
-
News Message
DeepSpeed-Chat:ChatGPT框架
- by wittx 2023-07-12

- 最新消息
- 什么是DeepSpeed Chat ️
- 特性
- ☕快速上手☕
- 训练效果评估
- 支持的模型
- DeepSpeed Chat 的路线图
1 什么是 DeepSpeed Chat
本着使 ChatGPT 式模型及其功能民主化的精神,DeepSpeed 自豪地推出了一个通用系统框架,用于为类 ChatGPT 模型提供端到端的培训体验,名为 DeepSpeed Chat。它可以自动采用你最喜欢的预训练大型语言模型,通过 OpenAI InstructGPT 风格的三个阶段来生成您自己的高质量 ChatGPT 风格模型。DeepSpeed Chat 使类似ChatGPT 风格的模型训练变得简单、快速、经济且可扩展。
根据官方介绍,一键运行就可以在 1.36 小时内在具有 48GB 内存的单个消费级 NVIDIA A6000 GPU 上训练、生成和提供 13 亿参数的 ChatGPT 模型。在具有 8 个 NVIDIA A100-40G GPU 的单个 DGX 节点上,DeepSpeed-Chat 可以在 13.6 小时内训练一个 130 亿参数的 ChatGPT 模型。在多 GPU 多节点系统上,即 8 个 DGX 节点和 8 个 NVIDIA A100 GPU/节点,DeepSpeed-Chat 可以在 9 小时内训练出一个 660 亿参数的 ChatGPT 模型。最后,它使训练速度比现有 RLHF 系统快 15 倍,并且可以处理具有超过 2000 亿个参数的类 ChatGPT 模型的训练:从这些性能来看,太牛X了,这是现有ChatGPT框架不能完成的壮举。
除了这个版本之外,DeepSpeed 系统一直自豪地作为系统后端来加速一系列正在进行的快速训练/微调聊天风格模型(例如,LLaMA)的工作。以下是一些由 DeepSpeed 提供支持的开源示例:
- Databricks Dolly
https://github.com/databrickslabs/dolly
- LMFlow
https://github.com/OptimalScale/LMFlow
- CarperAI-TRLX
https://github.com/CarperAI/trlx
- Huggingface-PEFT
https://github.com/huggingface/peft
2 DeepSpeed Chat 特性
DeepSpeed Chat 正在快速发展,可以满足对训练/微调以及服务新兴模型的系统级加速并支持不断增长的需求。
DeepSpeed Chat 的摘要包括:
- DeepSpeed Chat:一个完整的端到端三阶段 OpenAI InstructGPT 训练策略,带有强化学习人类反馈(RLHF),从用户青睐的预训练大型语言模型权重生成高质量的 ChatGPT 风格模型;
- DeepSpeed Hybrid Engine:一种新系统,支持各种规模的快速、经济且可扩展的 RLHF 训练。它建立在用户最喜欢的 DeepSpeed 框架功能之上,例如 ZeRO 技术和 DeepSpeed-Inference;
- Easy-breezy Training Experience:单个脚本能够采用预训练的 Huggingface 模型并通过 RLHF 训练的所有三个步骤运行它。
- 对当今类似 ChatGPT 的模型训练的通用系统支持:DeepSpeed Chat 不仅可以作为基于 3 步指令的 RLHF 管道的系统后端,还可以作为当前单一模型微调探索(例如,以 LLaMA 为中心的微调)和针对各种模型和场景的通用 RLHF 训练。
3 ☕ 快速上手 ☕
3.1 Installation
git clone https://github.com/microsoft/DeepSpeed.git cd DeepSpeed pip install . git clone https://github.com/microsoft/DeepSpeedExamples.git cd DeepSpeedExamples/applications/DeepSpeed-Chat/ pip install -r requirements.txt3.2 一键完成RLHF三阶段训练并生成ChatGPT模型
DeepSpeed-Chat 的 RLHF 示例 1:用喝咖啡的时间类训练一个1.3B ChatGPT 模型
如果有1-2小时喝咖啡的时间,可以尝试使用 DeepSpeed-Chat 训练小型/玩具模型。下面是一个1.3B模型的训练示例:
python train.py --actor-model facebook/opt-1.3b --reward-model facebook/opt-350m --num-gpus 1通过 DeepSpeed-Chat 在具有 48GB 内存的NVIDIA A6000 GPU 上训练 13 亿参数 ChatGPT 模型的 时间消费如下:
Model Size (A6000-48G) Step 1 Step 2 Step 3 Total Actor: OPT-1.3B Reward: OPT-350M 2900 秒 670秒 1.2小时 2.2小时 DeepSpeed-Chat 的 RLHF 示例 2:在单GPU 节点上为 13B ChatGPT 模型训练,大约花费半天时间 如果有大约半天的时间并且只有一个服务器节点,官方建议在以下单个脚本中使用预训练的 OPT-13B 作为actor模型和 OPT-350M 作为奖励模型的示例来生成最终的 13B ChatGPT模型:
python train.py --actor-model facebook/opt-13b --reward-model facebook/opt-350m --num-gpus 8在具有 8 个 NVIDIA A100-40G GPU 的 DGX 节点上通过 DeepSpeed-Chat 训练 130 亿参数 ChatGPT 模型的 时间消费如下:
Model Size (A100-40G) Step 1 Step 2 Step 3 Total Actor: OPT-13B Reward: OPT-350M 2.5hr 0.25hr 10.8hr 13.6hr DeepSpeed-Chat 的 RLHF 示例 3:大型 66B ChatGPT 模型的低预算云训练 想要尝试不同的型号尺寸和配置吗?使用DeepSpeed聊天,用户可以轻松做到这一点。例如,如果您可以访问多节点集群或云资源,并且更喜欢为您的研究或业务训练一个更大、更高质量的模型,可以简单地使用具有所需模型大小的类似脚本,例如66B和GPU计数=64
python train.py --actor-model facebook/opt-66b --reward-model facebook/opt-350m --num-gpus 64通过 DeepSpeed-Chat 在 8 个 DGX 节点(每个节点具有 8 个 NVIDIA A100-80G GPU)上训练 660 亿参数的 ChatGPT 模型时间消费如下:
Model Size (A100-80g) Step 1 Step 2 Step 3 Total Actor: OPT-66B Reward: OPT-350M 82mins 5mins 7.5hr 9hr 3.3 演示:单步微调
train.py脚本有一个易于使用的命令行界面,可以通过几个参数启动,包括模型类型、模型大小和要运行的GPU数量。考虑到那些希望使用DeepSpeed Chat只在步骤1或2中微调预训练模型,或者只直接使用自己的参与者和奖励模型检查点来执行我们RLHF管道中的步骤3的用户,DeepSpeed Chat提供了更大的可配置性和灵活性,以适应单个步骤的微调:
- 第 1 步 - 监督式微调
# Move into the first step of the pipeline cd training/step1_supervised_finetuning/ # Run the training script bash training_scripts/single_gpu/run_1.3b.sh # Evaluate the model bash evaluation_scripts/run_prompt.sh- 第 2 步 - 奖励模型
# Move into the second step of the pipeline cd training/step2_reward_model_finetuning # Run the training script bash training_scripts/run_350m.sh # Evaluate the model bash evaluation_scripts/run_eval.sh- 第 3 步 - 通过人类反馈强化学习

作为整个三步InstructGPT管道中最复杂的一步,DeepSpeed Chat的Hyrbid引擎已经实现了足够的加速,以避免大量的训练时间(成本)影响。有关更多信息,请参阅步骤3:强化学习人的反馈(RLHF)。如果您已经拥有经过微调的演员和奖励模型检查点,那么只需运行以下脚本即可启用PPO训练:
# Move into the final step of the pipeline cd training/step3_rlhf_finetuning/ # Run the training script bash training_scripts/single_gpu/run_1.3b.sh3.4 使用 DeepSpeed-Chat 的 RLHF API 自定义您自己的 RLHF 训练管道
DeepSpeed Chat允许用户使用灵活的API构建自己的RLHF训练管道,如下所示,用户可以使用这些API来重建自己的RL高频训练策略。这使得通用接口和后端能够为研究探索创建广泛的RLHF算法。
engine = DeepSpeedRLHFEngine( actor_model_name_or_path=args.actor_model_name_or_path, critic_model_name_or_path=args.critic_model_name_or_path, tokenizer=tokenizer, num_total_iters=num_total_iters, args=args) trainer = DeepSpeedPPOTrainer(engine=engine, args=args) for prompt_batch in prompt_train_dataloader: out = trainer.generate_experience(prompt_batch) actor_loss, critic_loss = trainer.train_rlhf(out)3.5 服务:插入由 DeepSpeed-Chat 训练的最终模型并进行测试!
为了快速测试DeepSpeed Chat训练的最终模型,我们在下面提供了一个简单的脚本。对于希望使用我们训练有素的模型创建不同LLM应用程序(如个人助理、聊天机器人和代码理解)的用户,请参阅LangChain。
# serve the final model python chat.py --path ${PATH-to-your-actor-model}示例 1:服务于 DeepSpeed-Chat 训练的 1.3B 最终模型的问答环节

示例 2:服务于从 DeepSpeed-Chat 训练的模型的多轮对话

4 训练性能评估
4.1 优越的模型规模和低训练成本
表 1 全面展示了 DeepSpeed-RLHF 系统支持的规模和端到端训练时间。它还展示了在 Azure Cloud 中训练模型的最具成本效益的方法以及相关成本。
GPU SKUs OPT-1.3B OPT-6.7B OPT-13.2B OPT-30B OPT-66B Bloom-175B 1x V100 32G 1.8 days 1x A6000 48G 1.1 days 5.6 days 1x A100 40G 15.4 hrs 3.4 days 1x A100 80G 11.7 hrs 1.7 days 4.9 days 8x A100 40G 2 hrs 5.7 hrs 10.8 hrs 1.85 days 8x A100 80G 1.4 hrs($45) 4.1 hrs ($132) 9 hrs ($290) 18 hrs ($580) 2.1 days ($1620) 64x A100 80G 31 minutes 51 minutes 1.25 hrs ($320) 4 hrs ($1024) 7.5 hrs ($1920) 20 hrs ($5120) 表 1. 针对不同参与者模型大小的端到端 RLHF 训练(第 3 步)和在硬件上运行的固定 350M 关键模型,从单个消费级 GPU (NVIDIA A6000) 到更强大的云设置 (64xA100-80GPU)
4.2 与现有 RLHF 系统的吞吐量和模型大小可扩展性比较
(I) 单个GPU的模型规模和吞吐量比较 与Colossal AI或HuggingFace DDP等现有系统相比,DeepSpeed Chat的吞吐量高出一个数量级,可以在相同的延迟预算下训练更大的演员模型,或者以更低的成本训练类似大小的模型。例如,在单个GPU上,DeepSpeed可以在单个GPU上将RLHF训练的吞吐量提高10倍以上。虽然CAI Coati和HF-DDP都可以运行1.3B的最大模型大小,但DeepSpeed可以在相同的硬件上运行6.5B的模型,高出5倍。

图 2:第 3 步吞吐量与其他两个系统框架(Colossal AI 的 Coati 和 Huggingface-DDP)的比较,用于在单个 NVIDIA A100-40G 商用 GPU 上加速 RLHF 训练。没有图标代表 OOM 场景。
(II)单节点多GPU模型规模与吞吐量对比 在单个节点的多 GPU 上,DeepSpeed-Chat 在系统吞吐量方面比 CAI-Coati 提速 6-19 倍,比 HF-DDP 提速 1.4-10.5 倍(图 3)。

图 3. 在配备 8 个 NVIDIA A100-40G GPU 的单个 DGX 节点上,不同模型大小的训练管道第 3 步(最耗时的部分)的端到端训练吞吐量比较。没有图标代表 OOM 场景。
(III) Step3中优越的加速性能 图 3 结果的关键原因之一是DeepSpeed-Chat的混合引擎的卓越生成阶段加速,如下所示。

图 4. DeepSpeed Chat 混合引擎的卓越生成阶段加速:在具有 8 个 A100-40G GPU 的单个 DGX 节点上训练 OPT-1.3B 参与者模型 + OPT-350M 奖励模型的时间/序列分解。
5 支持的模型
目前, DeepSpeed Chat 支持以下模型系列。随着时间的推移,将继续发展,包括用于 ChatGPT 式培训的新兴模型!
model family size range opt 0.1B - 66B bloom 0.3B - 176B gpt_neox 1.3B - 20B gptj 1.4B - 6B gpt_neo 0.1B - 2.7B gpt2 0.3B - 1.5B codegen 0.35b - 16B 6 引用
- [1] Schulman, John, et al. "Introducing ChatGPT", https://openai.com/blog/chatgpt (2022).
- [2] Ouyang, Long, et al. "Training language models to follow
instructions with human feedback." arXiv preprint arXiv:2203.02155
(2022). This is also referred as InstructGPT - [3] Stiennon, Nisan, et al. "Learning to summarise with human
feedback." Advances in Neural Information Processing Systems 33
(2020): 3008-3021. - [4] Transformers Hugging Face (http://github.com)
- [5] CarperAI, https://github.com/CarperAI/trlx
- [6] lvwerra/trl: Train transformer language models with reinforcement learning. (http://github.com)
- [7] pg-is-all-you-need/02.PPO.ipynb at master ·
MrSyee/pg-is-all-you-need (http://github.com)
Share Http URL: http://www.wittx.cn/get_news_message.do?new_id=1191

Best Last Month
Information industry by wittx
Information industry by wittx
Information industry by wittx

Information industry by wittx
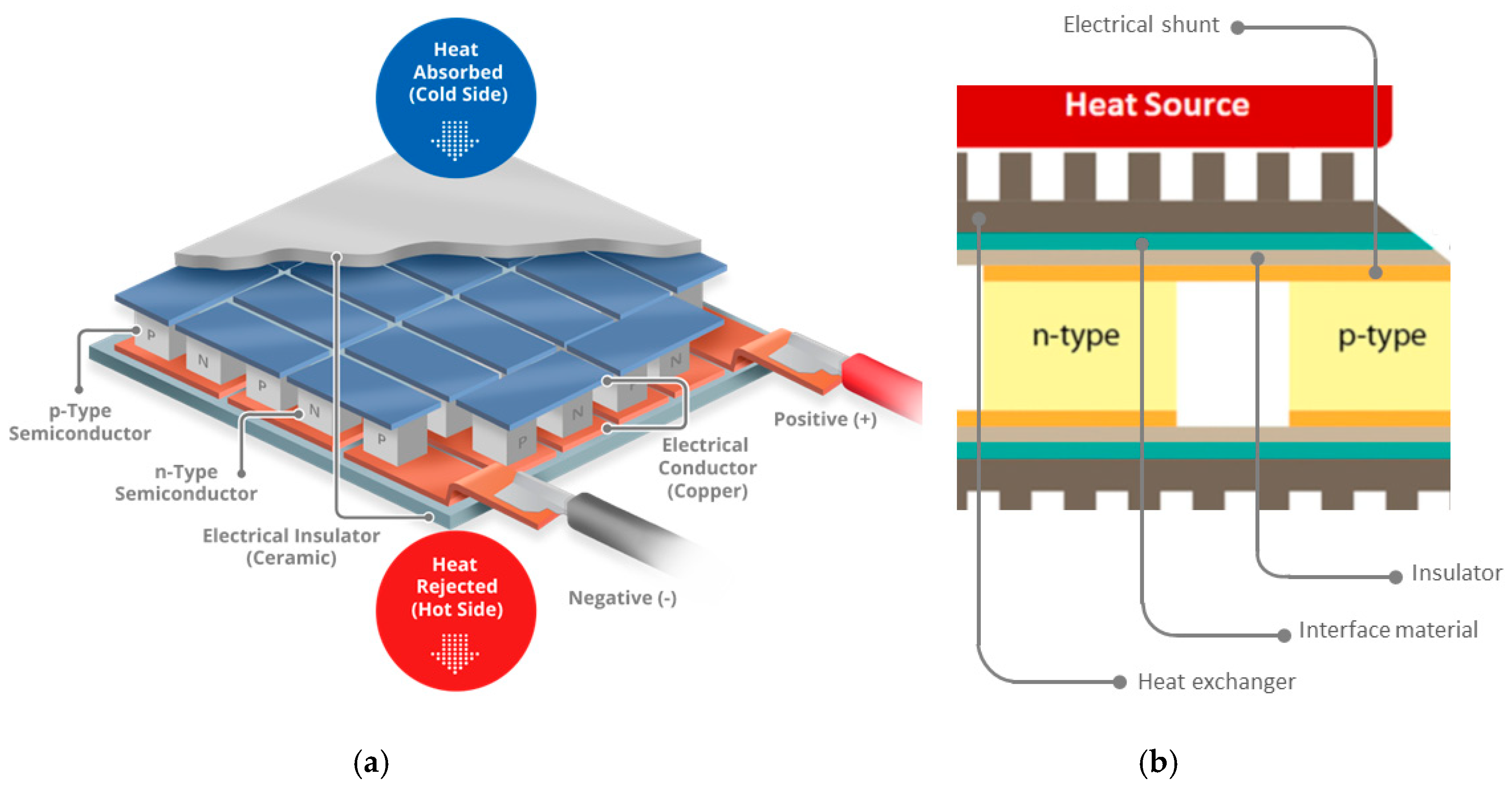
Information industry by wittxThree dimensional architected thermoelectric devices with high toughness and power conversion effici

Information industry by wittx

Information industry by wittx
Information industry by wittx
Information industry by wittx

Information industry by wittx
