
-
News Message
离散选择模型
- by wittx 2020-09-04
1. 为什么是Logistic回归?
在分析变量之间的相关关系的时候,一般最先想到的是线性回归模型。例如,图1展示了气温(
 )和冰淇淋的销量(
)和冰淇淋的销量(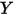 )之间的关系:
)之间的关系: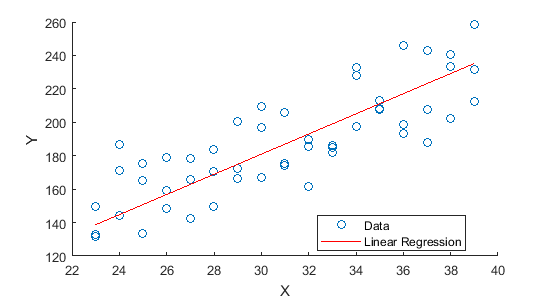
图1:气温(
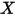 )和冰淇淋的销量(
)和冰淇淋的销量(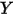 )之间的关系
)之间的关系线性回归模型可以描述因变量
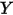 和自变量
和自变量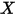 之间的相关关系。考虑最简单的、自变量的个数为 1 的情形。记第
之间的相关关系。考虑最简单的、自变量的个数为 1 的情形。记第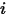 次观测到的样本为
次观测到的样本为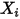 ,则:
,则: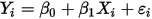
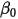 为
为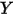 轴上的截距,
轴上的截距,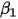 为斜率,
为斜率,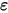 为误差项。为什么需要将误差项
为误差项。为什么需要将误差项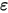 包含在模型中?
包含在模型中?- 有些变量是观测不到或者无法度量的,又或者影响因变量的因素太多,无法一一度量
- 外界随机因素对的影响很难模型化,如自然灾害、恐怖时间、设备故障等
- 在度量的过程中会发生偏差
给定
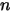 组观测值
组观测值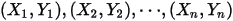 ,我们就可以用最小二乘法得到参数
,我们就可以用最小二乘法得到参数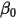 和
和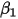 的估计值。
的估计值。现实情况中经常会遇到因变量是二分类变量的情形。例如——
- 顾客是否会购买某种商品:Y=1购买,Y=0不买
- 选民是否会投票给某位候选人:Y=1投票,Y=0不投票
- 求职者决定是否在某企业入职:Y=1入职,Y=0不入职
- 交通事故中是否有人员伤亡:Y=1有人员伤亡,Y=0无人员伤亡
若因变量为二分类变量(Y只能取0或1),在建模分析与Y相关的影响因素的时候,使用Logistic回归可能是一个较好的选择;而直接利用线性回归模型进行拟合可能会得到错误的结果。这主要是因为二分类变量违背了线性回归模型的一些假设条件。
2. 线性回归模型的假设
线性回归模型的成立需满足以下几条假设[1]:
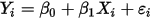 ...... (1)
...... (1)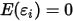 ...... (2)
...... (2)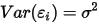 ...... (3)
...... (3)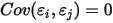 ...... (4)
...... (4)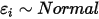 ...... (5)
...... (5)条件(1)为线性假设,即自变量
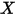 每增加一个单位对
每增加一个单位对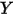 的影响都是一样的(
的影响都是一样的(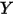 的值增加
的值增加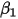 );
);条件(2)-(5)均和误差项
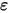 有关。假设(2)表示对任意
有关。假设(2)表示对任意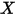 的取值,误差项
的取值,误差项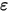 是一个期望为零的随机变量(即
是一个期望为零的随机变量(即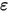 和
和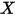 不相关)。这意味着在式
不相关)。这意味着在式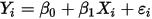 中,由于
中,由于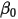 和
和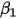 都是常数,因此对于一个给定的
都是常数,因此对于一个给定的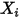 的值,
的值,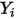 的期望值为:
的期望值为: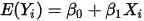 ...... (6)
...... (6)假设(3)表示对任意
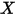 的值,误差项
的值,误差项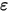 的方差都相同(都是
的方差都相同(都是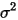 )。
)。假设(4)和(5)说明误差项
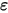 是一个服从正态分布的随机变量(
是一个服从正态分布的随机变量(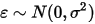 ),且相互独立(即
),且相互独立(即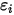 和
和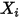 不相关)。图2展示了误差项
不相关)。图2展示了误差项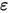 在线性回归模型中的影响。
在线性回归模型中的影响。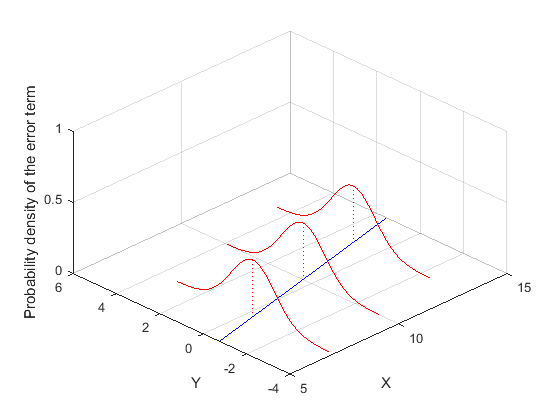
图2:误差项在线性回归模型中的影响
只有当以上5个基本条件都满足时,利用最小二乘法得出的参数的估计值才是无偏的。不幸的是,因变量是二分类变量时,无法满足条件(3)和(5)。以下分别予以说明。
首先考虑假设条件(5)。
当因变量
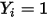 时,根据条件(1)则有:
时,根据条件(1)则有: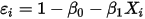 ...... (7)
...... (7)当因变量
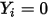 时有:
时有: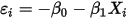 ......(8)
......(8)也就是说,对任意的
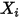 ,误差项
,误差项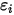 只能取两个固定的值:
只能取两个固定的值: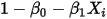 或者
或者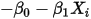 ——而非如图2中所示的正态分布。因此条件(5)不满足。
——而非如图2中所示的正态分布。因此条件(5)不满足。再考虑假设条件(3)。
若记
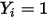 的概率值为
的概率值为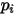 ,则相应的
,则相应的 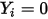 的概率为
的概率为 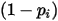 ,如下表所示:
,如下表所示: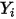 的均值为:
的均值为: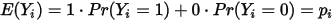 ...... (9)
...... (9)带入(6)可得:
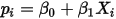 ...... (10)
...... (10)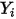 的方差为:
的方差为:![Var(Y_i )=E[(Y_i )^2 ]-[E(Y_i )]^2](/Witty_Finance/images/download/1553769984932_79946.png)
 ...... (11)
...... (11)当
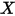 在
在 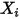 处固定时,
处固定时, 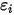 方差等于相应的
方差等于相应的 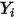 的方差(见(1)式)。也是说,
的方差(见(1)式)。也是说,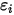 的方差随着
的方差随着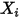 的改变而改变——这与(3)式相矛盾!
的改变而改变——这与(3)式相矛盾!由此可见,直接套用(1)式中的线性回归模型对二分类变量(
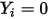 or
or 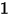 )进行拟合时,自变量的系数估计值会存在偏差。更为关键的一点是:从(10)中可以看出,当假设条件(1)、(2)成立时,
)进行拟合时,自变量的系数估计值会存在偏差。更为关键的一点是:从(10)中可以看出,当假设条件(1)、(2)成立时,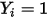 的概率值(
的概率值(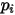 )和自变量
)和自变量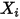 成线性关系——这就意味着概率值
成线性关系——这就意味着概率值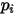 可能会出现大于1(或者小于0)的情形(如图3)——这一点无论是在理论上还是在实际计算的过程都行不通!因此,在处理因变量为二分类变量的情形时,较线性模型而言,Logistic模型的统计特性更好、计算更为方便。
可能会出现大于1(或者小于0)的情形(如图3)——这一点无论是在理论上还是在实际计算的过程都行不通!因此,在处理因变量为二分类变量的情形时,较线性模型而言,Logistic模型的统计特性更好、计算更为方便。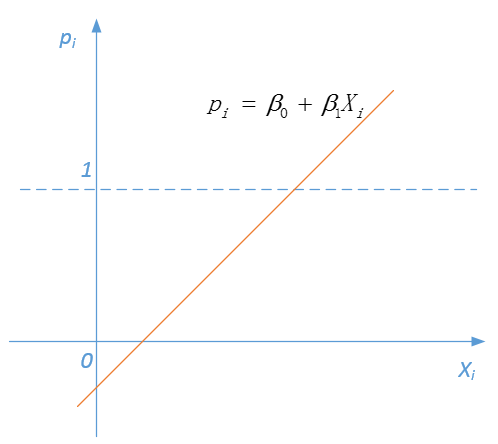
图3:线性概率模型
预告:下一篇讲Logistic模型中的一个核心概念——Odds。
3. 参考文献:
[1] Allison, Paul D. Logistic Regression
Using SAS®: Theory and Application, Second Edition. Copyright © 2012, SAS
Institute Inc., Cary, North Carolina, USA.
1. 为什么是Logistic回归?
在分析变量之间的相关关系的时候,一般最先想到的是线性回归模型。例如,图1展示了气温(
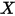 )和冰淇淋的销量(
)和冰淇淋的销量(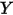 )之间的关系:
)之间的关系: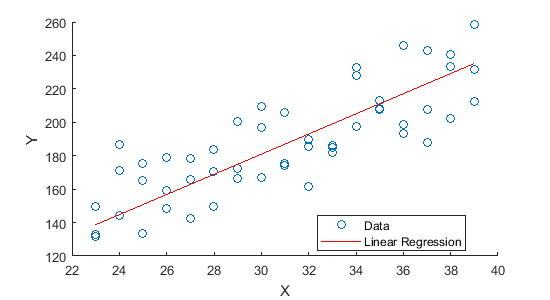
图1:气温(
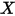 )和冰淇淋的销量(
)和冰淇淋的销量(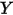 )之间的关系
)之间的关系线性回归模型可以描述因变量
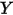 和自变量
和自变量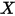 之间的相关关系。考虑最简单的、自变量的个数为 1 的情形。记第
之间的相关关系。考虑最简单的、自变量的个数为 1 的情形。记第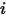 次观测到的样本为
次观测到的样本为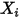 ,则:
,则: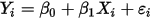
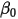 为
为 轴上的截距,
轴上的截距,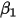 为斜率,
为斜率,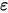 为误差项。为什么需要将误差项
为误差项。为什么需要将误差项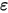 包含在模型中?
包含在模型中?- 有些变量是观测不到或者无法度量的,又或者影响因变量的因素太多,无法一一度量
- 外界随机因素对的影响很难模型化,如自然灾害、恐怖时间、设备故障等
- 在度量的过程中会发生偏差
给定
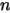 组观测值
组观测值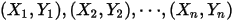 ,我们就可以用最小二乘法得到参数
,我们就可以用最小二乘法得到参数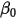 和
和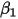 的估计值。
的估计值。现实情况中经常会遇到因变量是二分类变量的情形。例如——
- 顾客是否会购买某种商品:Y=1购买,Y=0不买
- 选民是否会投票给某位候选人:Y=1投票,Y=0不投票
- 求职者决定是否在某企业入职:Y=1入职,Y=0不入职
- 交通事故中是否有人员伤亡:Y=1有人员伤亡,Y=0无人员伤亡
若因变量为二分类变量(Y只能取0或1),在建模分析与Y相关的影响因素的时候,使用Logistic回归可能是一个较好的选择;而直接利用线性回归模型进行拟合可能会得到错误的结果。这主要是因为二分类变量违背了线性回归模型的一些假设条件。
2. 线性回归模型的假设
线性回归模型的成立需满足以下几条假设[1]:
 ...... (1)
...... (1)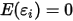 ...... (2)
...... (2)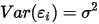 ...... (3)
...... (3)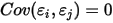 ...... (4)
...... (4)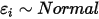 ...... (5)
...... (5)条件(1)为线性假设,即自变量
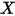 每增加一个单位对
每增加一个单位对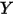 的影响都是一样的(
的影响都是一样的(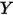 的值增加
的值增加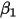 );
);条件(2)-(5)均和误差项
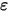 有关。假设(2)表示对任意
有关。假设(2)表示对任意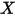 的取值,误差项
的取值,误差项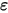 是一个期望为零的随机变量(即
是一个期望为零的随机变量(即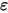 和
和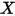 不相关)。这意味着在式
不相关)。这意味着在式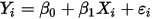 中,由于
中,由于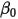 和
和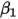 都是常数,因此对于一个给定的
都是常数,因此对于一个给定的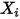 的值,
的值,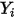 的期望值为:
的期望值为: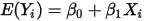 ...... (6)
...... (6)假设(3)表示对任意
 的值,误差项
的值,误差项 的方差都相同(都是
的方差都相同(都是 )。
)。假设(4)和(5)说明误差项
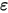 是一个服从正态分布的随机变量(
是一个服从正态分布的随机变量(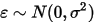 ),且相互独立(即
),且相互独立(即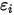 和
和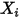 不相关)。图2展示了误差项
不相关)。图2展示了误差项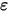 在线性回归模型中的影响。
在线性回归模型中的影响。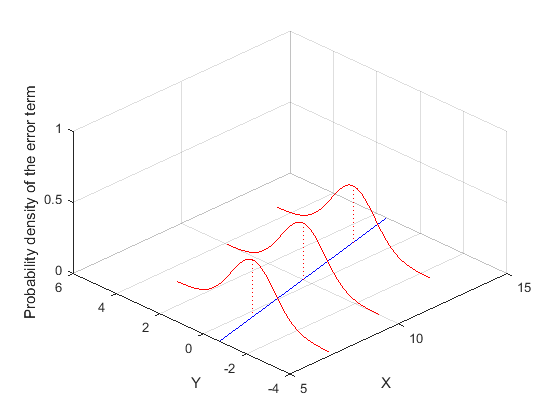
图2:误差项在线性回归模型中的影响
只有当以上5个基本条件都满足时,利用最小二乘法得出的参数的估计值才是无偏的。不幸的是,因变量是二分类变量时,无法满足条件(3)和(5)。以下分别予以说明。
首先考虑假设条件(5)。
当因变量
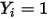 时,根据条件(1)则有:
时,根据条件(1)则有: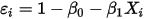 ...... (7)
...... (7)当因变量
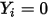 时有:
时有: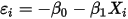 ......(8)
......(8)也就是说,对任意的
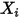 ,误差项
,误差项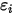 只能取两个固定的值:
只能取两个固定的值: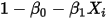 或者
或者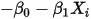 ——而非如图2中所示的正态分布。因此条件(5)不满足。
——而非如图2中所示的正态分布。因此条件(5)不满足。再考虑假设条件(3)。
若记
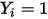 的概率值为
的概率值为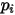 ,则相应的
,则相应的 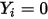 的概率为
的概率为 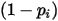 ,如下表所示:
,如下表所示: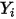 的均值为:
的均值为: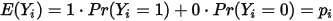 ...... (9)
...... (9)带入(6)可得:
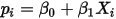 ...... (10)
...... (10) 的方差为:
的方差为:![Var(Y_i )=E[(Y_i )^2 ]-[E(Y_i )]^2](/Witty_Finance/images/download/1553770006424_32882.png)
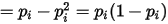
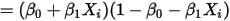 ...... (11)
...... (11)当
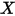 在
在 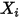 处固定时,
处固定时, 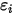 方差等于相应的
方差等于相应的 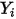 的方差(见(1)式)。也是说,
的方差(见(1)式)。也是说,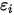 的方差随着
的方差随着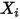 的改变而改变——这与(3)式相矛盾!
的改变而改变——这与(3)式相矛盾!由此可见,直接套用(1)式中的线性回归模型对二分类变量(
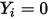 or
or 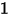 )进行拟合时,自变量的系数估计值会存在偏差。更为关键的一点是:从(10)中可以看出,当假设条件(1)、(2)成立时,
)进行拟合时,自变量的系数估计值会存在偏差。更为关键的一点是:从(10)中可以看出,当假设条件(1)、(2)成立时,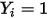 的概率值(
的概率值(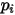 )和自变量
)和自变量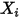 成线性关系——这就意味着概率值
成线性关系——这就意味着概率值 可能会出现大于1(或者小于0)的情形(如图3)——这一点无论是在理论上还是在实际计算的过程都行不通!因此,在处理因变量为二分类变量的情形时,较线性模型而言,Logistic模型的统计特性更好、计算更为方便。
可能会出现大于1(或者小于0)的情形(如图3)——这一点无论是在理论上还是在实际计算的过程都行不通!因此,在处理因变量为二分类变量的情形时,较线性模型而言,Logistic模型的统计特性更好、计算更为方便。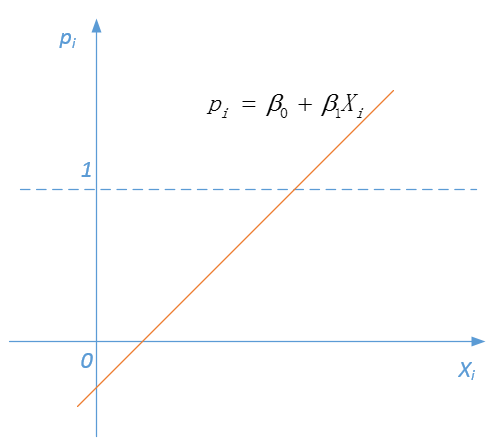
图3:线性概率模型
预告:下一篇讲Logistic模型中的一个核心概念——Odds。
3. 参考文献:
[1] Allison, Paul D. Logistic Regression
Using SAS®: Theory and Application, Second Edition. Copyright © 2012, SAS
Institute Inc., Cary, North Carolina, USA.
Share Http URL: http://www.wittx.cn/get_news_message.do?new_id=135

Best Last Month
Information industry by wittx
Traffic by wittx
Information industry by wittx

Information industry by wittx

Information industry by wittx
Information industry by wittx

Information industry by wittx

Office culture and education by wittx
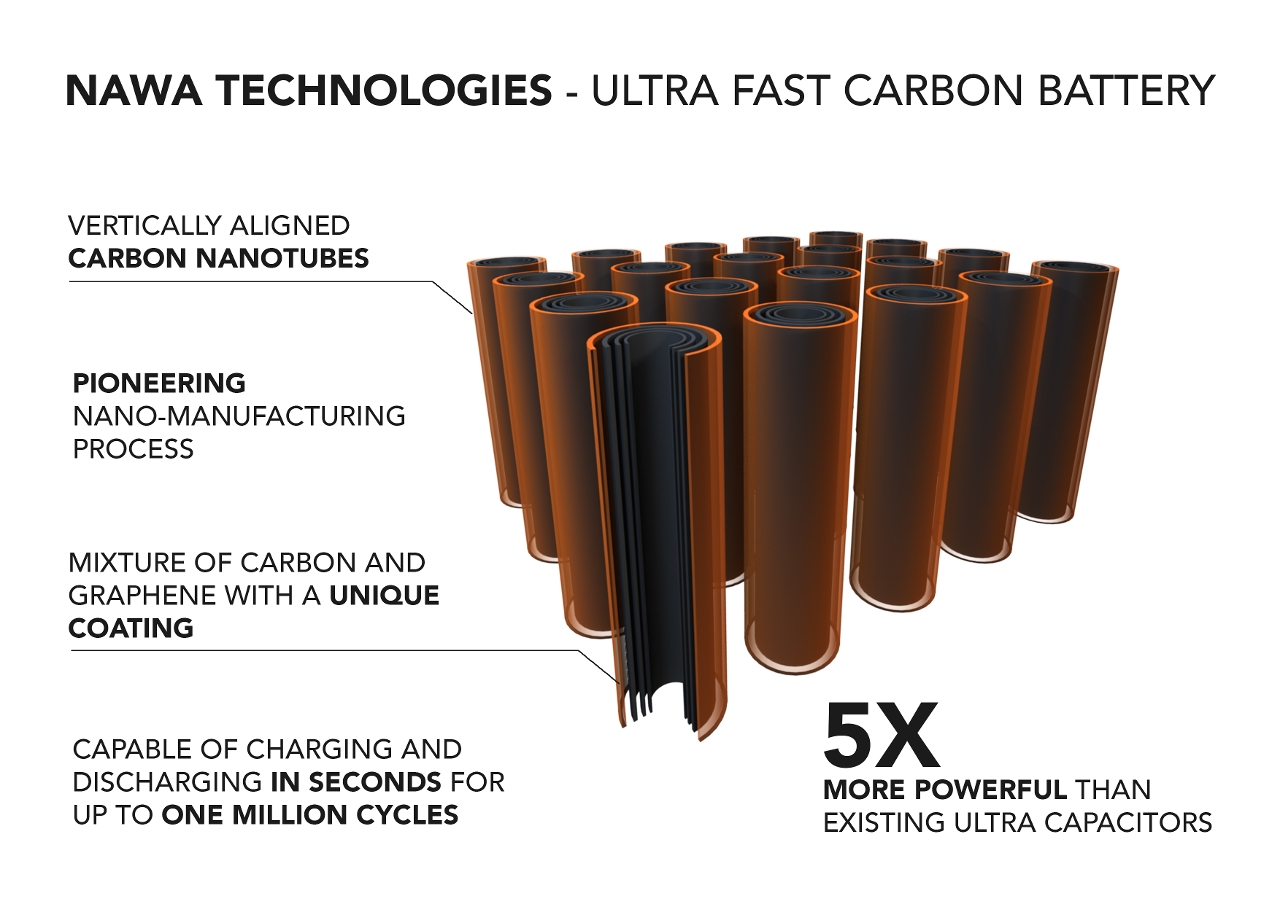
Information industry by wittx
Information industry by wittx


