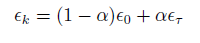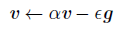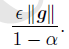-
News Message
DeepLearning之优化方法
- by wittx 2020-09-04
一.最基本的优化算法
1.1SGD
在这里SGD和min-batch是同一个意思,抽取m个小批量(独立同分布)样本,通过计算他们平梯度均值。后面几个改进算法,均是采用min-batch的方式。
先上一些结论:
- 1.SGD应用于凸问题时,k次迭代后泛化误差的数量级是O(1/sqrt(k)),强凸下是O(1/k)。
- 2.理论上GD比SGD有着更好的收敛率,然而[1]指出,泛化误差的下降速度不会快于O(1/k)。鉴
- 于SGD只需少量样本就能快速更新,这远超过了缓慢的渐进收敛,因此不值得寻找使用收敛快O(1/k)。
- 3.可能由于SGD在学习中增加了噪声,有正则化的效果
- 4.在某些硬件上使用特定大小的数组时,运行时间会更少。尤其是在使用GPU时,通常使用2 的幂
- 数作为批量大小可以获得更少的运行时间。一般,2 的幂数的取值范围是32 到256,16 有时在尝试大模型时使用。
- 5.如果批量处理中的所有样本可以并行地处理(通常确是如此),那么内存消耗和批量大小会
- 正比。对于很多硬件设施,这是批量大小的限制因素
再看看算法:
没啥太大难度,需要注意的是有必要随迭代步数,逐渐降低学习率。一种常见从做法是线性衰减学习率,直到
次迭代:
其中在
之后,学习率一般保持常数
1.2Momentum(动量)
先上结论:
1.动量方法主要是为了解决Hessian矩阵病态条件问题(直观上讲就是梯度高度敏感于参数空间的某些方向)的。
2.加速学习
3.一般将参数设为0.5,0.9,或者0.99,分别表示最大速度2倍,10倍,100倍于SGD的算法。
4.通过速度v,来积累了之间梯度指数级衰减的平均,并且继续延该方向移动:
再看看算法:
动量算法直观效果解释:
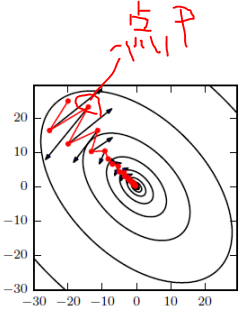
如图所示,红色为SGD+Momentum。黑色为SGD。可以看到黑色为典型Hessian矩阵病态的情况,相当于大幅度的徘徊着向最低点前进。
而由于动量积攒了历史的梯度,如点P前一刻的梯度与当前的梯度方向几乎相反。因此原本在P点原本要大幅徘徊的梯度,主要受到前一时刻的影响,而导致在当前时刻的梯度幅度减小。
直观上讲就是,要是当前时刻的梯度与历史时刻梯度方向相似,这种趋势在当前时刻则会加强;要是不同,则当前时刻的梯度方向减弱。从另一个角度讲:
要是当前时刻的梯度与历史时刻梯度方向相似,这种趋势在当前时刻则会加强;要是不同,则当前时刻的梯度方向减弱。
假设每个时刻的梯度g总是类似,那么由我们可以直观的看到每次的步长为:
即当设为0.5,0.9,或者0.99,分别表示最大速度2倍,10倍,100倍于SGD的算法。1.3Nesterov(牛顿动量)
先上结论:
1.Nesterov是Momentum的变种。
2.与Momentum唯一区别就是,计算梯度的不同,Nesterov先用当前的速度v更新一遍参数,在用更新的临时参数计算梯度。
3.相当于添加了矫正因子的Momentum。
4.在GD下,Nesterov将误差收敛从O(1/k),改进到O(1/k^2)
5.然而在SGD下,Nesterov并没有任何改进
具体算法如下所示:
二.自适应参数的优化算法
这类算法最大的特点就是,每个参数有不同的学习率,在整个学习过程中自动适应这些学习率。
2.1AdaGrad
先上结论:
- 1.简单来讲,设置全局学习率之后,每次通过,全局学习率逐参数的除以历史梯度平方和的平方根,使得每个参数的学习率不同
- 2.效果是:在参数空间更为平缓的方向,会取得更大的进步(因为平缓,所以历史梯度平方和较小,对应学习下降的幅度较小)
- 3.缺点是,使得学习率过早,过量的减少
- 4.在某些模型上效果不错。
具体见算法:
2.2RMSProp
先上结论
1.AdaGrad算法的改进。鉴于神经网络都是非凸条件下的,RMSProp在非凸条件下结果更好,改变梯度累积为指数衰减的移动平均以丢弃遥远的过去历史。
2.经验上,RMSProp被证明有效且实用的深度学习网络优化算法。
相比于AdaGrad的历史梯度:
RMSProp增加了一个衰减系数来控制历史信息的获取多少:再看原始的RMSProp算法:
再看看结合Nesterov动量的RMSProp,直观上理解就是:
RMSProp改变了学习率,Nesterov引入动量改变了梯度,从两方面改进更新方式。2.3Adam
先上结论:
1.Adam算法可以看做是修正后的Momentum+RMSProp算法
2.动量直接并入梯度一阶矩估计中(指数加权)
3.Adam通常被认为对超参数的选择相当鲁棒
4.学习率建议为0.001
再看算法:其实就是Momentum+RMSProp的结合,然后再修正其偏差。
三.二阶近似的优化算法
二阶近似作为早期处理神经网络的方法,在此并不另起blog展开细讲。
3.1牛顿法
牛顿法是基于二阶泰勒级数展开在某点附近来近似损失函数的优化方法。主要需要求得Hessian矩阵的逆。如果参数个数是k,则计算你所需的时间是O(k^3)由于在神经网络中参数个数往往是巨大的,因此牛顿法计算法消耗时间巨大。
具体更新公式如下:
3.2共轭梯度法
共轭梯度(CG)是通过迭代下降的共轭方向(conjugate directions)以有效避免Hessian 矩阵求逆计算的方法。3.3BFGS
Broyden-Fletcher-Goldfarb-Shanno(BFGS)算法具有牛顿法的一些优点,但没有牛顿法的计算负担。在这方面,BFGS和CG 很像。然而,BFGS使用了一个更直接的方法近似牛顿更新。用矩阵Mt 近似逆,迭代地低秩更新精度以更好地近似Hessian的逆。3.4L-BFGS
存储受限的BFGS(L-BFGS)通过避免存储完整的Hessian 逆的近似矩阵M,使得BFGS算法的存储代价显著降低。L-BFGS算
Share Http URL: http://www.wittx.cn/get_news_message.do?new_id=155

Best Last Month
Information industry by 未注册用户发布
Information industry by wittx

Information industry by wittx

Information industry by wittx
Information industry by wittx
Information industry by wittx
Information industry by wittxMulti-agent Policy Optimization with Approximatively Synchronous Advantage Estimation
Information industry by wittx

Information industry by wittx

Information industry by show