
-
News Message
Deep Reinforcement Learning Papers
- by wittx 2020-09-04
A list of recent papersregarding deep reinforcement learning.
The papers are organized based on manually-defined bookmarks.
They are sorted by time to see the recent papers first.
Any suggestions and pull requests are welcome.Bookmarks
· Robotics
· Games
· InverseReinforcement Learning
All Papers
· ContinuousDeep Q-Learning with Model-based Acceleration,Shixiang Gu et al., arXiv, 2016.
· DeepExploration via Bootstrapped DQN, I.Osband et al., arXiv, 2016.
· ValueIteration Networks, A. Tamar etal., arXiv, 2016.
· Learningto Communicate to Solve Riddles with Deep Distributed Recurrent Q-Networks, J. N.Foerster et al., arXiv, 2016.
· AsynchronousMethods for Deep Reinforcement Learning, V. Mnihet al., arXiv, 2016.
· Masteringthe game of Go with deep neural networks and tree search, D.Silver et al., Nature, 2016.
· Increasingthe Action Gap: New Operators for Reinforcement Learning, M. G.Bellemare et al., AAAI, 2016.
· Memory-basedcontrol with recurrent neural networks, N.Heess et al., NIPS Workshop, 2015.
· How toDiscount Deep Reinforcement Learning: Towards New Dynamic Strategies, V.François-Lavet et al., NIPS Workshop, 2015.
· MultiagentCooperation and Competition with Deep Reinforcement Learning, A.Tampuu et al., arXiv, 2015.
· StrategicDialogue Management via Deep Reinforcement Learning, H.Cuayáhuitl et al., NIPS Workshop, 2015.
· MazeBase:A Sandbox for Learning from Games, S.Sukhbaatar et al., arXiv, 2016.
· LearningSimple Algorithms from Examples, W.Zaremba et al., arXiv, 2015.
· DuelingNetwork Architectures for Deep Reinforcement Learning, Z. Wanget al., arXiv, 2015.
· Actor-Mimic:Deep Multitask and Transfer Reinforcement Learning, E.Parisotto, et al., ICLR, 2016.
· BetterComputer Go Player with Neural Network and Long-term Prediction, Y. Tianet al., ICLR, 2016.
· PolicyDistillation, A. A. Rusu etat., ICLR, 2016.
· PrioritizedExperience Replay, T. Schaul etal., ICLR, 2016.
· DeepReinforcement Learning with an Action Space Defined by Natural Language, J. Heet al., arXiv, 2015.
· DeepReinforcement Learning in Parameterized Action Space, M.Hausknecht et al., ICLR, 2016.
· TowardsVision-Based Deep Reinforcement Learning for Robotic Motion Control, F.Zhang et al., arXiv, 2015.
· GeneratingText with Deep Reinforcement Learning, H.Guo, arXiv, 2015.
· ADAAPT:A Deep Architecture for Adaptive Policy Transfer from Multiple Sources, J.Rajendran et al., arXiv, 2015.
· VariationalInformation Maximisation for Intrinsically Motivated Reinforcement Learning, S.Mohamed and D. J. Rezende,arXiv, 2015.
· DeepReinforcement Learning with Double Q-learning, H. vanHasselt et al., arXiv, 2015.
· RecurrentReinforcement Learning: A Hybrid Approach, X. Liet al., arXiv, 2015.
· Continuouscontrol with deep reinforcement learning, T. P.Lillicrap et al., ICLR, 2016.
· LanguageUnderstanding for Text-based Games Using Deep Reinforcement Learning, K.Narasimhan et al., EMNLP, 2015.
· Giraffe:Using Deep Reinforcement Learning to Play Chess, M.Lai, arXiv, 2015.
· Action-ConditionalVideo Prediction using Deep Networks in Atari Games, J. Ohet al., NIPS, 2015.
· LearningContinuous Control Policies by Stochastic Value Gradients, N.Heess et al., NIPS, 2015.
· LearningDeep Neural Network Policies with Continuous Memory States, M.Zhang et al., arXiv, 2015.
· DeepRecurrent Q-Learning for Partially Observable MDPs, M.Hausknecht and P. Stone, arXiv, 2015.
· Listen,Attend, and Walk: Neural Mapping of Navigational Instructions to ActionSequences, H. Mei et al., arXiv, 2015.
· IncentivizingExploration In Reinforcement Learning With Deep Predictive Models, B. C.Stadie et al., arXiv, 2015.
· MaximumEntropy Deep Inverse Reinforcement Learning, M.Wulfmeier et al., arXiv, 2015.
· High-DimensionalContinuous Control Using Generalized Advantage Estimation, J.Schulman et al., ICLR, 2016.
· End-to-EndTraining of Deep Visuomotor Policies, S.Levine et al., arXiv, 2015.
· DeepMPC:Learning Deep Latent Features for Model Predictive Control, I.Lenz, et al., RSS, 2015.
· UniversalValue Function Approximators, T. Schaulet al., ICML, 2015.
· DeterministicPolicy Gradient Algorithms, D. Silver etal., ICML, 2015.
· MassivelyParallel Methods for Deep Reinforcement Learning, A. Nairet al., ICML Workshop, 2015.
· TrustRegion Policy Optimization, J. Schulman etal., ICML, 2015.
· Human-levelcontrol through deep reinforcement learning, V. Mnihet al., Nature, 2015.
· DeepLearning for Real-Time Atari Game Play Using Offline Monte-Carlo Tree SearchPlanning, X. Guo et al., NIPS, 2014.
· PlayingAtari with Deep Reinforcement Learning, V. Mnihet al., NIPS Workshop, 2013.
Value FunctionApproximation
· ContinuousDeep Q-Learning with Model-based Acceleration,Shixiang Gu et al., arXiv, 2016.
· DeepExploration via Bootstrapped DQN, I.Osband et al., arXiv, 2016.
· ValueIteration Networks, A. Tamar etal., arXiv, 2016.
· Learningto Communicate to Solve Riddles with Deep Distributed Recurrent Q-Networks, J. N.Foerster et al., arXiv, 2016.
· AsynchronousMethods for Deep Reinforcement Learning, V. Mnihet al., arXiv, 2016.
· Masteringthe game of Go with deep neural networks and tree search, D.Silver et al., Nature, 2016.
· Increasingthe Action Gap: New Operators for Reinforcement Learning, M. G.Bellemare et al., AAAI, 2016.
· How toDiscount Deep Reinforcement Learning: Towards New Dynamic Strategies, V.François-Lavet et al., NIPS Workshop, 2015.
· MultiagentCooperation and Competition with Deep Reinforcement Learning, A.Tampuu et al., arXiv, 2015.
· StrategicDialogue Management via Deep Reinforcement Learning, H.Cuayáhuitl et al., NIPS Workshop, 2015.
· LearningSimple Algorithms from Examples, W.Zaremba et al., arXiv, 2015.
· DuelingNetwork Architectures for Deep Reinforcement Learning, Z. Wanget al., arXiv, 2015.
· PrioritizedExperience Replay, T. Schaul etal., ICLR, 2016.
· DeepReinforcement Learning with an Action Space Defined by Natural Language, J. Heet al., arXiv, 2015.
· DeepReinforcement Learning in Parameterized Action Space, M.Hausknecht et al., ICLR, 2016.
· TowardsVision-Based Deep Reinforcement Learning for Robotic Motion Control, F.Zhang et al., arXiv, 2015.
· GeneratingText with Deep Reinforcement Learning, H.Guo, arXiv, 2015.
· DeepReinforcement Learning with Double Q-learning, H. vanHasselt et al., arXiv, 2015.
· RecurrentReinforcement Learning: A Hybrid Approach, X. Liet al., arXiv, 2015.
· Continuouscontrol with deep reinforcement learning, T. P.Lillicrap et al., ICLR, 2016.
· LanguageUnderstanding for Text-based Games Using Deep Reinforcement Learning, K.Narasimhan et al., EMNLP, 2015.
· Action-ConditionalVideo Prediction using Deep Networks in Atari Games, J. Ohet al., NIPS, 2015.
· DeepRecurrent Q-Learning for Partially Observable MDPs, M.Hausknecht and P. Stone, arXiv, 2015.
· IncentivizingExploration In Reinforcement Learning With Deep Predictive Models, B. C.Stadie et al., arXiv, 2015.
· MassivelyParallel Methods for Deep Reinforcement Learning, A. Nairet al., ICML Workshop, 2015.
· Human-levelcontrol through deep reinforcement learning, V. Mnihet al., Nature, 2015.
· PlayingAtari with Deep Reinforcement Learning, V. Mnihet al., NIPS Workshop, 2013.
Policy Gradient
· AsynchronousMethods for Deep Reinforcement Learning, V. Mnihet al., arXiv, 2016.
· Masteringthe game of Go with deep neural networks and tree search, D.Silver et al., Nature, 2016.
· Memory-basedcontrol with recurrent neural networks, N.Heess et al., NIPS Workshop, 2015.
· MazeBase:A Sandbox for Learning from Games, S.Sukhbaatar et al., arXiv, 2016.
· ADAAPT:A Deep Architecture for Adaptive Policy Transfer from Multiple Sources, J.Rajendran et al., arXiv, 2015.
· Continuouscontrol with deep reinforcement learning, T. P.Lillicrap et al., ICLR, 2016.
· LearningContinuous Control Policies by Stochastic Value Gradients, N.Heess et al., NIPS, 2015.
· High-DimensionalContinuous Control Using Generalized Advantage Estimation, J.Schulman et al., ICLR, 2016.
· End-to-EndTraining of Deep Visuomotor Policies, S.Levine et al., arXiv, 2015.
· DeterministicPolicy Gradient Algorithms, D. Silver etal., ICML, 2015.
· TrustRegion Policy Optimization, J. Schulman etal., ICML, 2015.
Discrete Control
· DeepExploration via Bootstrapped DQN, I.Osband et al., arXiv, 2016.
· ValueIteration Networks, A. Tamar etal., arXiv, 2016.
· Learningto Communicate to Solve Riddles with Deep Distributed Recurrent Q-Networks, J. N.Foerster et al., arXiv, 2016.
· AsynchronousMethods for Deep Reinforcement Learning, V. Mnihet al., arXiv, 2016.
· Masteringthe game of Go with deep neural networks and tree search, D.Silver et al., Nature, 2016.
· Increasingthe Action Gap: New Operators for Reinforcement Learning, M. G.Bellemare et al., AAAI, 2016.
· How toDiscount Deep Reinforcement Learning: Towards New Dynamic Strategies, V.François-Lavet et al., NIPS Workshop, 2015.
· MultiagentCooperation and Competition with Deep Reinforcement Learning, A.Tampuu et al., arXiv, 2015.
· StrategicDialogue Management via Deep Reinforcement Learning, H.Cuayáhuitl et al., NIPS Workshop, 2015.
· LearningSimple Algorithms from Examples, W.Zaremba et al., arXiv, 2015.
· DuelingNetwork Architectures for Deep Reinforcement Learning, Z. Wanget al., arXiv, 2015.
· BetterComputer Go Player with Neural Network and Long-term Prediction, Y. Tianet al., ICLR, 2016.
· Actor-Mimic:Deep Multitask and Transfer Reinforcement Learning, E.Parisotto, et al., ICLR, 2016.
· PolicyDistillation, A. A. Rusu etat., ICLR, 2016.
· PrioritizedExperience Replay, T. Schaul etal., ICLR, 2016.
· DeepReinforcement Learning with an Action Space Defined by Natural Language, J. Heet al., arXiv, 2015.
· DeepReinforcement Learning in Parameterized Action Space, M.Hausknecht et al., ICLR, 2016.
· TowardsVision-Based Deep Reinforcement Learning for Robotic Motion Control, F.Zhang et al., arXiv, 2015.
· GeneratingText with Deep Reinforcement Learning, H.Guo, arXiv, 2015.
· ADAAPT:A Deep Architecture for Adaptive Policy Transfer from Multiple Sources, J.Rajendran et al., arXiv, 2015.
· VariationalInformation Maximisation for Intrinsically Motivated Reinforcement Learning, S.Mohamed and D. J. Rezende,arXiv, 2015.
· DeepReinforcement Learning with Double Q-learning, H. vanHasselt et al., arXiv, 2015.
· RecurrentReinforcement Learning: A Hybrid Approach, X. Liet al., arXiv, 2015.
· LanguageUnderstanding for Text-based Games Using Deep Reinforcement Learning, K.Narasimhan et al., EMNLP, 2015.
· Giraffe:Using Deep Reinforcement Learning to Play Chess, M.Lai, arXiv, 2015.
· Action-ConditionalVideo Prediction using Deep Networks in Atari Games, J. Ohet al., NIPS, 2015.
· DeepRecurrent Q-Learning for Partially Observable MDPs, M.Hausknecht and P. Stone, arXiv, 2015.
· Listen,Attend, and Walk: Neural Mapping of Navigational Instructions to ActionSequences, H. Mei et al., arXiv, 2015.
· IncentivizingExploration In Reinforcement Learning With Deep Predictive Models, B. C.Stadie et al., arXiv, 2015.
· UniversalValue Function Approximators, T.Schaul et al., ICML, 2015.
· MassivelyParallel Methods for Deep Reinforcement Learning, A. Nairet al., ICML Workshop, 2015.
· Human-levelcontrol through deep reinforcement learning, V. Mnihet al., Nature, 2015.
· DeepLearning for Real-Time Atari Game Play Using Offline Monte-Carlo Tree SearchPlanning, X. Guo et al., NIPS, 2014.
· PlayingAtari with Deep Reinforcement Learning, V. Mnihet al., NIPS Workshop, 2013.
Continuous Control
· ContinuousDeep Q-Learning with Model-based Acceleration,Shixiang Gu et al., arXiv, 2016.
· AsynchronousMethods for Deep Reinforcement Learning, V. Mnihet al., arXiv, 2016.
· Memory-basedcontrol with recurrent neural networks, N.Heess et al., NIPS Workshop, 2015.
· VariationalInformation Maximisation for Intrinsically Motivated Reinforcement Learning, S.Mohamed and D. J. Rezende,arXiv, 2015.
· Continuouscontrol with deep reinforcement learning, T. P.Lillicrap et al., ICLR, 2016.
· LearningContinuous Control Policies by Stochastic Value Gradients, N.Heess et al., NIPS, 2015.
· LearningDeep Neural Network Policies with Continuous Memory States, M.Zhang et al., arXiv, 2015.
· High-DimensionalContinuous Control Using Generalized Advantage Estimation, J.Schulman et al., ICLR, 2016.
· End-to-EndTraining of Deep Visuomotor Policies, S.Levine et al., arXiv, 2015.
· DeepMPC:Learning Deep Latent Features for Model Predictive Control, I.Lenz, et al., RSS, 2015.
· DeterministicPolicy Gradient Algorithms, D. Silver etal., ICML, 2015.
· TrustRegion Policy Optimization, J. Schulman etal., ICML, 2015.
Text Domain
· StrategicDialogue Management via Deep Reinforcement Learning, H.Cuayáhuitl et al., NIPS Workshop, 2015.
· MazeBase:A Sandbox for Learning from Games, S.Sukhbaatar et al., arXiv, 2016.
· DeepReinforcement Learning with an Action Space Defined by Natural Language, J. Heet al., arXiv, 2015.
· GeneratingText with Deep Reinforcement Learning, H.Guo, arXiv, 2015.
· LanguageUnderstanding for Text-based Games Using Deep Reinforcement Learning, K.Narasimhan et al., EMNLP, 2015.
· Listen,Attend, and Walk: Neural Mapping of Navigational Instructions to ActionSequences, H. Mei et al., arXiv, 2015.
Visual Domain
· DeepExploration via Bootstrapped DQN, I.Osband et al., arXiv, 2016.
· ValueIteration Networks, A. Tamar etal., arXiv, 2016.
· AsynchronousMethods for Deep Reinforcement Learning, V. Mnihet al., arXiv, 2016.
· Masteringthe game of Go with deep neural networks and tree search, D.Silver et al., Nature, 2016.
· Increasingthe Action Gap: New Operators for Reinforcement Learning, M. G.Bellemare et al., AAAI, 2016.
· Memory-basedcontrol with recurrent neural networks, N.Heess et al., NIPS Workshop, 2015.
· How toDiscount Deep Reinforcement Learning: Towards New Dynamic Strategies, V.François-Lavet et al., NIPS Workshop, 2015.
· MultiagentCooperation and Competition with Deep Reinforcement Learning, A. Tampuuet al., arXiv, 2015.
· DuelingNetwork Architectures for Deep Reinforcement Learning, Z. Wanget al., arXiv, 2015.
· Actor-Mimic:Deep Multitask and Transfer Reinforcement Learning, E.Parisotto, et al., ICLR, 2016.
· BetterComputer Go Player with Neural Network and Long-term Prediction, Y. Tianet al., ICLR, 2016.
· PolicyDistillation, A. A. Rusu etat., ICLR, 2016.
· PrioritizedExperience Replay, T. Schaul etal., ICLR, 2016.
· DeepReinforcement Learning in Parameterized Action Space, M. Hausknechtet al., ICLR, 2016.
· TowardsVision-Based Deep Reinforcement Learning for Robotic Motion Control, F.Zhang et al., arXiv, 2015.
· VariationalInformation Maximisation for Intrinsically Motivated Reinforcement Learning, S.Mohamed and D. J. Rezende,arXiv, 2015.
· DeepReinforcement Learning with Double Q-learning, H. vanHasselt et al., arXiv, 2015.
· Continuouscontrol with deep reinforcement learning, T. P.Lillicrap et al., ICLR, 2016.
· Giraffe:Using Deep Reinforcement Learning to Play Chess, M.Lai, arXiv, 2015.
· Action-ConditionalVideo Prediction using Deep Networks in Atari Games, J. Ohet al., NIPS, 2015.
· LearningContinuous Control Policies by Stochastic Value Gradients, N.Heess et al., NIPS, 2015.
· DeepRecurrent Q-Learning for Partially Observable MDPs, M.Hausknecht and P. Stone, arXiv, 2015.
· IncentivizingExploration In Reinforcement Learning With Deep Predictive Models, B. C.Stadie et al., arXiv, 2015.
· High-DimensionalContinuous Control Using Generalized Advantage Estimation, J.Schulman et al., ICLR, 2016.
· End-to-EndTraining of Deep Visuomotor Policies, S.Levine et al., arXiv, 2015.
· UniversalValue Function Approximators, T.Schaul et al., ICML, 2015.
· MassivelyParallel Methods for Deep Reinforcement Learning, A. Nairet al., ICML Workshop, 2015.
· TrustRegion Policy Optimization, J. Schulman etal., ICML, 2015.
· Human-levelcontrol through deep reinforcement learning, V. Mnihet al., Nature, 2015.
· DeepLearning for Real-Time Atari Game Play Using Offline Monte-Carlo Tree SearchPlanning, X. Guo et al., NIPS, 2014.
· PlayingAtari with Deep Reinforcement Learning, V. Mnihet al., NIPS Workshop, 2013.
Robotics
· ContinuousDeep Q-Learning with Model-based Acceleration,Shixiang Gu et al., arXiv, 2016.
· AsynchronousMethods for Deep Reinforcement Learning, V. Mnihet al., arXiv, 2016.
· Memory-basedcontrol with recurrent neural networks, N.Heess et al., NIPS Workshop, 2015.
· TowardsVision-Based Deep Reinforcement Learning for Robotic Motion Control, F.Zhang et al., arXiv, 2015.
· LearningContinuous Control Policies by Stochastic Value Gradients, N. Heesset al., NIPS, 2015.
· LearningDeep Neural Network Policies with Continuous Memory States, M.Zhang et al., arXiv, 2015.
· High-DimensionalContinuous Control Using Generalized Advantage Estimation, J.Schulman et al., ICLR, 2016.
· End-to-EndTraining of Deep Visuomotor Policies, S.Levine et al., arXiv, 2015.
· DeepMPC:Learning Deep Latent Features for Model Predictive Control, I.Lenz, et al., RSS, 2015.
· TrustRegion Policy Optimization, J. Schulman etal., ICML, 2015.
Games
· DeepExploration via Bootstrapped DQN, I.Osband et al., arXiv, 2016.
· Learningto Communicate to Solve Riddles with Deep Distributed Recurrent Q-Networks, J. N.Foerster et al., arXiv, 2016.
· AsynchronousMethods for Deep Reinforcement Learning, V. Mnihet al., arXiv, 2016.
· Masteringthe game of Go with deep neural networks and tree search, D.Silver et al., Nature, 2016.
· Increasingthe Action Gap: New Operators for Reinforcement Learning, M. G.Bellemare et al., AAAI, 2016.
· How toDiscount Deep Reinforcement Learning: Towards New Dynamic Strategies, V.François-Lavet et al., NIPS Workshop, 2015.
· MultiagentCooperation and Competition with Deep Reinforcement Learning, A.Tampuu et al., arXiv, 2015.
· MazeBase:A Sandbox for Learning from Games, S.Sukhbaatar et al., arXiv, 2016.
· DuelingNetwork Architectures for Deep Reinforcement Learning, Z. Wanget al., arXiv, 2015.
· BetterComputer Go Player with Neural Network and Long-term Prediction, Y. Tianet al., ICLR, 2016.
· Actor-Mimic:Deep Multitask and Transfer Reinforcement Learning, E.Parisotto, et al., ICLR, 2016.
· PolicyDistillation, A. A. Rusu etat., ICLR, 2016.
· PrioritizedExperience Replay, T. Schaul etal., ICLR, 2016.
· DeepReinforcement Learning with an Action Space Defined by Natural Language, J. Heet al., arXiv, 2015.
· DeepReinforcement Learning in Parameterized Action Space, M.Hausknecht et al., ICLR, 2016.
· VariationalInformation Maximisation for Intrinsically Motivated Reinforcement Learning, S.Mohamed and D. J. Rezende,arXiv, 2015.
· DeepReinforcement Learning with Double Q-learning, H. vanHasselt et al., arXiv, 2015.
· Continuouscontrol with deep reinforcement learning, T. P.Lillicrap et al., ICLR, 2016.
· LanguageUnderstanding for Text-based Games Using Deep Reinforcement Learning, K. Narasimhanet al., EMNLP, 2015.
· Giraffe:Using Deep Reinforcement Learning to Play Chess, M.Lai, arXiv, 2015.
· Action-ConditionalVideo Prediction using Deep Networks in Atari Games, J. Ohet al., NIPS, 2015.
· DeepRecurrent Q-Learning for Partially Observable MDPs, M.Hausknecht and P. Stone, arXiv, 2015.
· IncentivizingExploration In Reinforcement Learning With Deep Predictive Models, B. C.Stadie et al., arXiv, 2015.
· UniversalValue Function Approximators, T.Schaul et al., ICML, 2015.
· MassivelyParallel Methods for Deep Reinforcement Learning, A. Nairet al., ICML Workshop, 2015.
· TrustRegion Policy Optimization, J. Schulman etal., ICML, 2015.
· Human-levelcontrol through deep reinforcement learning, V. Mnihet al., Nature, 2015.
· DeepLearning for Real-Time Atari Game Play Using Offline Monte-Carlo Tree SearchPlanning, X. Guo et al., NIPS, 2014.
· PlayingAtari with Deep Reinforcement Learning, V. Mnihet al., NIPS Workshop, 2013.
Monte-Carlo Tree Search
· Masteringthe game of Go with deep neural networks and tree search, D.Silver et al., Nature, 2016.
· BetterComputer Go Player with Neural Network and Long-term Prediction, Y. Tianet al., ICLR, 2016.
· DeepLearning for Real-Time Atari Game Play Using Offline Monte-Carlo Tree SearchPlanning, X. Guo et al., NIPS, 2014.
Inverse ReinforcementLearning
· MaximumEntropy Deep Inverse Reinforcement Learning, M.Wulfmeier et al., arXiv, 2015.
Transfer Learning
· Actor-Mimic:Deep Multitask and Transfer Reinforcement Learning, E.Parisotto, et al., ICLR, 2016.
· PolicyDistillation, A. A. Rusu etat., ICLR, 2016.
· ADAAPT:A Deep Architecture for Adaptive Policy Transfer from Multiple Sources, J.Rajendran et al., arXiv, 2015.
· UniversalValue Function Approximators, T.Schaul et al., ICML, 2015.
Improving Exploration
· DeepExploration via Bootstrapped DQN, I.Osband et al., arXiv, 2016.
· Action-ConditionalVideo Prediction using Deep Networks in Atari Games, J. Ohet al., NIPS, 2015.
· IncentivizingExploration In Reinforcement Learning With Deep Predictive Models, B. C.Stadie et al., arXiv, 2015.
Multi-Agent
· Learningto Communicate to Solve Riddles with Deep Distributed Recurrent Q-Networks, J. N.Foerster et al., arXiv, 2016.
· MultiagentCooperation and Competition with Deep Reinforcement Learning, A.Tampuu et al., arXiv, 2015.
Share Http URL: http://www.wittx.cn/get_news_message.do?new_id=173

Best Last Month

Information industry by wittx
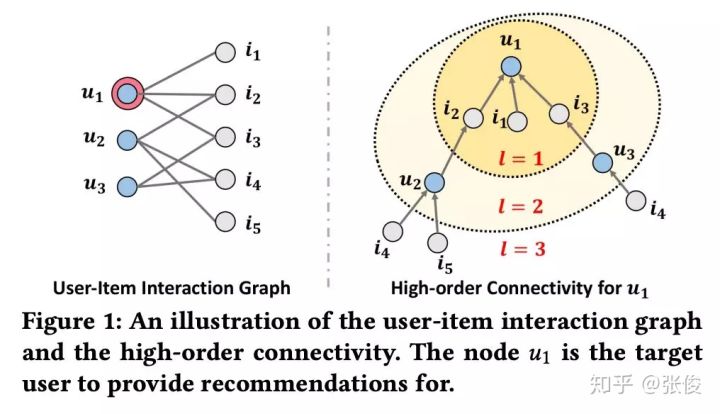
Information industry by wittx

Information industry by wittx

Information industry by wittxAn autonomous laboratory for the accelerated synthesis of novel materials

Information industry by wittx

Information industry by show

Information industry by wittx
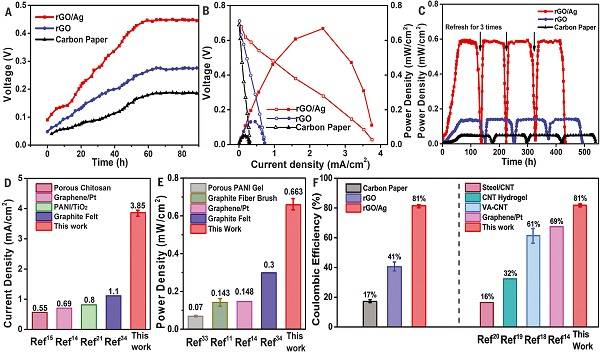
Information industry by wittx

Information industry by wittx

Information industry by wittx
