
-
News Message
RetinaNet
- by wittx 2024-01-28
用户发布的文档
加载速度比较慢比较慢,请稍等,手机环境下,有可能无法显示! " width="100%" height="800">目标检测是计算机视觉领域中的一个重要任务,它涉及在图像或视频中识别和定位特定目标的过程。与传统的图像分类任务不同,目标检测要求算法不仅能够识别图像中的物体,还需要准确地确定它们的位置。
文章摘要
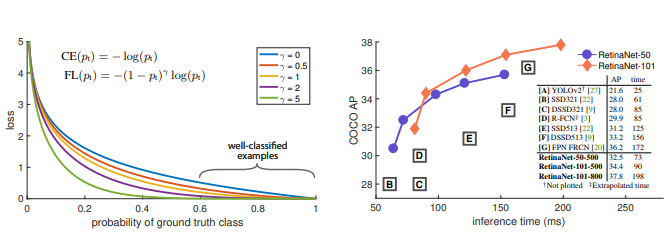
文章作者发现,在密集检测器的训练过程中遇到的极端前景-背景类别不平衡是检测性能不高的核心原因。作者提出通过重新塑造标准交叉熵损失,使其降低对分类正确的样本分配的损失,来解决这种类别不平衡。作者的焦点损失(Focal Loss)将训练集中在一组难例上,防止大量容易判断为负例的样本在训练期间压倒性地影响检测器。为了评估Focal Loss的有效性,作者设计并训练了一个简单的密集检测器RetinaNet。结果表明,使用Focal Loss进行训练时,RetinaNet能够在速度上与先前的一阶段检测器匹敌,同时超越所有现有的最先进的两阶段检测器的准确性。
发表期刊(会议):
CVPR2017
论文地址:
https://arxiv.org/pdf/1708.02002.pdf
代码地址:
https://github.com/facebookresearch/Detectron
实验条件:
没找到(我试验过1080TI是没问题的)
作者单位:
脸书AI研究院
前世今生
当前最先进的目标检测器是基于两阶段建议框驱动的机制。正如在R-CNN框架[11]中广泛推广的那样,第一阶段生成一组稀疏的候选目标位置,而第二阶段使用卷积神经网络对每个候选位置进行分类,将其归为前景类别或背景。通过一系列的进展[10, 28, 20, 14],这种两阶段的框架在具有挑战性的COCO基准测试[21]上始终达到最高的准确性。
尽管两阶段检测器取得了成功,但一个自然的问题是:简单的一阶段检测器是否能够达到类似的准确性?一阶段检测器应用于对象位置、尺度和纵横比的常规、密集采样。最近关于一阶段检测器的工作,如YOLO [26, 27]和SSD [22, 9],展示了令人期待的结果,产生了准确度相对于最先进的两阶段方法在10-40%之间的更快检测器。
文章进一步推动了这一领域的发展:作者提出了一种一阶段目标检测器,首次能够与复杂的两阶段检测器(如Feature Pyramid Network (FPN) [20]或Mask R-CNN [14]的Faster R-CNN [28]变体)匹敌COCO AP。为了实现这一结果,作者确定了在训练过程中的类别不平衡是阻碍一阶段检测器达到最先进准确性的主要障碍,并提出了一种新的损失函数来消除这一障碍。
在类似R-CNN的检测器中,通过两阶段级联和采样启发式方法来解决类别不平衡。提案阶段(例如,Selective Search [35]、EdgeBoxes [39]、DeepMask [24, 25]、RPN [28])迅速缩小候选目标位置的数量到一个较小的数目(例如,1-2k),过滤掉大多数背景样本。在第二个分类阶段,执行采样启发式方法,例如固定的前景-背景比例(1:3)或在线困难样本挖掘(OHEM)[31],以维持前景和背景之间的可管理平衡。
相反,一阶段检测器必须定期处理大量密集采样的候选目标位置,涵盖图像的空间位置、尺度和纵横比。在实践中,这通常涉及列举密集覆盖空间位置、尺度和纵横比的约100k个位置。虽然类似的采样启发式方法也可以应用,但由于训练过程仍然被容易分类的背景示例所主导,因此它们是低效的。这种低效性是目标检测中的一个经典问题,通常通过引导法[33, 29]或困难样本挖掘[37, 8, 31]等技术来解决。
如下图所示,在本文中,作者提出了一种新的损失函数,作为处理类别不平衡的先前方法的更有效替代品。该损失函数是一种动态缩放的交叉熵损失,其中缩放因子随着对正确类别的信心增加而衰减至零。直观地说,这个缩放因子可以在训练过程中自动降低对易于例子的贡献,并迅速将模型聚焦在难例上。
为了展示所提焦点损失的有效性,如下图所示,作者设计了一种简单的一阶段目标检测器,称为RetinaNet,其名称源于对输入图像中对象位置的密集采样。其设计包括一个高效的网络内特征金字塔和锚框的使用。它借鉴了来自[22, 6, 28, 20]的各种最近的思想。RetinaNet既高效又准确;基于ResNet-101-FPN骨干的我们最好的模型在运行速度为5 fps时达到了39.1的COCO测试AP,超过了以前由一阶段和两阶段检测器的单模型结果所发布的最佳结果。
匠心独运
图. 一阶段RetinaNet网络架构使用Feature Pyramid Network(FPN)[20]作为前馈ResNet架构[16]的骨干,以生成一个丰富的多尺度卷积特征金字塔(b)。在这个骨干网络上,RetinaNet连接了两个子网络,一个用于对锚框进行分类(c),另一个用于从锚框回归到地面实际目标框(d)。
RetinaNet是一个统一的网络,由一个骨干网络和两个任务特定的子网络组成。骨干负责在整个输入图像上计算卷积特征图,并且是一个现成的卷积网络。第一个子网络在骨干输出上执行卷积目标分类;第二个子网络执行卷积边界框回归。这两个子网络采用我们专门为一阶段、密集检测提出的简单设计。
卓越性能
我们在具有挑战性的COCO数据集上评估了RetinaNet,并将测试集-dev的结果与最近的最先进方法进行比较,包括一阶段和两阶段模型。表2中呈现了我们使用尺度抖动训练的RetinaNet-101-800模型的结果,训练时间比表1e中的模型长1.5倍(获得了1.3 AP的增益)。与现有的一阶段方法相比,我们的方法在与最接近的竞争对手DSSD [9]相比实现了健康的5.9个AP差距(39.1对33.2),同时速度更快。与最近的两阶段方法相比,RetinaNet在基于Inception-ResNet-v2-TDM [32]的表现最佳的Faster R-CNN模型上实现了2.3个AP的差距。将ResNeXt-32x8d-101-FPN [38]作为RetinaNet的骨干网络,结果进一步提高了1.7个AP,超过了COCO数据集上的40个AP。
总结展望
在这项工作中,作者确定了类别不平衡是阻碍一阶段目标检测器超越表现最好的两阶段方法的主要障碍。为了解决这个问题,作者提出了焦点损失,它在交叉熵损失中应用了一个调制项,以便将学习集中在难以处理的负例上。
Share Http URL: http://www.wittx.cn/get_news_message.do?new_id=1304

Best Last Month
Information industry by wittx
Information industry by wittx

Information industry by wittx
Information industry by wittx

Information industry by wittx

Information industry by wittx

Electronic electrician by wittx
.jpg)
Information industry by wittx
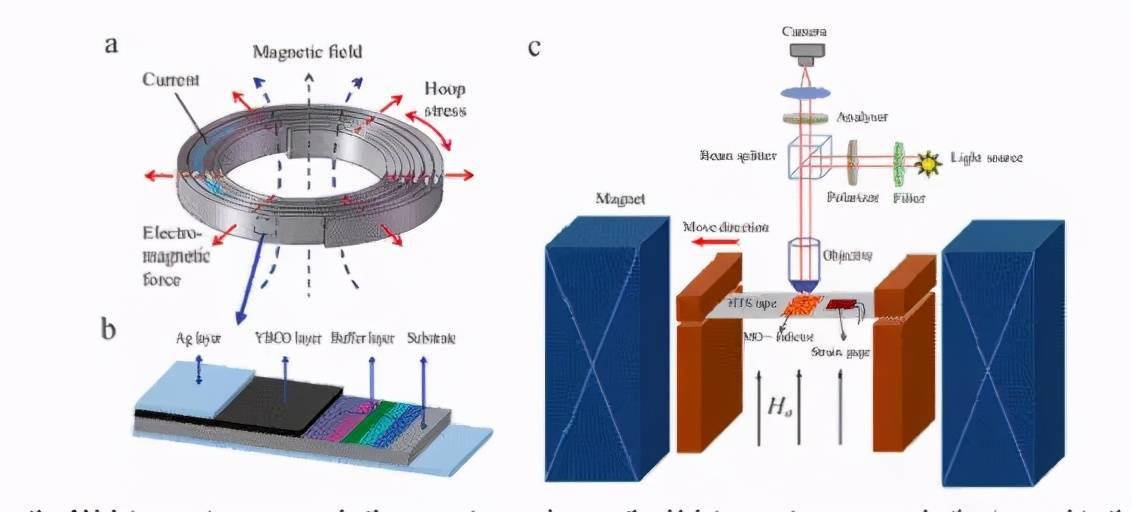
Information industry by wittx
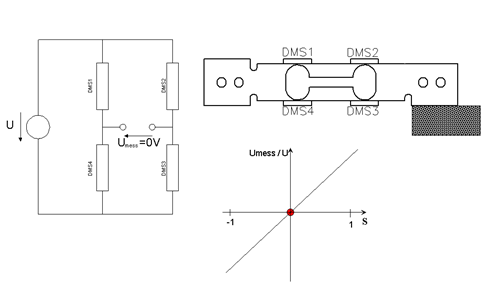
Information industry by wittx
