引用:
[1] Y. Nesterov. Introductory lectures on convex programming volume i: Basic course. 1998.
[2] H. Robbins and S. Monro. A stochastic approximation method. In The Annals of Mathe- matical Statistics, volume 22, pages 400–407, 1951.
[3] J. Duchi, E. Hazan, and Y. Singer. Adaptive subgradient methods for online learning and stochastic optimization. Journal of Machine Learning Research, 12(Jul):2121–2159, 2011.
[4]K. Levy. Online to offline conversions, universality and adaptive minibatch sizes. In Advances in Neural Information Processing Systems, pages 1612–1621, 2017.
论文 2:Gradient Descent Finds Global Minima of Deep Neural Networks
作者:Simon S. Du,Jason D. Lee,Haochuan Li,Liwei Wang,Xiyu Zhai
1)文章概述:
梯度下降法可以在非凸拓扑上找到全局最优点。本文主要证明了梯度下降法可以在过拟合的 ResNet 上以多项式时间找到最优点,使损失方程值达到零。全局最优点由格拉姆矩阵(Gram matrix)的稳定性证明。在深度残余卷积神经网络(deep residual CNN)的应用上,梯度下降依然可以优化至全局最优解,且损失函数为零。
2)作者简介:
文章的作者依次来自卡耐基梅隆大学的机器学习系、南加州大学的数据科学和运筹学系、北京大学物理系、北京大学数据科学中心北京大学的机器感知实验室、以及麻省理工大学的电子和计算机系。第一作者 Simon S. Du 是卡耐基梅隆大学的博士生,拥有诸多 ICLR、ICML 及 NIPS 上的文章,曾在微软和脸谱网的实验室工作过,目前师从 Aarti Singh 和 Barnabás Póczos。
3)文章背景、关键词介绍:
在对深度神经网络进行优化的时候,经常会出现损失函数为零的情况,在大多数情况下,有一种说法认为是过拟合的原因,因为一般情况下只有在神经网络容量很大的时候,才有可能拟合所有的训练数据。同时也有一种说法,更深的神经网络更难训练,于是便催生出了 ResNet,使更深的神经网络可以被优化。本文将针对这两种说法进行探究,证明随机初始化的梯度下降可以收敛至损失函数为零。
在此之前,已有一些文献已经描述了梯度下降法的优点,例如,针对所有 1)局部最优点即为全局最优点的,2)每一个鞍点都有负曲率的方程,梯度下降法可以成功找到全局最优解 [1][2][3][4]。然而,即使是三层的神经网络都有不含负曲率的鞍点,因此此方法无法证明梯度下降法的普适性。而针对某种神经网络结构证明收敛性,即本文所使用的方法,是一种更好的证明方法。
3.1)格拉姆矩阵(Gram matrix):
文中涉及对格拉姆矩阵的讨论。在线性代数中,内积空间中一族向量 v1, ..., vn 的格拉姆矩阵(Gramian matrix 或 Gram matrix, Gramian)是内积的对称矩阵,其元素由 Gij=(vj|vi) 给出。一个重要的应用是计算线性无关:一族向量线性无关当且仅当格拉姆行列式(Gram determinant)不等于零。
3.2)ResNet:
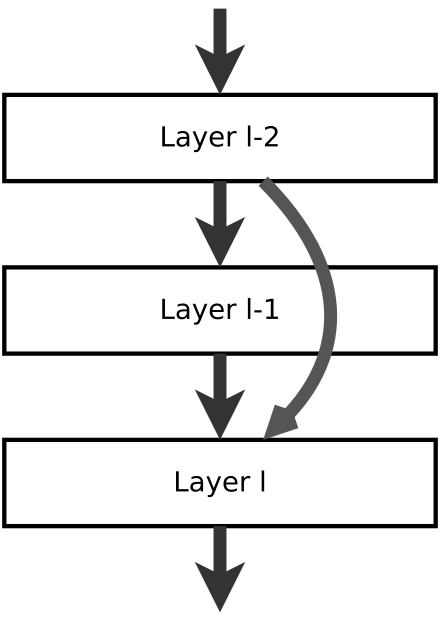
残余神经网络(Residual neural network)是一种人工神经网络,由大脑皮层的锥体细胞传导方式衍生而来。在残余神经网络中,有一些神经网络的层是被以更快捷的方式跳过的。典型的残余神经网络通过双层或三层跳过实现,在调层中仍包含激活函数和间隔归一化。ResNet 的结构由图一可见。
图 1:残余神经网络 ResNet 的结构(摘自 wikipedia)
在数值的计算上,ResNet 通过以下等式实现,即将前一层的神经元的值通过一定权重直接跳过后一或两层,叠加至神经元的值上。其中 a 为激活函数的输出值,W 为权重,g 为激活函数,Z 为线性变换后的输出值,即 Z=Wa+b。
3.3)梯度下降:
在使用梯度下降的时候,所有的参数均初始化为正态分布的随机值,且使用梯度下降法进行优化,公式为:
4)文章详解:
4.1)全连接神经网络:
文章先介绍了几种神经网络结构的定义,其中,全连接神经网络的定义为:
其中,激活函数 σ 前的参数为归一化时所使用的常数。在文中,全连接神经网络的 Gram matrix 的定义如下:
关于收敛率的论证如定理 5.1 所示。收敛速度和过拟合的量取决于该 Gram 矩阵的最小特征值。我们只要输入训练数据不是简并的,那么λminK(H)就是严格正的。则证明收敛率的方法如下。该定理表明,如果宽度 m 足够大,并且有合适的步长值,则梯度下降可以以线性速率收敛到全局最小值,随时函数值为零。该定理的主要假设是我们需要每层的足够大的宽度。宽度 m 取决于 n,H 和 1/λmin Kˆ(H),对 n 的依赖也是多项式级的,因此 m 也是多项式级别的。对于层数 H 的依赖性是指数级的,这种指数来自全连接架构的不稳定性。
4.2)ResNet
文中使用了一种每层都有跳层的连接(skip-connections)的 ResNet 结构,定义为:
Gram matrix 在 ResNet 结构中定义为:
则关于收敛率的论证如定理 6.1 所示。与定理 5.1 形成鲜明对比的是,因为神经元的数量和收敛速度在 n 和 H 中都是多项式级的,所以这个定理是多项式级的。过拟合的数量取决于λmin Kˆ(H) 矩阵。这里没有任何指数因子的主要原因是,ResNet 的结构中跳过连接层,使得整个架构在初始化阶段和训练阶段都更加稳定。
4.3)Residual CNN
最后,Residual CNN 被定义为:
其中 Φ 的定义为:
则 Gram matrix 的定义为:
关于收敛率的证明为定理 7.1 所证。这个定理的证明类似于 ResNet。每层所需的神经元数量是深度的多项式级的,数据点和步长的数量级也是多项式级的。在 m 和η的要求中唯一的额外项是 poly(p),其分析方法也和 ResNet 类似。
5)文章亮点:
文章主要的贡献有以下几点:
在全连接神经网络中,文章证明了如果达到一定数量的网络宽度,则随机初始化的梯度下降可以以线性速度收敛至损失函数为零。
当使用带有跳跃连接的全连神经网络时,在指数级更小的宽度上,随机初始化的梯度下降可以以线性速度收敛至损失函数为零。和第一个结果相比较,优化对于宽度的依赖大大降低。
当使用卷积的 ResNet 时,在更小级别的宽度上,随机初始化的梯度下降可以收敛至损失函数为零
6)分析师见解:
本文破解了神经网络优化中的迷思,即在过拟合的情况下神经网络是否可以优化至损失函数值为零。文章从多个网络结构证明了梯度下降法是可以在过拟合的网络中将损失函数的值收敛至零,在数学上收敛为零是成立的。文章的作者在最后提出了几个未来发展的方向,包括探索测试数据集的准确率、继续证明更低宽度的 ResNet 的收敛性、证明随机梯度下降法是否是线性收敛、以及如何继续降低收敛率等,这些发展方向都很好地贴切了现在训练所遇到的问题,以及为此文所证明的内容的重要性进行了证实。证明在过拟合的情况下神经网络能够收敛于 0 损失函数,是对梯度下降法的实用性有了很好的说明。
7)引用:
[1] Jin, C., Ge, R., Netrapalli, P., Kakade, S. M., and Jordan, M. I. How to escape saddle points efficiently. In Proceed- ings of the 34th International Conference on Machine Learning, pp. 1724–1732, 2017
[2] Ge, R., Huang, F., Jin, C., and Yuan, Y. Escaping from saddle points − online stochastic gradient for tensor de- composition. In Proceedings of The 28th Conference on Learning Theory, pp. 797–842, 2015.
[3] Lee, J. D., Simchowitz, M., Jordan, M. I., and Recht, B. Gradient descent only converges to minimizers. In Con- ference on Learning Theory, pp. 1246–1257, 2016.
[4] Du, S. S., Jin, C., Lee, J. D., Jordan, M. I., Singh, A., and Poczos, B. Gradient descent can take exponential time to escape saddle points. In Advances in Neural Information Processing Systems, pp. 1067–1077, 2017.
论文 3:Adaptive Stochastic Natural Gradient Method for One-Shot Neural Architecture Search
作者:Youhei Akimoto,Shinichi Shirakawa,Nozomu Yoshinari,Kento Uchida,Shota Saito,Kouhei Nishida
1)文章概述:
神经网络结构搜索(NAS)方法针对于学习率和搜索空间有很强的敏感性,以至于使用者很难将之运用于某一特殊的问题,尽管搜索方法的目的是将参数调整自动化。文章为生产出快速、强大、广泛适用的神经网络结构搜索方法提供了框架。文章通过随机松弛将连接权重和神经结构的耦合优化转化为可微分优化,其广泛适用性在于它接受任意搜索空间,其速度在于能够同步优化梯度的权重和架构,其鲁棒性在于自适应的学习率有强大的理论支持。文中的方法简单且泛化性很好,在图像分类和修复任务方面表现出接近最先进的技术的性能并使用极低的计算预算。
2)作者简介:
文章的作者均来自日本,来自大学的包括筑波大学、横滨国立大学、信州大学,来自企业的包括 SkillUp AI 有限公司。
3)文章背景介绍:
2017 年以前的神经网络结构搜索多是调整超参的方式在一个固定的结构下运行神经网络并得出验证数据的错误率,但现有的较为前沿的研究同步优化权重和结构并将所有可能的结构视为超图的子图,这种方法被称作一次性结构搜索(one-shot architecture search),这种方法的好处是较低的结构评估计算成本,即可在一台标准的个人电脑上运营,可以大大扩展其应用面。
NAS 的研究主要有三个大方向:1)如何估计架构的表现,2)如何定义搜索空间,3)如何优化结构。在结构的优化上可以通过连续松弛或随机松弛将权重和架构的耦合优化转化为可微分目标的优化,采用梯度下降或自然梯度下降策略,采用现有的自适应步长机制或恒定步长,可以同时优化网络权重和结构。但是,优化性能对其输入是非常敏感的,例如学习速率和搜索空间,因此,本文将针对这些问题进行改进。
4)文章详解:
本文基于随机自然梯度法 [1] 通过随机松弛开发了统一的优化框架 ASNG。文章的理论研究得出了一个关于步长的条件,使目标函数的值可以在每次迭代中单调改进。我们提出了一个步长适应机制,以近似满足此条件。它显著降低了架构对输入的敏感性,使整个框架更加灵活。其伪代码如下所示:
ASNG 的鲁棒性首先在一些测试方程上进行验证,方程的形式为:
其中,c 是分类变量,h(c)是单热矢量(one-hot vector)。方程用来模拟神经网络的优化,使方程使用 z 值逼近期望值。优化使用了带动量的随机梯度下降法,动量值为 0.9。
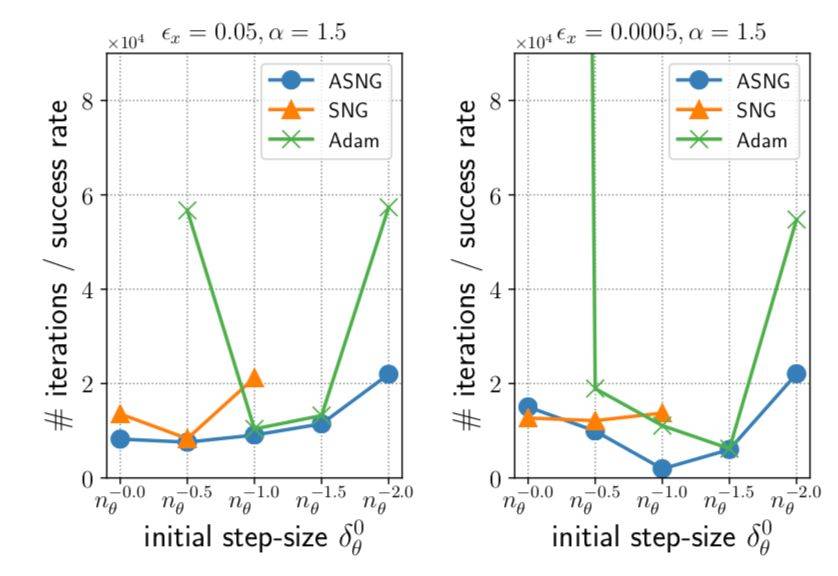
图 2 显示了对比 ASNG(Adaptive Stochastic Natural Gradient),SNG(stochastic natural gradient with constant step-size)以及 Adam 在同一深度网络上的优化表现,图中可以看出,ASNG 表现突出,SNG 以及 Adam 在使用上需要微调步长,不然就会无法优化至最优解,而 ASNG 针对与步长的灵敏度已降低,所以有更加出色的表现。
图 2:运行 ASNG 在ε=0.05 与 0.0005 值下的成果图,图中为跑 100 次程序的平均值,空缺的数据代表参数不能跑出结果。
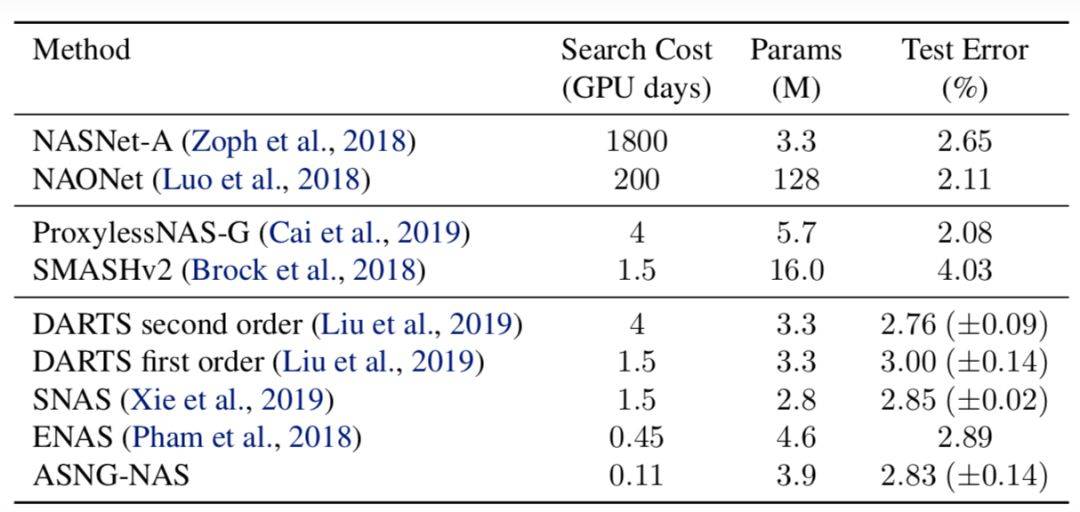
ASGN 在文中还被应用于图片的分类问题。分类使用了 CIFAR-10 数据集并进行预处理。最终结果如表 1 所示。最下面的 5 种方法采取了相似的搜索空间,因此结果的不同是由于不同的搜索算法,表中可以清楚地看到搜索成本和最终结果之间的平衡,越高的精度越需要较长时间的搜索。在相对较快的几种算法中,ASGN 是最快的,且错误率与其他算法相近。
表 1:不同的使用于 CIFAR-10 数据集的结构搜索方法的对比,其中搜索成本指 GPU 天数并包括再训练的成本。
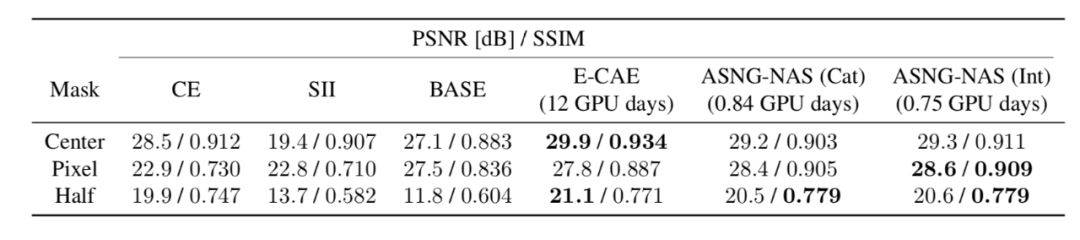
ASGN 还被运用于图像修复,文中使用了 CelebFaces Attributes 数据集,作者使用了 3 种不同的面具进行预处理,是图片的部分缺失,面具包括:中心正方形面具、80% 像素随机消失面具、图片一半消失面具(横或竖)。修复完成的图片用两种指标衡量,峰值信噪比(PSNR)和结构相似性指数(SSIM),越高的值代表越好的结果。修复的结果如表 2 所示,ASNG-NAS 的表现在所有面具上优于 CE,SII,BASE,并近似于 E-CAE。而 E-CAE 需要的训练时间是 12 个 GPU 日,ASNG-NAS 仅需要不到 1 个 GPU 日。这代表 ASNG-NAS 带来了速度上的飞跃且不影响最终的结果。
表 2:图片修复的结果:ASNG-NAS(Cat)将所有结构参数编码为分类变量,ASNG-NAS(Int)将结构参数编码为整型变量。
5)文章亮点:
文章的主要贡献包括以下几点:
提供了一个几乎可以处理任意类型结构变量的架构,只要可以在其上定义一个参数组的概率分布
文章提出了针对于随机自然梯度上升法制定了步长自适应的机制,提高了优化速度和超参调整的鲁棒性,并为所有引入的超参数准备了默认值,即使架构搜索空间发生变化也无需改变它们
所提出的方法可以并行运算,它与现有方法的速度相当甚至更快,即使是在串行实现上也是如此
提出的策略非常简单,所以可以很好的开发步长自适应机制
6)分析师见解:
本文提供了一个很好的使用随机自然梯度法的方式进行神经网络的结构优化,不仅在数学上有严谨的推论,也最终在算法表现的对比上取得了较好的成果。值的一提的是,ASGN-NAS 方法在速度上有极大的优势,在精确度上也有较好的表现,因使用了随机松弛而可以使用简单的梯度方法对参数进行优化,所以在方法的操作上有一定的优势。自适应的步长机制极大地简化了超参调整,使得模型有了更多的灵活性,因此,这篇文章在神经网络的结构优化上有很好的突破创新。
7)引用:
[1] Amari, S. Natural Gradient Works Efficiently in Learning.Neural Computation, 10(2):251–276, 1998
分析师简介:
Sushen Zhang,剑桥大学人工智能领域在读博士生,主要攻克方向为人工智能的优化算法。是一位在人工智能领域的探索者,希望永远保持小队长的心态,对世界好奇,对人工智能乐观,带领大家一起探索人工智能这个蓬勃发展的领域。
Share Http URL: http://www.wittx.cn/get_news_message.do?new_id=220

Best Last Month

Information industry by wittx

Information industry by wittx
Information industry by wittx
Information industry by wittx

Information industry by wittx

Information industry by wittx
Information industry by wittx

Computer software and hardware by wittx
Information industry by wittx
Information industry by wittx