
-
News Message
Multi-agent pathfinding 传统方法和强化学习结合的多智能体行程规划
- by wittx 2022-11-27
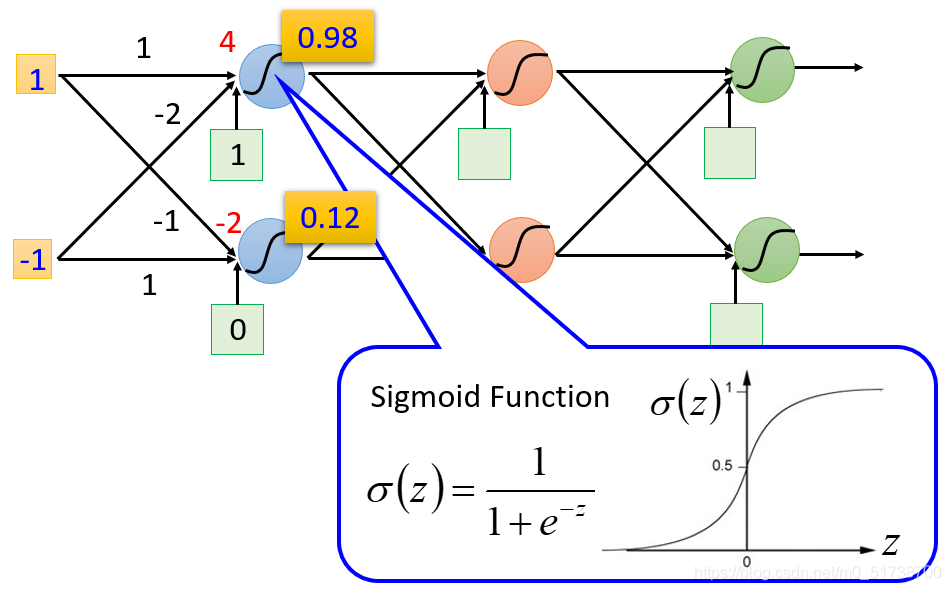
Multi-agent navigation based on deep reinforcement learning and traditional pathfinding algorithm
A*+RL
基本可以用下面这一张图来概括
traditional pathfinding algorithm +RL 就是用强化学习来决定执行 传统pathfinding algorithm(例如A*)的动作 还是 其他动作。
文章中的其他动作虽然简要提到机器人的线速度和角速度,但是总结一些还是前进一格子,后退一格,左拐,右拐,停(跟之前的上下左右停其实差不多。。。。。。)

动作规定 上图中 method M表示的就是传统pathfinding algorithm(例如A*), 就是A*的动作。所以他们的强化学习学的东西就是 学 这六个离散动作。与之前的方法的唯一区别就是加入 的动作。
state:
作者自己在unity3D上的简要环境,一个机器人带有45方向个传感器,45个方向感知的东西, 传感器的感知范围为d长度。

如果某个方向上存在障碍,感知到的东西就是(0, ), 如果是其他智能体,感知到的东西就是(1, ),如果没有东西,文章也没细说,估计是(0, 0)吧。。
这状态也太简单了吧。。至少也得加入下A*的轨迹信息之类???
reward:
奖励定义的有点意思:
第一项,如果采用传统pathfinding algorithm(例如A*),也就是 ,就加一个正奖励。
第二项:如果采用的动作撞到了障碍物或者墙壁或者其他智能体,就扣一个比较大的分数,到了终点就+一个正分。

第三项:每一步 step time 惩罚一点,

各个奖励的具体设置如下:

T是他们设置的每一个episode的最大长度,小车如果在这T时间内到不了终点就重置小车的起点位置终点之类,为了达到终点的path轨迹总体奖励大于0,他们设置了如上参数。其中T=10000
使用的强化学习算法是PPO,参数如下

实验结果

Pure RL Method 估计就是不加 动作的强化学习算法,成功率还是有点提升的。
在下面几个随机新环境下测试泛化能力

结果,比起Pure RL Method还是高很多的,毕竟了A*算法保底吧。

比较纳闷几点
- 感觉应该给state加点A*轨迹信息吧。。
- 每时每刻都需要给所有的agents都重新规划一条路径,这样计算量太大了吧.(因为如果小车采用除a0外的动作,小车可能就走到新的位置上,那么原来位置规划的A*轨迹就不能用了吧)(文章最后也提到了句计算量大, 不知是不是这样原因)

3.在泛化性实验结果上,训练的时候环境有没有这几个环境呢?还有小车之所以在这几个新环境下成功率比Pure RL Method 高很多,估计小车学出来的基本都是从用a0的动作吧。应该再跟传统pathfinding algorithm(例如A*)比较下,如果是靠都采用a0的动作成功率才高很多的话,那就没必要了。
总的来时,使用A*来保底还是有点意思的,奖励设置也挺好的。
补充另外一篇类似文章
MAPPER: Multi-Agent Path Planning with Evolutionary Reinforcement Learning in Mixed Dynamic Environments,
可以用下面一张图来概括:

state:
三个channels
- channel1:current observed static obstacles,障碍物和其他车的位置
- channel1:其他车的轨迹序列,同一辆车的轨迹序列的值,不同时间刻不同。encode the trajectory with different grayscales in time
- A* 规划的路径,估计也不是每时每刻都规划,那样太费时。文章中提到The reference path update frequency could be much lower than our reinforcement learning-based local planner.
actions:
9个动作。south, north, west, east, southwest, northwest, southeast and northeast,stop,没什么意思。
Reward Design

每一步惩罚一下,冲突了惩罚很大,回到上一步的地点惩罚,偏离A*轨迹惩罚,到达终点+30.
RL 算法
Multi-Agent Evolutionary Reinforcement Learning, A2C + Evolutionary + curriculum learning。

结果
成功率比传统的LRA*高一点吧。

Share Http URL: http://www.wittx.cn/get_news_message.do?new_id=1051

Best Last Month

Medical science by wittx

Information industry by wittx

Information industry by wittx
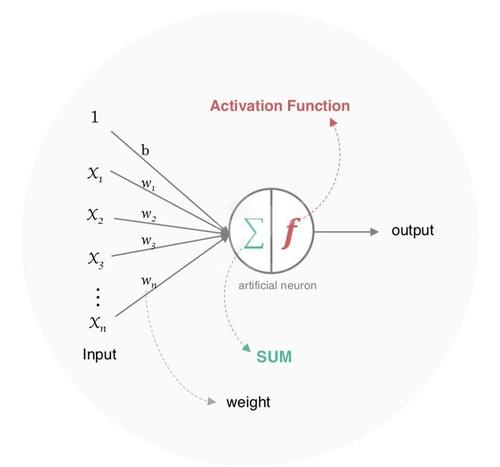
Information industry by wittx

Information industry by wittx

Information industry by wittx

Information industry by wittx
Information industry by wittx
Information industry by wittx
Information industry by wittx






