
-
News Message
Transformer-XL
- by wittx 2023-07-12
目录
- 背景
- vanilla Transformer
- Transformer-XL解析
- 总结
一句话简介:Transformer-XL架构在vanilla Transformer的基础上引入了两点创新:循环机制(Recurrence Mechanism)和相对位置编码(Relative Positional Encoding),以克服vanilla Transformer的长距离获取弱的缺点。
一、背景
Transformer结构的特点:
- 全部用self-attention的自注意力机制。
- 在self-attention的基础上改进了Multi-Attention和Mask Multi-Attention两种多头注意力机制。
- 网络由多个层组成,每个层都由多头注意力机制和前馈网络构成。
- 由于在全局进行注意力机制的计算,忽略了序列中最重要的位置信息,添加了位置编码(Position Encoding),使用正弦函数完成,为每个部分的位置生成位置向量。
Transformer模型在输入时采用的是固定长度序列输入,且Transformer模型的时间复杂度和序列长度的平方成正比,因此一般序列长度都限制在最大512,因为太大的长度,模型训练的时间消耗太大。此外Transformer模型又不像RNN这种结构,可以将最后时间输出的隐层向量作为整个序列的表示,然后作为下一序列的初始化输入。所以用Transformer训练语言模型时,不同的序列之间是没有联系的,因此这样的Transformer在长距离依赖的捕获能力是不够的,此外在处理长文本的时候,若是将文本分为多个固定长度的片段,对于连续的文本,这无异于将文本的整体性破坏了,导致了文本的碎片化,这也是Transformer-XL被提出的原因。
二、Vanilla的Transformer
为何要提这个模型?因为Transformer-XL是基于这个模型进行的改进。
transformer作为一种特征提取器,在NLP中有广泛的应用。但是Trm需要对输入序列设置一个固定的长度,比如在BERT中,默认长度是512。如果文本序列长度短于固定长度,可以通过填充的方式来解决。如果序列长度超过固定长度,处理起来就比较麻烦。
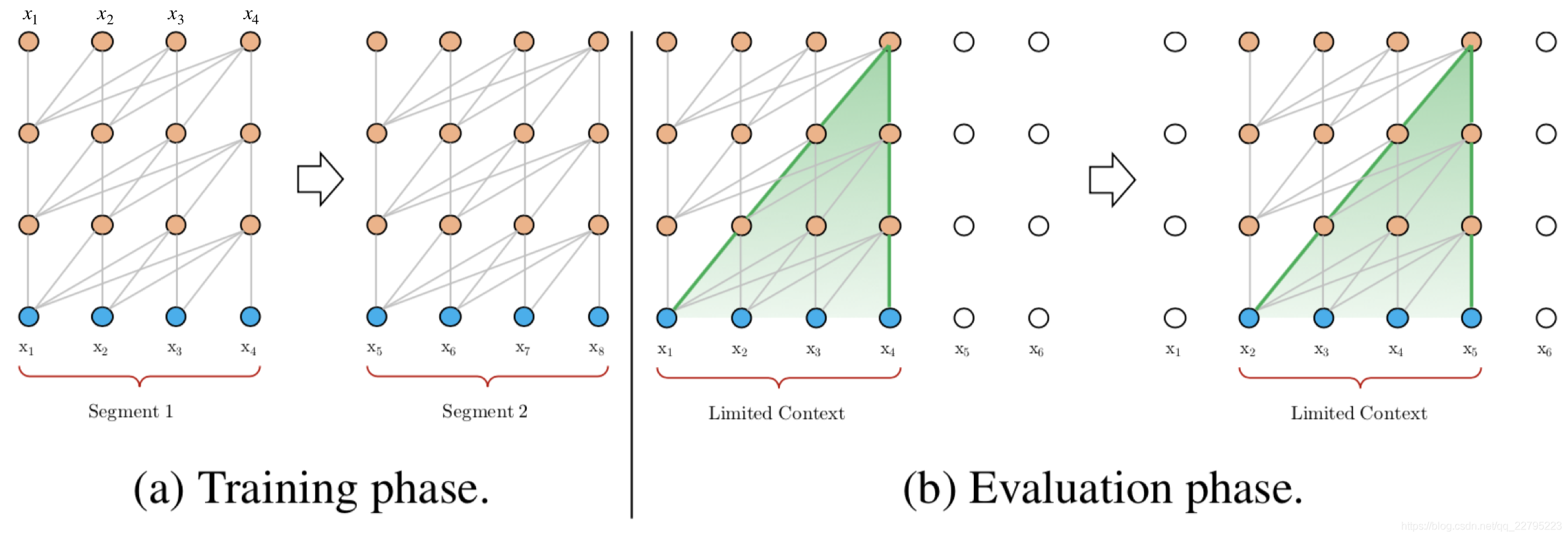
一种处理方式,就是将文本划分为多个segments。训练的时候,对每个segment单独处理,segments之间没有联系,如下图(a)所示。在预测的时候,会对固定长度的segment做计算,一般取最后一个位置的隐向量作为输出。为了充分利用上下文关系,在每做完一次预测之后,就对整个序列向右移动一个位置,再做一次计算,如上图(b)所示,这导致计算效率非常低。
该模型容易发现有以下缺点:
- 上下文长度受限:字符之间的最大依赖距离受输入长度的限制,模型看不到出现在几个句子之前的单词。
- 上下文碎片:对于长度超过512个字符的文本,都是从头开始单独训练的。段与段之间没有上下文依赖性,会让训练效率低下,也会影响模型的性能。
- 推理速度慢:在测试阶段,每次预测下一个单词,都需要重新构建一遍上下文,并从头开始计算,这样的计算速度非常慢。
三、Transformer-XL解析
Transformer-XL架构在vanilla Transformer的基础上引入了两点创新:循环机制(Recurrence Mechanism)和相对位置编码(Relative Positional Encoding),以克服vanilla Transformer的缺点。与vanilla Transformer相比,Transformer-XL的另一个优势是它可以被用于单词级和字符级的语言建模。
3.1 引入循环机制
与vanilla Transformer的基本思路一样,Transformer-XL仍然是使用分段的方式进行建模,但其与vanilla Transformer的本质不同是在于引入了段与段之间的循环机制,使得当前段在建模的时候能够利用之前段的信息来实现长期依赖性。如下图所示:
在训练阶段,处理后面的段时,每个隐藏层都会接收两个输入:
- 该段的前面隐藏层的输出,与vanilla Transformer相同(上图的灰色线)。
- 前面段的隐藏层的输出(上图的绿色线),可以使模型创建长期依赖关系。
这两个输入会被拼接,然后用于计算当前段的Key和Value矩阵。对于某个段的某一层的具体计算公式如下:
在上面式子中τ表示上一片段,τ+1表示下一片段。将上一片段的输出缓存起来,然后直接和下一片段的隐层拼接在一起,得到上面的第一个式子。 在这里SG()的含义是stop-gradient。另外这个引入了上一片段的隐层表示只会用在key和value上,对于query还是保持原来的样子(得到中间的表达式形态)。这样做也好理解,query只是表示查询的词,而key,value表示的是这个查询的词的相关信息,我们要改变的是只是信息,因此只要在key,value中引入上一片段的信息就可以了,剩下的就和Transformer一致。
原则上只要GPU内存允许,该方法可以利用前面更多段的信息,测试阶段也可以获得更长的依赖。
在测试阶段,与vanilla Transformer相比,其速度也会更快:在vanilla Transformer中,一次只能前进一个step,并且需要重新构建段,并全部从头开始计算;而在Transformer-XL中,每次可以前进一整个段,并利用之前段的数据来预测当前段的输出。
3.2 相对位置编码
在Transformer中,一个重要的地方在于其考虑了序列的位置信息。在分段的情况下,如果仅仅对于每个段仍直接使用Transformer中的位置编码,即每个不同段在同一个位置上的表示使用相同的位置编码,就会出现问题。(下式中U表示位置向量)
论文对于这个问题,提出了一种新的位置编码的方式,即会根据词之间的相对距离而非像Transformer中的绝对位置进行编码。Transformer中的attention权重计算公式如下:
将其展开可以分解成下面四个部分。 第一层的计算查询和键之间的attention分数的方式为:
E表示embedding,U 表示位置向量。在Transformer-XL中,对上述的attention计算方式进行了变换,转为相对位置的计算,而且不仅仅在第一层这么计算,在每一层都是这样计算。
对比来看:
- 在(b)和(d)这两项中,将所有绝对位置向量都转为相对位置向量 ,与Transformer一样,这是一个固定的编码向量,不需要学习。
- 在(c)这一项中,将查询的向量转为一个需要学习的参数向量u,因为在考虑相对位置的时候,不需要查询绝对位置 i,因此对于任意的 i,都可以采用同样的向量。同理,在(d)这一项中,也是一样
- 将键的权重变换矩阵转为和,分别作为content-based key vectors和location-based key vectors。
从另一个角度来解读这个公式的话,可以将attention的计算分为如下四个部分:
a. 基于内容的"寻址",即没有添加原始位置编码的原始分数。
b. 基于内容的位置偏置,即相对于当前内容的位置偏差。
c. 全局的内容偏置,用于衡量key的重要性。
d. 全局的位置偏置,根据query和key之间的距离调整重要性。
将上面的式子合并后,可以得到:
上面整个即使Transformer-XL的两个改变:前面是内容,后面是位置。
3.3 整体公式计算
结合上面两个创新点,将Transformer-XL模型的整体计算公式整理如下,这里考虑一个N层的只有一个注意力头的模型:
四、总结
1. 模型特点
在 AI-Rfou 等人提出的vanilla Transformer上做了两点创新:
- 引入循环机制(Recurrence Mechanism)
- 相对位置编码(Relative Positional Encoding),这个是解决上面创新带来的问题而产生的。
2. 优点
- 与vanilla Transformer相比,Transformer-XL的另一个优势是它可以被用于单词级和字符级的语言建模【说明:这个没有理解从哪方面体现的】。在几种不同的数据集(大/小,字符级别/单词级别等)均实现了最先进的语言建模结果。
- 结合了深度学习的两个重要概念——循环机制和注意力机制,允许模型学习长期依赖性,且可能可以扩展到需要该能力的其他深度学习领域,例如音频分析(如每秒16k样本的语音数据)等。
- 在inference阶段非常快,比之前最先进的利用Transformer模型进行语言建模的方法快300~1800倍。
- 有详尽的源码!含TensorFlow和PyTorch版本的,并且有TensorFlow预训练好的模型及各个数据集上详尽的超参数设置。
3. 不足
- 尚未在具体的NLP任务如情感分析、QA等上应用。
- 没有给出与其他的基于Transformer的模型,如BERT等,对比有何优势。
- 在Github源码中提到,目前的sota结果是在TPU大集群上训练得出,对于我等渣机器党就只能玩玩base模式了。
参考文献
【1】论文:https://arxiv.org/pdf/1901.02860.pdf
【2】代码:https://github.com/kimiyoung/transformer-xl
【3】英文参考:https://www.lyrn.ai/2019/01/16/transformer-xl-sota-language-model
【4】Transformer-XL解读(论文 + PyTorch源码): https://blog.csdn.net/magical_bubble/article/details/89060213
Share Http URL: http://www.wittx.cn/get_news_message.do?new_id=1192

Best Last Month

Information industry by wittx

Computer software and hardware by wittx

Information industry by wittx

Information industry by wittx

Information industry by wittx

Information industry by wittx
Electronic electrician by wittx

Information industry by show
Information industry by wittx
Information industry by 未注册用户发布








