
-
News Message
Vision Transformer imagenet 识别率达91%
- by wittx 2023-02-06
自 20 世纪 80 年代,卷积神经网络 (CNN) 就已应用于计算机视觉中,但直到 2012 年 AlexNet 的性能远远超过当时最为先进的图像识别方法时,这一技术才算走到行业前列。实现这一突破要归功于两个因素:
ImageNet 等训练集的出现;
- 使用商业 GPU 硬件为训练提供了更强的计算能力。
因此,自 2012 年起,CNN 就已成为视觉任务的首选模型。
使用 CNN 的好处在于,它们无需手动设计的视觉特征,而是直接从数据“端到端”执行学习任务。但是尽管 CNN架构本身专为图像设计,无需手动提取特征,但其对计算能力要求很高。展望下一代可扩展视觉模型,人们可能会思考这种特定于领域的设计是否有必要,或者考虑是否可以成功利用更多与领域无关的高效计算架构来获得 SOTA 的成果。
我们朝这个方向迈出了第一步,推出了 Vision Transformer(ViT)。这是一种尽可能基于最初为基于文本的任务而设计的 Transformer架构的视觉模型。ViT 将输入图像表示为一系列图块,类似于在将 Transformer 应用于文本时使用的一系列单词嵌入,并且可直接预测图像的类别标签。使用充足的数据进行训练时,ViT 可表现出卓越的性能,优于与之对等的先进 CNN,而所需资源仅为后者的四分之一。为了促进这一领域的进一步研究,我们开源了 代码和模型。
- Vision Tra nsformer https://arxiv.org/abs/2010.11929
- Transformer https://papers.nips.cc/paper/7181-attention-is-all-you-need.pdf
- 代码和模型 https://github.com/google-research/vision_transformer
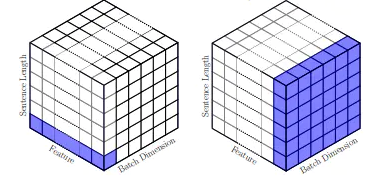
Vision Transformer 将输入图像视为一系列图块,类似于自然语言处理 (NLP) Transformer 生成的一系列词嵌入
Vision Transformer
Transformer 将文本中一系列单词作为输入,然后将其用于 分类、翻译或其他 NLP 任务。对于 ViT,我们尽量避免修改 Transformer 设计,使其能够直接对图像(而不是文字)进行处理,同时观察模型能够自行学到多少有关图像结构的知识。
ViT 会将图像分为方块网格,通过连接一个方块中所有像素通道,然后将其线性投影到所需的输入维度,将每个方块展平为单个矢量。Transformer 与输入元素的结构无关,因此我们在每个方块中添加了可学习的位置 Embedding,使模型能够了解图像结构。按理说,ViT 并不知道图像中各方块的相对位置,甚至不知道图像具有 2D 结构,它必须从训练数据中学习这类相关信息,并在位置嵌入中编码结构信息。
扩展
首先,我们使用 ImageNet 训练 ViT。在此阶段,ViT 最高获得了 77.9% top-1 准确率。对于首次尝试来说,这个表现相当不错,但较最先进水平仍相去甚远:目前使用 ImageNet(无额外数据)训练的 最佳CNN 的准确率可达 85.8%。尽管采取了缓解策略(例如正则化),但 ViT 并未内置充足的图像相关知识,因此仍过拟合 ImageNet 任务。
- 最佳 https://arxiv.org/abs/2003.11342v1
为了研究数据集大小对模型性能产生的影响,我们使用数据集 ImageNet-21k(1400 万张图像,21000 个类别)和 JFT(3 亿张图像,18000 个类别)训练 ViT,并将结果与使用相同数据集训练的最先进 CNN Big Transfer (BiT)进行比较。我们之前观察到,使用 ImageNet 训练(100 万张图像)时,ViT 的性能明显低于与之对等的 CNN (BiT)。但是,使用 ImageNet-21k(1400 万张图像)训练时,ViT 与 BiT 性能相当;而使用 JFT(3 亿张图像)训练时,ViT 的性能优于 BiT。
- ImageNet-21k http://www.image-net.org/papers/imagenet_cvpr09.pdf
- JFT https://arxiv.org/abs/1707.02968
最后,我们分析了训练模型所需计算量。为此,我们使用 JFT 训练了几种不同的 ViT 和 CNN 模型。这些模型涵盖了各种模型大小和训练时间。因此,它们需要不同的计算量来进行训练。我们观察到,给定计算量的情况下,ViT 的性能优于对等的 CNN。
左图:使用不同数据集进行预训练时 ViT 的性能; 右图:ViT 具有出色的性能/计算权衡
我们的数据表明,(1) 经过充分训练的 ViT 可以表现出良好的性能,(2) ViT 在较小和较大的计算规模下均具有出色的性能/计算规模权衡。因此,为了确定在更大计算规模下其性能是否能够继续提升,我们训练了一个具有 6 亿个参数的 ViT 模型。
这一大型 ViT 模型在多个热门基准上均表现出最先进的性能,其中在 ImageNet 上可达到 88.55% top-1 准确率,在 CIFAR-10 上则为 99.50%。ViT 在 ImageNet 评估集“ImageNet-Real”的 清理版本上也表现出色,可达到 90.72% top-1 准确率。最后,即使训练数据点非常少,ViT 仍可以出色完成各类任务。例如,在 VTAB-1k 套件 (19 个任务,每个有 1000 个数据点)上,ViT 的准确率可达 77.63%,远远领先于最先进 (SOTA) 的单模型 (76.3%),甚至可与 SOTA 多模型集合(77.6%) 相媲美。最重要的是,与以前的 SOTA CNN 相比,ViT 能够使用更少的计算资源获得这些结果,例如,ViT 使用的计算资源仅为预训练 BiT 模型的四分之一。
Vision Transformer 在热门基准上表现出的性能可媲美甚至超过最先进的 CNN。 左图:热门图像分类任务,包括 ImageNet(包含新的验证标签 ReaL 和 CIFAR)、Pets 和 Flowers); 右图:VTAB 分类套件中 19 个任务的平均值
- 清理版本 https://arxiv.org/abs/2006.07159
- 多模型集合 https://arxiv.org/abs/2010.06866
可视化
为了直观地了解模型所学内容,我们将其某些内部工作可视化。首先,我们看一下位置嵌入,即模型学习编码相关方块相对位置的参数,并发现 ViT 能够再现直观的图像结构。每个位置嵌入与同行同列的其他位置嵌入最为相似,说明该模型已恢复了原始图像的网格结构。然后,我们检查了每个 Transformer 块中各个元件之间的平均空间距离。在较高层(深度为 10-20)仅使用全局特征(即较大的注意力距离),但较低层(深度为 0-5)则捕获全局和局部特征,如平均注意力距离的范围较大。相反,CNN 的较低层中仅存在局部特征。这些实验表明,ViT 可学习硬编码到 CNN 中的特征(如对网格结构的认识),但也可以自由学习更多通用模式,例如较低层中局部和全局特征的混合,这有助于泛化。
左图:ViT 通过其位置嵌入学习图块的网格状结构; 右图:ViT 的较低层包含全局和局部特征,较高层仅包含全局特征
总结
尽管 CNN 彻底改变了计算机视觉,但我们的结果表明,没有必要为图像任务量身定制模型,甚至定制模型不是性能最好的模型。数据集规模在不断扩大,无监督和半监督方法也在不断发展,因此我们越来越需要开发出能够更高效地使用这些数据集进行训练的新型视觉架构。我们相信 ViT 是迈向可扩展通用架构的第一步,并对未来的发展充满期待。这些架构能够解决多种视觉任务,甚至多个领域的任务。
我们研究的 预印本以及 代码和模型均已公开。
- 预印本 https://arxiv.org/abs/2010.11929
- 代码和模型 https://github.com/google-research/vision_transformer
Share Http URL: http://www.wittx.cn/get_news_message.do?new_id=1125

Best Last Month
Information industry by wittx

Information industry by wittx
Information industry by wittx

Information industry by wittx

Information industry by wittx

Information industry by show
Information industry by wittx

Information industry by wittx
Information industry by wittx

Information industry by wittx



