
-
News Message
Brain implants that let you speak your mind
- by wittx 2020-09-04
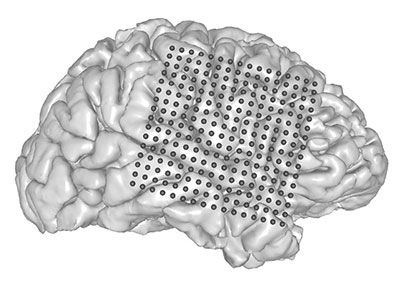
Speaking might seem an effortless activity, but it is one of the most complex actions that we perform. It requires precise, dynamic coordination of muscles in the articulator structures of the vocal tract — the lips, tongue, larynx and jaw. When speech is disrupted as a consequence of stroke, amyotrophic lateral sclerosis or other neurological disorders, loss of the ability to communicate can be devastating. In a paper in Nature, Anumanchipalli et al.1 bring us closer to a brain–computer interface (BCI) that can restore speech function.
Brain–computer interfaces aim to help people with paralysis by ‘reading’ their intentions directly from the brain and using that information to control external devices or move paralysed limbs. The development of BCIs for communication has been mainly focused on brain-controlled typing2, allowing people with paralysis to type up to eight words per minute3. Although restoring this level of function might change the lives of people who have severe communication deficits, typing-based BCIs are unlikely to achieve the fluid communication of natural speech, which averages about 150 words per minute. Anumanchipalli et al. have developed an approach in which spoken sentences are produced from brain signals using deep-learning methods.
The researchers worked with five volunteers who were undergoing a procedure termed intracranial monitoring, in which electrodes are used to monitor brain activity as part of a treatment for epilepsy. The authors used a technique called high-density electrocorticography to track the activity of areas of the brain that control speech and articulator movement as the volunteers spoke several hundred sentences. To reconstruct speech, rather than transforming brain signals directly into audio signals, Anumanchipalli et al. used a two-stage decoding approach in which they first transformed neural signals into representations of movements of the vocal-tract articulators, and then transformed the decoded movements into spoken sentences (Fig. 1). Both of these transformations used recurrent neural networks — a type of artificial neural network that is particularly effective at processing and transforming data that have a complex temporal structure.
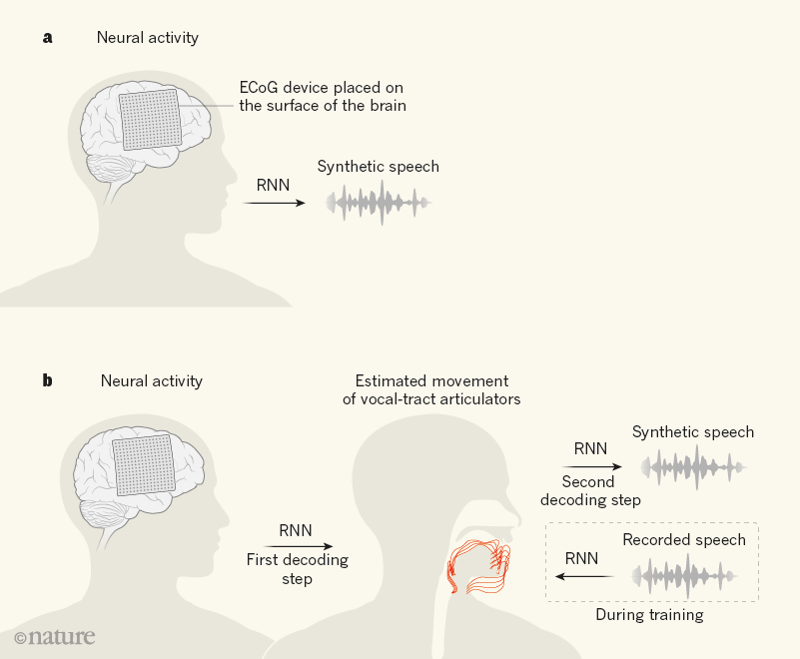
Figure 1 | Brain–computer interfaces for speech synthesis. a, Previous research in speech synthesis has taken the approach of monitoring neural signals in speech-related areas of the brain using an electrocorticography (ECoG) device and attempting to decode these signals directly into synthetic speech using a type of artificial neural network called a recurrent neural network (RNN). b, Anumanchipalli et al.1 developed a different method in which RNNs are used for two steps of decoding. One of these decoding steps transforms neural signals into estimated movements of the vocal-tract articulators (red) — the anatomical structures involved in speech production (lips, tongue, larynx and jaw). For training purposes in the first decoding step, the authors needed data that related each person’s vocal-tract movements to their neural activity. Because Anumanchipalli et al. could not measure each person’s vocal-tract movements directly, they built an RNN to estimate these movements on the basis of a large library of previously collected data4 of vocal-tract movements and speech recordings from many people. This RNN produced vocal-tract movement estimates that were sufficient to train the first decoder. The second decoding step transforms these estimated movements into synthetic speech. Anumanchipalli and colleagues’ two-step decoding approach produced spoken sentences that had markedly less distortion than is obtained with a comparable direct decoding approach.
Learning how brain signals relate to the movements of the vocal-tract articulators was challenging, because it is difficult to measure these movements directly when working in a hospital setting with people who have epilepsy. Instead, the authors used information from a model that they had developed previously4, which uses an artificial neural network to transform recorded speech into the movements of the vocal-tract articulators that produced it. This model is not subject-specific; rather, it was built using a large library of data collected from previous research participants4. By including a model to estimate vocal-tract movements from recorded speech, the authors could map brain activity onto vocal-tract movements without directly measuring the movements themselves.
Several studies have used deep-learning methods to reconstruct audio signals from brain signals (see, for example, refs 5, 6). These include an exciting BCI approach in which neural networks were used to synthesize spoken words (mostly monosyllabic) directly from brain areas that control speech6. By contrast, Anumanchipalli and colleagues split their decoding approach into two stages (one that decodes movements of the vocal-tract articulators and another that synthesizes speech), building on their previous observation that activity in speech-related brain areas corresponds more closely to the movements of the vocal articulators than to the acoustic signals produced during speech4.
The authors’ two-stage approach resulted in markedly less acoustic distortion than occurred with the direct decoding of acoustic features. If massive data sets spanning a wide variety of speech conditions were available, direct synthesis would probably match or outperform a two-stage decoding approach. However, given the data-set limitations that exist in practice, having an intermediate stage of decoding brings information about normal motor function of the vocal-tract articulators into the model, and constrains the possible parameters of the neural-network model that must be evaluated. This approach seems to have enabled the neural networks to achieve higher performance. Ultimately, ‘biomimetic’ approaches that mirror normal motor function might have a key role in replicating the high-speed, high-accuracy communication typical of natural speech.
The development and adoption of robust metrics that allow meaningful comparisons across studies is a challenge in BCI research, including the nascent field of speech BCIs. For example, a metric such as the error in reconstructing the original spoken audio might have little correspondence to a BCI’s functional performance; that is, whether a listener can understand the synthesized speech. To address this problem, Anumanchipalli et al. developed easily replicable measures of speech intelligibility for human listeners, taken from the field of speech engineering. The researchers recruited users on the crowdsourcing marketplace Amazon Mechanical Turk, and tasked them with identifying words or sentences from synthesized speech. Unlike the reconstruction error or previously used automated intelligibility measures6, this approach directly measures the intelligibility of speech to human listeners without the need for comparison with the original spoken words.
Anumanchipalli and colleagues’ results provide a compelling proof of concept for a speech-synthesis BCI, both in terms of the accuracy of audio reconstruction and in the ability of listeners to classify the words and sentences produced. However, many challenges remain on the path to a clinically viable speech BCI. The intelligibility of the reconstructed speech was still much lower than that of natural speech. Whether the BCI can be further improved by collecting larger data sets and continuing to develop the underlying computational approaches remains to be seen. Additional improvements might be obtained by using neural interfaces that record more-localized brain activity than that recorded with electrocorticography. Intracortical microelectrode arrays, for example, have generally led to higher performance than electrocorticography in other areas of BCI research3,7.
Another limitation of all current approaches for speech decoding is the need to train decoders using vocalized speech. Therefore, BCIs based on these approaches could not be directly applied to people who cannot speak. But Anumanchipalli and colleagues showed that speech synthesis was still possible when volunteers mimed speech without making sounds, although speech decoding was substantially less accurate. Whether individuals who can no longer produce speech-related movements will be able to use speech-synthesis BCIs is a question for future research. Notably, after the development of the first proof-of-concept studies of BCIs to control arm and hand movements in healthy animals, similar questions were raised about the applicability of such BCIs in people with paralysis. Subsequent clinical trials have compellingly demonstrated rapid communication, control of robotic arms and restoration of sensation and movement of paralysed limbs in humans using these BCIs8,9.
Given that human speech production cannot be directly studied in animals, the rapid progress in this research area over the past decade — from groundbreaking clinical studies that probed the organization of speech-related brain regions10 to proof-of-concept speech-synthesis BCIs6 — is truly remarkable. These achievements are a testament to the power of multidisciplinary collaborative teams that combine neurosurgeons, neurologists, engineers, neuroscientists, clinical staff, linguists and computer scientists. The most recent results would also have been impossible without the emergence of deep-learning and artificial neural networks, which have widespread applications in neuroscience and neuroengineering11–13.
Finally, these compelling proof-of-concept demonstrations of speech synthesis in individuals who cannot speak, combined with the rapid progress of BCIs in people with upper-limb paralysis, argue that clinical studies involving people with speech impairments should be strongly considered. With continued progress, we can hope that individuals with speech impairments will regain the ability to freely speak their minds and reconnect with the world around them.
Share Http URL: http://www.wittx.cn/get_news_message.do?new_id=191

Best Last Month

Information industry by wittx

Information industry by wittx
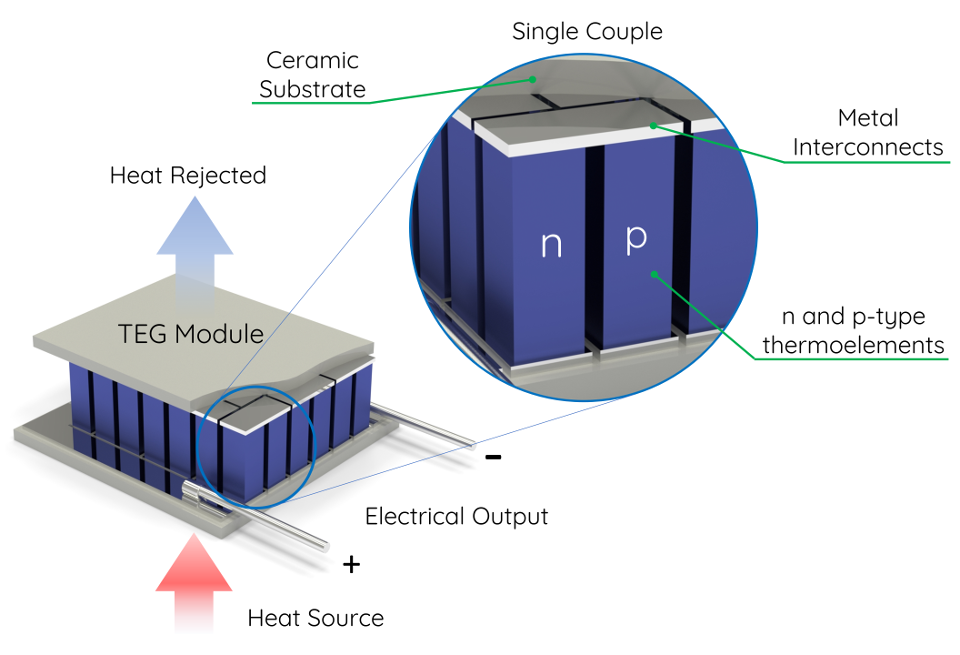
Information industry by wittxThree dimensional architected thermoelectric devices with high toughness and power conversion effici
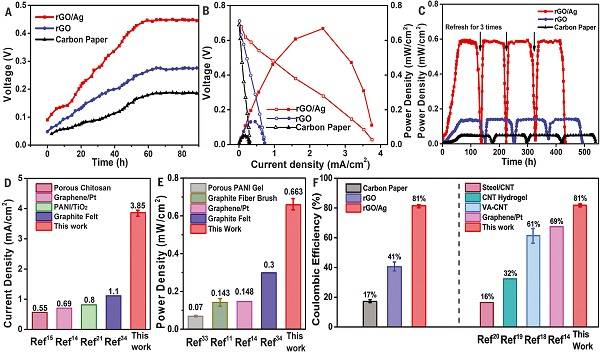
Information industry by wittx
Information industry by wittx
Information industry by wittx

Information industry by wittx

Information industry by wittx
Information industry by wittx
.jpg)
Computer software and hardware by wittx

