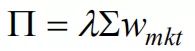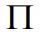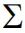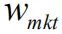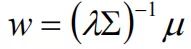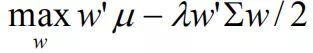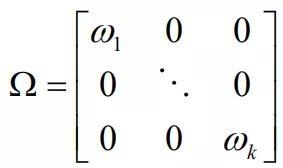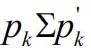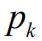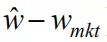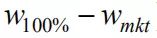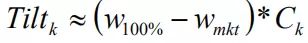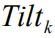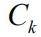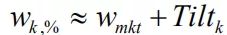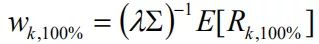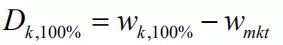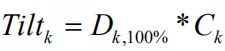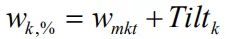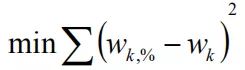-
News Message
Black-Litterman模型介绍
- by wittx 2020-09-04
- BL模型的主要过程是计算E[R]。
- BL模型存在很多不确定的细节。
- 隐含均衡收益(Π)是BL模型的起点,产生Π是反向优化过程,产生权重w是优化过程。产生Π要经过计算风险厌恶系数,计算收益率方差,计算市值权重,代入公式计算Π四步。
- 控制BL模型中观点权重和隐含均衡收益权重的两个参数τ和Ω,都是较难计算的,这是BL模型最大的难点。
- BL模型主要包含计算Π,设置观点,计算E[R],计算新权重四步。
- 计算新权重用到的方法是找到权重和新收益率向量的关系,代入效用函数,求效用函数的最大值。
- 一个观点可能带来所有资产期望收益率的变化,但是只能带来观点包含的资产权重的变化,这是BL模型的一个重要性质。
- 产生P的方法有多个,考虑市值权重大小的方法是相对较好的一个。
- 广义上讲,BL模型产生的新组合,可以看做两个组合的叠加,一个是市场组合,一个是观点产生的小的多空头寸。
- 绝对观点可能造成组合的权重之和不等于1。
- 投资经理收到很多观点时,可以根据分析师信息系数来确定其可信度。
- 通过隐含可信度,可以将更多的影响信息包含到观点可信度的计算中。
引言
BLACK-LITTERMAN模型(简称BL模型)比较复杂,解决了MVO的一些问题。BL模型使用贝叶斯方法将投资者观点和市场隐含信息结合,产生一个新的混合的期望收益率估计值。用这个收益率向量去生成组合,会得到比较直观的权重。但不幸的是,产生模型输入很复杂且文章没有透彻得解释这个过程。
文章第一部分列举MVO的非直观性,并通过反向优化解决了这个问题。第二部分具体说明模型和输入参数构建。第三部分是讲观点可信度。
一.期望收益率
BL模型可以根据投资者观点产生稳定的均值方差有效投资组合,这克服了MVO不直观的问题,也缓解了误差放大的问题。
MVO方法的最重要输入是期望收益率向量,Best和Grauer揭示了很小的收益率变动就会带来大幅的资产权重变化。为了找到一个合适的期望收益率,Black、Litterman、He 等学者提出了一些预测方法,如历史收益率,等价平均收益率,风险调整等价平均收益率。他们发现这些方法都会导致极端组合:在无限制时,组合的有很高的做空做多权重;加入不允许做空的限制后,组合又在几类资产上发生了集中。
1.反向优化
BL模型以均衡收益为起点,均衡收益的公式是
(公式1)。
其中,
:隐含均衡超额收益率向量(nx1);
:风险厌恶系数;
:超额收益率的方差矩阵(nxn);
:市值权重。
风险厌恶系数反映了收益和风险的权衡。是一个比例,在这个比例上投资者会牺牲收益去追求更低的风险。在反向优化的过程中,厌恶系数是估算超额收益的比例因子;反向优化的超额收益根据权重加和,就是市场的风险溢价。单位风险的更大超额收益(更大的风险厌恶系数),将导致更大的超额收益估计值。
下面举了8个资产类别的例子说明模型,为了使文章篇幅不至于太大,没有将现金资产包含进来。
表一列举了八类资产的四种超额收益,第一个CAPM超额收益向量是根据GSMI计算;第二个CAPM超额收益向量是根据隐含beta和市值加权组合计算的,被称作隐含均衡收益向量。
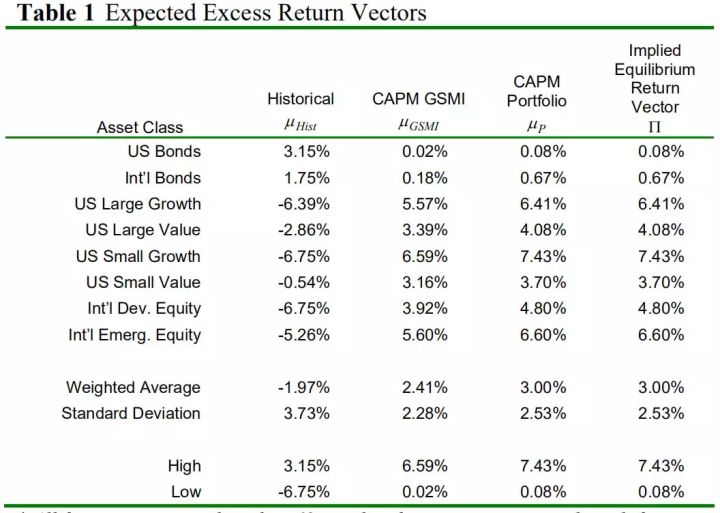
表1 收益率表 表1的四个值都是基于60个月对无风险利率的超额收益的估算,CAPM超额收益是基于3的风险溢价,用风险溢价除以市场(基准)超额收益的方差,得到的风险厌恶系数为3.07(基准厌恶系数)。
可以看出,历史收益向量的标准差和范围比较大,第一个CAPM收益向量和隐含均衡收益向量很接近(相关性高)。
用μ(代表任何超额收益向量)代替公式1中的∏(代表隐含均衡收益向量),并对公式进行变换,就得到了
(公式2)。问题就转换为了无约束条件下求最大值得问题:
(效用函数)。
表2是用公式2计算的计算的表1中三个投资组合的各个权重,市值权重是最后一列。
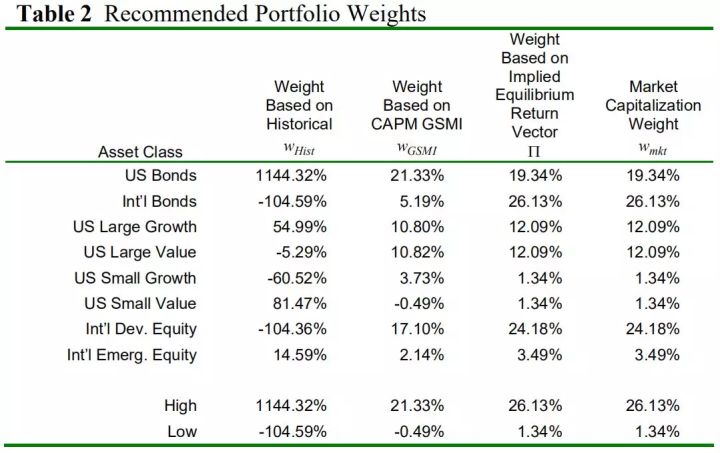
表2 权重表 果不其然,用历史收益率得到的权重非常极端。对MVO不了解的人,可能以为相似的收益率计算的权重也相似,但是CAPM GSMI收益和市场隐含均衡收益计算的权重,差异很大。因为求隐含均衡收益是求权重的逆向过程,所以根据隐含均衡收益求得的权重就是市值权重。如果收益观点同市场隐含均衡收益相同,那可以直接持有市场组合。BL模型市场中性的起点就是隐含均衡收益(Π)。
二.Black-Litterman模型
1.公式
开始详细介绍前,有必要先看一下BL模型的公式并对各参数进行简单解释。本文公式中的,K代表观点个数,N代表资产类别个数。 综合期望收益(E[R])的公式是
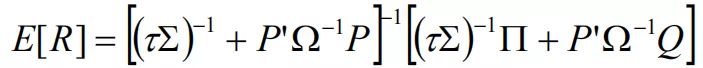
。
其中,
E[R]:综合期望收益率向量(Nx1)
τ:比例系数
∑:超额收益的方差矩阵
P:表示各资产与看法的矩阵(KxN)
Ω:观点误差项的方差矩阵,是对角矩阵,因为观点之间相互独立。代表了观点的可信度(KxK)
Q:具体看法向量(Kx1)
2.投资者观点
通常,投资者可能资产收益率的看法,与隐含均衡收益率不一样。BL模型可以将这种观点以相对或者绝对的形式进行表达。以下是用 Black和Litterman (1990)形式表达的三个例子。
观点一:国际发达国家股票有5.25%的绝对超额收益(观点可信度为25%)
观点二:国际债券的收益超过美国债券25个基点(观点可信度为50%)
观点三:美国成长股收益超过美国价值股收益2%(观点可信度为65%)
观点一是相对观点的例子,从表一可知,国际发达国家股票的隐含均衡收益率是4.8%,低于观点45个基点。
观点二、三是绝对观点的例子,相对观点更接近投资经理的真实观点。观点二认为国际债券的收益超过美国债券0.25%。确定这个观点带来的影响,要根据历史均衡收益来看。从表一可知,国际债券的收益超过美国债券0.59%,但是观点认为是0.25%。因此持有这个观点的人应该更倾向于美国债券,
观点三是包含多个资产的相对观点。表现好和差都是相对的,因此好和差的数量要匹配。观点产生了两个小的投资组合,一个做多一个做空。表现好的相对权重(我理解应该是观点认为表现好的资产的新单个权重除以所有表现好的资产的新权重之和),应该和单个资产的市值与所有观点认为表现好的资产市值之和的比例相同。表现差的也是这样。净多头和空头头寸应该相同。
观点三认为美国成长股收益超过美国价值股收益2%。美国大小市值成长股表现好,美国大小市值价值股表现差。表3a和3b分别是小多头组合和空头组合的加权平均收益率收益率。
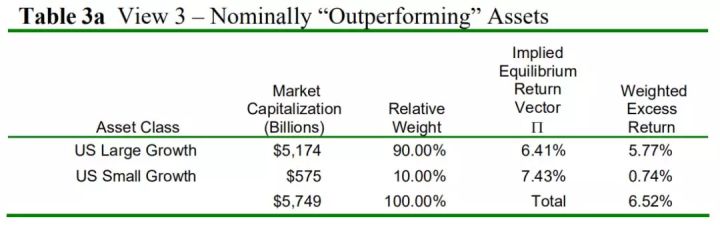
表3a 多头小组合 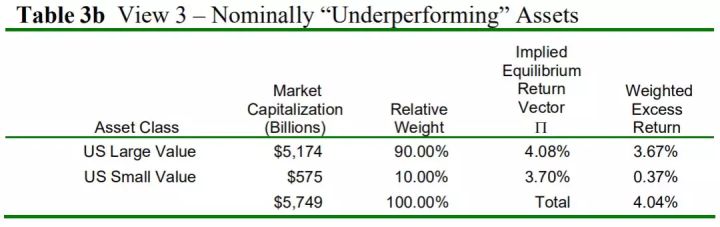
表3b 空头小组合 用和观点二相同的分析,可知观点三倾向于配置更多价值股。
3.构建输入
BL模型的一个难点是将以上观点转化为模型可使用的输入。首先,投资者不必对每类资产都有观点,因为前面有三个观点,因此观点向量Q是3x1的向量。观点的不确定性导致随机、未知、独立、正态的误差向量(ε),其均值为0,方差矩阵为Ω。因此一个观点的形式就是Q +ε。
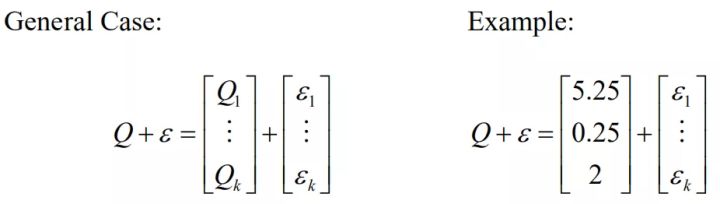
除非洞察力很强的投资者对观点的信心是100%,否则误差项ε就不是0。误差项ε不直接进入BL模型。但是每个误差项的方差ω进入模型。所有ω构成了Ω(对角线为各ω)。ω代表观点的不确定性,ω越大越不确定。
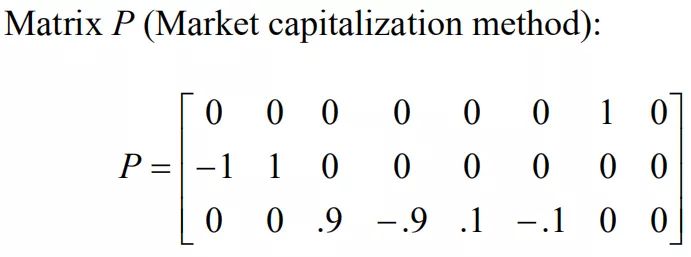
计算ω并得到Ω是模型最复杂的事情之一,在第三部分将详细讨论。Q中的观点通过矩阵P与各资产结合起来。以下是上边例子中的P。

相对观点中表现好和差的之和是0。 产生P的方法有多个,Litterman提出百分比的方法,但是Satchell和Scowcroft用等值权重方法去生成相对观点的元素,表现好的或差的单个元素是1除以全部资产个数。但这个方法忽略了市值影响,可能会造成一些跟踪误差。
论文作者更倾向于用Litterman的方法,因为大市值股票的市值权重差不多是小市值股票的9倍,所以P如下。
P被定义后,就可以计算观点方差了。每个观点的方差是
,其中
是从P而来的1xN的第k个观点的向量,Σ是超额收益的方差矩阵。方差如表4。方差矩阵是观点可靠性的依据,一会将用于计算误差项的方差ω。
从概念上看,BL模型是复杂的,因为要将Π和Q加权平均,相对权重是τ和Ω的函数。不幸的是τ和Ω都很抽象且难确定。可信度高,新收益率向量接近观点;可信度低,新收益率向量接近市场隐含均衡收益。
τ多少和市场隐含均衡收益产生的相对权重成反比。但是论文中基本没介绍τ。Black、Litterman 、Lee都认为均值的不确定性小收益不确定性,所以τ接近0。均衡收益比历史收益稳定。
Lee认为τ在0.01到0.05,并且用目标跟踪误差校准了模型。相反的,
Satchell和Scowcroft认为τ通常设为1。Blamont和Firoozye认为τΣ是Π估计值的标准误,因此τ接近1除以观测值(不太理解)。
在无限制情况下,如果观点是市场均衡观点,那BL模型的推荐组合就是市场组合。如果有不同观点,那么组合对市场组合的偏离程度由τ除以ω的比例决定。
最简便的校准模型的方法是假设τ的值。He和Litterman校准ω/τ以等于观点方差。设τ = 0.025 并且用表4中的观点组合方差得到了Ω的如下形式:

这样计算Ω时,τ的值无关紧要,因为ω/τ进入模型。τ变化会引起Ω的变化,但是不会引起E[R]的变化。
4.计算新的收益率向量
指定τ和Ω以后,所有输入都已确定,可以计算E[R]了。综合隐含收益和观点的方式如图1所示。新的建议权重根据公式2进行无约束最大化产生。Σ是表4。
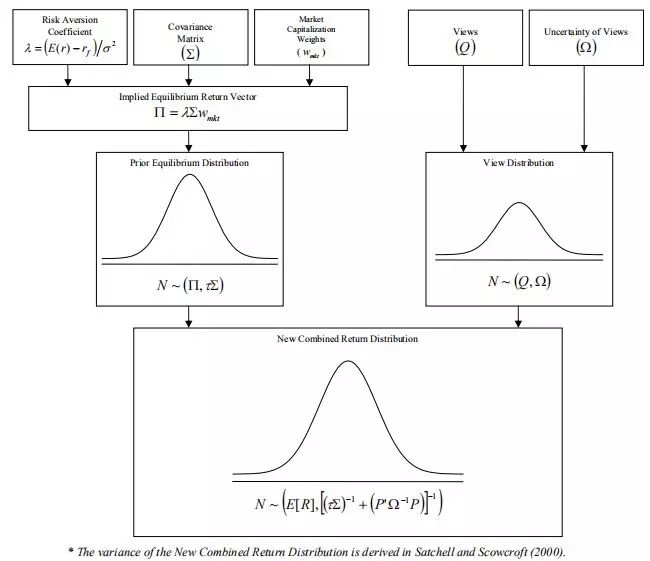
图1 E[R]产生过程 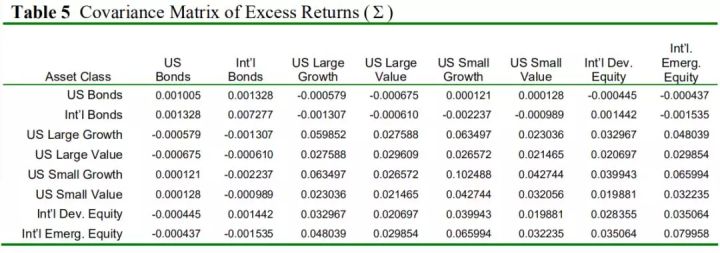
表5 超额收益协方差表 尽管观点只是直接影响了8个资产中的7个,但是每个资产的收益都发生了变化。一个观点就可以影响所有收益,因为单个收益通过协方差与其他收益相关。
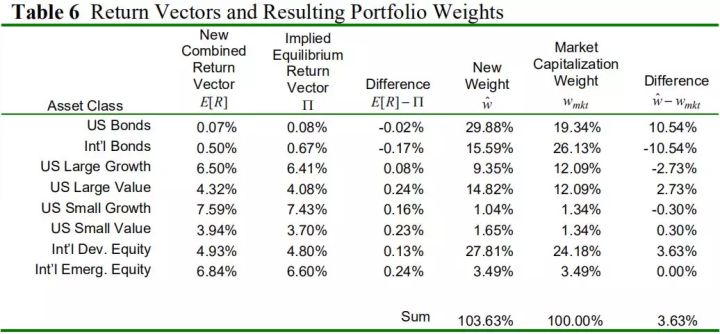
表6 收益和权重 BL模型的一个重要特征就是表6最后一列所示,只有7个资产的权重发生了变化,观点未覆盖的资产,权重没变。
广义上讲,BL模型产生的新组合,可以看做两个组合的叠加,一个是市场组合,一个是观点产生的小的多空头寸。因为相对观点的多空头寸抵消,所以不会带来权重之和的变化。而绝对观点,就像观点一,由于没有抵消头寸,所以导致了整体权重之和1。
加限制条件后,BL模型的直观性会降低。
2.5模型微调(此部分开头没太看懂,如果需要得再看)
可以通过研究E[R]微调BL模型,主要是计算预期收益-风险特性,并调整τ和ω。
Bevan和Winkelmann给出了设置Q权重的方法。在得到E[R]和新权重以后,计算组合的信息比率。给出建议最高的信息比率为2.0,当组合信息比率高于2.0时,削减Q的权重(降低τ,保持Ω)。
然后要看观点是不是会导致异常情况,如希望权重和为1的投资者,一般抛弃绝对观点。
投资经理收到很多观点时,可以根据分析师信息系数来确定其可信度。投资者应该使用尽量准确的方法是计算收益协方差矩阵。
三.一种新的指定可信度的方法
根据前边讨论,Ω是BL模型中最复杂的参数。不幸的是,这个参数怎么设定还不是很确定。Herold认为,BL模型的最大难度是要求使用者要给出各个观点的概率密度函数,这使得BL模型只能被定量用户所使用。本部分介绍了一个指定观点隐含可信度并整合用户指定的从0到100%的可信度去产生Ω的方法,这解决了τ不好计算的问题。
1.隐含可信度
前边方法,ω由观点组合方差和τ的乘积得到,但是除了观点组合方差外可能还有别的信息影响观点可信度。观点提出后,可以给出一个直觉可信度。一些其他因素可能影响投资者对观点的信心,比如历史准确率和模型得分,检查分析产生观点的过程,观点和隐含均衡收益之间的差异等,这些都和观点组合方差一看影响观点置信水平。考虑这些后将使BL模型最大化投资者的观点。
将Ω的对角线元素都设为1等于各观点都100%的确信。其他条件相同的情况下,这样做将产生与市场组合偏差最大的组合。此时,BL模型公式是
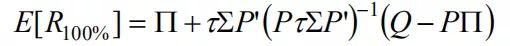
(公式9)。将这个组合同市场组合、前面BL模型组合的权重放到一块,如图2。
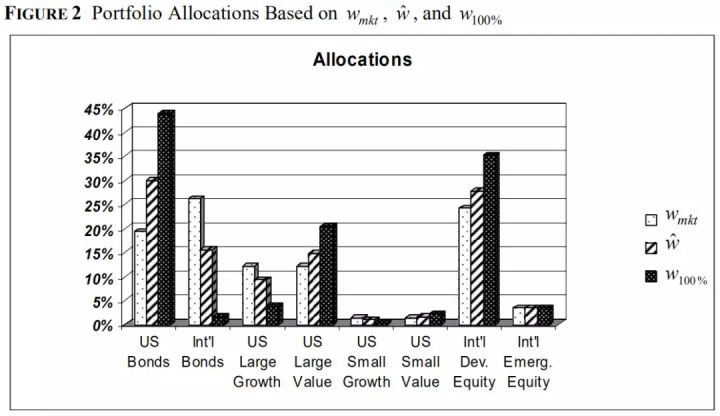
图2 三个组合的权重对比 隐含可信度可以用
除以
计算。前边三个观点的计算情况如表7。
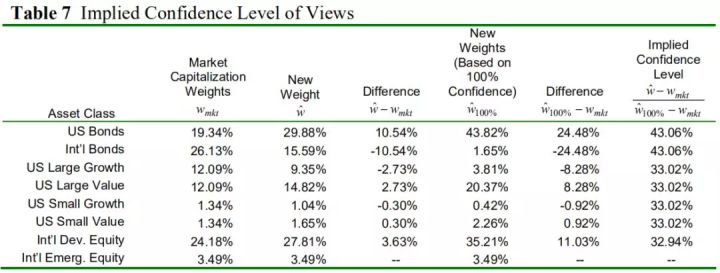
表7 隐含可信度 根据隐含可信度,可以计算新的E[R]和权重。
2.新的直观方法
Ω由用户指定可信度和组合倾向构成。倾向公式是
。
其中,
:第k个观点带来的倾向向量(Nx1)
:第k个观点的可信度。
如果不考虑其他观点,一个观点产生的新权重为
。
计算ω过程的步骤如下。
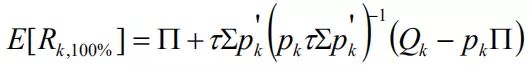
计算参数ω是的左式最小,其中
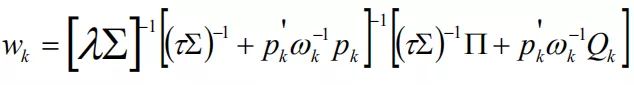
- 产生Ω后,根据公式3计算E[R]。
这个过程将τ设为固定值并没有影响E[R],解决了计算τ较难的问题。尽管产生Ω的这个过程相对复杂,但是好处是可以用0到100%置信度去计算Ω。通过这个方法,抽象的数学参数得到了计算,BL模型的便利也更容易被投资者获得。
结论
BL模型产生的E[R]可以带来直观的分散的投资组合。控制BL模型中观点权重和隐含均衡收益权重的两个参数τ和Ω,都是较难计算的。假设观点可信度100%可以去计算观点隐含可信度。在隐含可信度框架下,一个新的计算E[R]的 方法被提出。BL模型消除了MVO的一些缺点,使得我们可以更好使用马科维茨公式。加入投资者观点,提升了BL模型的直观性和可信度。
Share Http URL: http://www.wittx.cn/get_news_message.do?new_id=140

Best Last Month
Information industry by wittx

Information industry by wittx
Information industry by wittx
Electronic electrician by wittx
Computer software and hardware by wittx
Information industry by wittx

Information industry by wittx

Information industry by wittx
Information industry by wittx
Information industry by wittx