
-
News Message
CoCa: Contrastive Captioners are Image-Text Foundation Models
- by wittx 2023-03-06
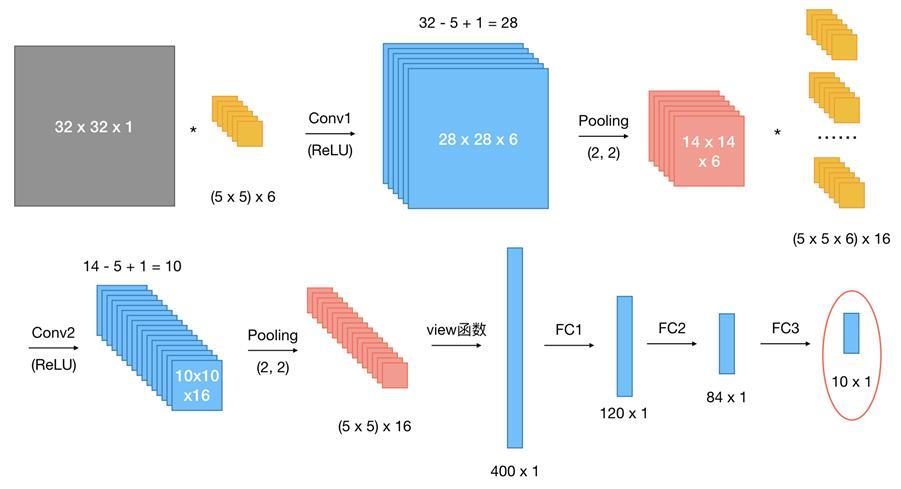
Title:《CoCa: Contrastive Captioners are Image-Text Foundation Models》
Author:Google Research
ArXiv 2022.05.04
一个复现的code: https://github.com/lucidrains/CoCa-pytorchHighligt
- 文章做的是large-scale image-text pretrained model,可以很好的迁移到下游任务中去。本文提出了CoCa(Contrastive Captioner),结合了contrastive loss和caption loss。其中,contrastive就是类似于CLIP那样做image-text pairs 比对的方法,而caption是让模型有生成image caption的能力,即根据图像生成文字描述。本文的主要贡献应该就是在pretrain任务中引入了caption loss,可以更好的将两种模态的数据做cross attention,从而进一步提升性能。
- CoCa是同时用了web-scale alt-text和annotated images训练的(JFT-3B、ALIGN),可以zero-shot transfer或者稍微根据实际任务微调一下就可以很好的适应到下游的任务中去,比如recognition,cross-model retrieval,multimodel understanding等等。比如Imagenet,直接zero-shot过去是86.3%的acc,frozen encoder and finetune classifier是90.6%,finetune encoder可以到91.0%
- 作者实验部分也说了,pretrain CoCa用了2 048块Cloud TPU v4 chips花了5天。。。
Methods

- CoCa先用两个单独的transformer结构做Image Encoder和Text Decoder,两者的输出做contrastive loss,接下来把两者做cross-attention,求caption loss。
- (公式1, )
(公式2)
(公式3) - Caption loss部分其实就是根据前t-1个输出预测第t个输出,和翻译是一样的,损失就是交叉熵。
- 文章说这个caption训的时候用了teache-forcing的策略,网上一搜,原来是在机器翻译中常用的一个策略,就是用前t-1个gt来训练第t个预测,很有道理。参考资料1。但也会引起exposure bias的问题,其实就是训的时候前t-1个见的是gt,测试的时候就是pred了,导致两个分布不一致。 参考资料2。
部分实验结果

Share Http URL: http://www.wittx.cn/get_news_message.do?new_id=1153

Best Last Month

Information industry by wittx
Electronic electrician by wittx

Electronic electrician by wittx
Information industry by wittx

Information industry by wittx
Information industry by wittx

Information industry by wittx
Information industry by wittx

Information industry by wittx

Information industry by wittx
