
-
News Message
AlphaPortfolio
- by wittx 2022-11-27
AlphaPortfolio: Direct Construction Through Deep Reinforcement Learning and Interpretable AI
Cong, Lin and Tang, Ke and Wang, Jingyuan and Zhang, Yang, AlphaPortfolio: Direct Construction Through Deep Reinforcement Learning and Interpretable AI (August 1, 2021). Available at SSRN: https://ssrn.com/abstract=3554486 or http://dx.doi.org/10.2139/ssrn.3554486
1.摘要
我们通过深度强化学习直接优化投资组合管理的目标——替代传统的监督学习范式,这些范式通常需要对收益分布或风险前提进行第一步估计。在最近的人工智能突破的基础上,我们开发了多序列神经网络模型,专门针对金融数据的显著特征,如非线性和高维度,同时允许在没有标签和与市场环境和状态变量相互作用的情况下进行训练。我们的AlphaPortfolio产生了惊人的样本外表现(例如,夏普比率超过2,每月重新平衡的风险调整阿尔法超过13%),在各种市场条件的经济限制下(例如,排除小股票和卖空)都很稳健。此外,我们将AlphaPortfolio投射到更简单的建模空间(例如,使用多项式-特征敏感度),以揭示投资业绩的关键驱动因素,包括其旋转和非线性。更广泛地说,我们强调了深度强化学习在金融和 "经济提炼 "模型解释中的效用。
关键词:人工智能、资产定价、可解释的人工智能,机器学习、投资组合理论、批量/离线强化学习。
2.引言
对于传统的投资组合管理,首先需要最小化定价误差或从历史样本中估计风险溢价,然后组合资产以实现投资目标。这种方法有严重的缺点,因为第一步的估计误差很大,而且两步的目标不一定一致。提取与投资组合目标并最大化直接相关的信号在直觉上很有吸引力,但却没有得到充分的探索。此外,金融或经济数据往往是高维的、有噪音的和非线性的,具有复杂的交互效应和快速、非平稳的,使得传统的计量经济学工具无法发挥作用。最近的研究积极采用机器学习(ML)或神经网络来解决传统两步法下的挑战。虽然有些取得了重大进展(如Freyberger, Neuhierl, and Weber, 2020; Feng, He, and Polson, 2018),但许多在合理的经济限制下并不稳健,如Avramov, Cheng, and Metzker(2019)所讨论的。
为了克服上述挑战,我们采取了一种新的和数据驱动的方法来直接优化投资组合,利用深度强化学习(RL)的力量--一类被证明在计算机视觉、互动游戏和自动驾驶等应用中有效的AI模型(例如。Mnih, Kavukcuoglu, Silver, Rusu, Veness, Bellemare, Graves, Riedmiller, Fidjeland, and Ostrovski, 2015; Silver, Schrittwieser, Simonyan, Antonoglou, Huang, Guez, Hubert, Baker, Lai, and Bolton, 2017)。我们的关键见解是,鉴于金融市场和资产价格动态的复杂性,通过灵活的建模空间使用试错法进行搜索,以最大化投资组合构建的性能指标,比试图估计资产收益分布的某些时刻(如预期收益或方差)或准确定价更有效,而不管它们与构建理想投资组合的相关性。因此,我们开发了一个灵活的深度学习结构来捕捉资产收益的非线性、路径依赖性和截面联系,同时让数据决定在后台强调SDF的哪些时刻或哪些资产的收益,以便直接最大化投资组合的性能指标。
我们使用RL——一种从多臂强盗问题和大规模马尔科夫决策过程的近似解决方案中衍生出来的方法,因为历史上的最佳投资组合没有被标记,交易可能与市场状态相互影响。RL需要与环境进行在线互动以产生额外的数据,或者利用随机梯度下降来进行历史数据的复杂模型搜索(例如Friedman,2002)。训练RL模型模仿了实践者实际开发策略的方式,从庞大的策略空间中尝试试探性的策略,并根据性能反馈de Prado(2018)逐步优化它们。我们是第一个强调RL相对于广泛应用的监督学习框架的潜在优势,并通过方法论创新使RL适应多序列学习。我们的研究还为计算机科学中关于离线深度RL的新兴文献提供了补充,为其在投资组合管理和投资建议中的应用开发了一个框架。
尽管人工智能模型的功效和适用性,先进的人工智能工具的黑箱性质可能会阻碍它们在金融和经济领域的广泛使用,因为解释是不可或缺的。像许多其他模型一样,我们的深度RL方法受到了关于算法的复杂性质和缺乏透明度的批评。同时,在一个被歧视和不公正分割的世界中,将人工智能中的所有偏见归咎于训练数据也是不够的;理解模型作为改善算法公平性的起点也构成了一个紧迫的问题。然后,我们的第二个目标是了解我们模型中的各种创新是如何促进性能的,并引入 "经济提炼",通过将复杂的人工智能模型投射到线性建模或自然语言空间,使其具有更大的可解释性和透明度。我们设计的多项式敏感性和文本因素分析不仅为我们的人工智能模型提供了初步的见解,而且还可以用于社会科学的其他应用中。
具体来说,我们采用了最新的序列表示提取模型(sequence representation extraction models, SREM),如Transformer编码器(TE)和长短期记忆(LSTM),以便灵活有效地表示和提取来自输入特征的时间序列的信息,如公司的基本面和市场信号,即环境状态。我们开发了一个基于深度神经网络的面板数据分析,加入了我们新颖的跨资产注意力网络(cross-asset attention networks, CAANs),捕捉跨资产的属性互动。然后,我们生成一个 "赢家得分",对资产和交易(政策和行动)进行排名,随后评估投资组合的表现,即考察回报。我们强调的不是模型的任何具体函数形式或调整参数,而是数据驱动的RL方法,它将资产收益的联合分布作为未知数,观察交易行动的结果及其与环境的互动(例如,在有或没有交易影响市场状态的情况下实现的夏普比率),测试每种状态下的一系列行动(例如,各种组合权重),然后动态地探索高维参数空间,在没有噪音或潜在的错误指定的中间步骤下实现目标最大化。我们表明,SREM和CAAN的结合(捕捉资产收益中的非线性、截面联系和路径依赖),以及通过RL的直接构建都有助于提高性能。我们还讨论了AlphaPortfolio如何允许一般管理目标以及包含交易成本、动态预算和依赖经验的偏好的市场互动。
我们基于深度强化学习的 "直接构建 "(投资组合)极大地改善了样本外(out-of-sample, OOS)的投资组合表现,在施加各种经济约束后,结果依然稳健。在对美国股票的说明性研究中,我们使用了12个月历史窗口中的数百个公司特征和市场信号作为预测变量,类似于Freyberger, Neuhierl, and Weber (2020)。在基线规范中,我们专注于随后12个月的平均OOS夏普比率作为投资者的目标,并训练一个投资组合模型(此后称为 "AlphaPortfolio "或 "AP"),每月重新平衡,在全部测试样本(1990-2016年)和不包括微型股(基于市值的10%或20%)的子样本上产生的夏普比率始终高于2。在控制了各种因素(CAPM、Fama-French-Carhart因素、FamaFrench-Carhart加流动性因素、Fama-French五因素、Fama-French六因素、Stambaugh和Yuan因素、Q4因素)后,年化超额阿尔法也一直超过13.5%。AP的一般性能指标(如周转率和最大跌幅)明显优于大多数已知的异常值和机器学习策略的指标。
就指定的投资组合管理目标而言,基于RL的AP始终实现了较高的OOS夏普比率(在整个测试样本的早期达到4.7并高于1.4),比两步传统构造下的TE-CAAN的性能高出一倍以上。深度学习(例如TE,一种尖端的人工智能工具,通常用于有监督的机器翻译,以解决循环神经网络中的消失和爆炸梯度问题),通过更好地处理金融数据和资产回报动态的高维度、非线性、路径依赖性等,显然有助于提高性能,但相对于普通的TE模型,CAAN也大大提高了OOS性能(例如,夏普比率提高0.4)。研究结果是稳健的,因为它们不是由空头头寸、特别权衡、高频交易或特定行业部门驱动的;在替代成交量定义、排除未评级和降级公司以及最近几年或在不同市场情绪、波动性和流动性的事件中限制测试样本的情况下,表现仍然优异。因此,AP对施加各种经济限制是稳健的,Avramov、Cheng和Metzker(2019)认为这些限制会大大阻碍其他机器学习策略的表现。
我们的深度RL方法与早期的研究和常见的行业实践有根本的不同,因为它结合了灵活的、通过神经网络的数据驱动建模的力量和使用RL的直接优化。与监督学习不同的是,学习者在训练中被告知什么是正确的行动,RL通过试错搜索和利用环境的反馈来发现一些延迟奖励的最佳行动(Sutton and Barto, 2018, p.1)。在平均OOS月度夏普比率的背景下,奖励是 "延迟的",因为它是在多个月的窗口中计算的。一旦我们考虑到经理人的投资组合规模和交易成本等因素,一个月的投资组合构建可能会影响未来的市场环境,从而影响未来的投资组合构建。
我们强调,深度RL的应用不一定总是涉及在线互动,离线RL在社会科学中可能特别有用。与科学实验室不同,社会科学家通常不能通过在线互动产生数据,这是因为数据收集很昂贵(例如,在机器人、交易、教育代理或医疗保健方面)或很危险(例如,在自动驾驶或医疗保健方面)。此外,即使在在线互动可行的领域,我们仍然希望利用以前收集的数据来代替,例如,如果该领域很复杂,有效的归纳需要大型数据集。AlphaPortfolio的训练是离线RL,但它与环境互动,通过测试样本中的滚动更新产生新的数据。在这个意义上,我们的RL模型是一个混合模型,AP框架可以方便地被从业者和机器人顾问部署到交易和投资建议中。
除了阐明Deep RL在直接构建投资组合方面的这一理论优势,我们还旨在更好地解释AP。我们使用基于梯度的方法和Lasso将模型提炼成具有少量输入特征的线性模型,同时允许高阶项和特征互动。这种新颖的多项式敏感性分析本质上是将复杂的模型 "投射 "到线性模型的空间中。它通过结合代用模型和特征重要性分析的优势,增加了能够解释人工智能的进展。提炼出来的模型告诉我们驱动AP性能的特征。除了一些常见的嫌疑人,如托宾Q值,库存变化(ivc),流通股变化(delta so)等,也起着主导作用。此外,我们发现高阶项(如ivcˆ2)影响了AP的行为,但没有互动效应(这对估计资产的回报或定价内核仍然很重要)。最后,我们观察到短期的逆转,并确定了在整个过程中占主导地位的重要特征和其他轮流出现的特征。特别是,市场交易信号和企业的基本面和财务状况轮流占主导地位(相关度为-0.33)。
作为通过投影进行经济提炼的另一个例子,我们应用了文本因素分析,一种结合了神经网络语言处理和生成性统计建模优势的分析方法(Cong, Liang, and Zhang, 2018),来理解基于公司文件文本的AP行为。通过将其投射到自然语言空间,我们发现,AP买入那些10-K和10-Q中谈到销售、盈利、减亏等的公司股票,而卖空那些突出提到房地产、错误和企业事件等的公司股票。经济学提炼不仅提供了对复杂模型的初步解释,以便我们在市场环境或政策变化时避免人工智能应用的陷阱,而且还提供了对编码错误和模型脆弱性的理智检查。多项式敏感性分析和文本因素分析都是新的,补充了计算机科学中关于可解释人工智能和经济学中关于解释ML模型的尝试。
3.文章贡献
作为最早的将人工智能的最新突破应用于投资组合管理的金融研究之一,我们的论文有三个主要贡献。
- 我们开发了一个基于RL的框架来直接优化投资者的目标,该框架可以容纳未标记的数据和复杂的环境,并克服了传统两步法中的挑战。
- AP旨在处理金融大数据的显著特征,并优于大多数现有策略(传统的或基于机器学习的),特别是在施加合理的经济约束和限制之后。我们证明,通常用于机器翻译的尖端人工智能工具一旦适当地适应经济和金融应用,就可以在实践中有效和立即部署。
- 我们为社会科学中可经济解释的人工智能提供了一般的、可扩展的和直观的程序,补充了计算机科学和机器学习领域的努力。
4.模型和方法
在本节中,我们将重点介绍AlphaPortfolio的设计。图1展示了整体架构,它由三个部分组成。第一个部分需要使用SREMs,从每项资产的状态历史中提取一个表征。接下来,我们引入了一个跨资产注意力网络(CrossAsset Attention Network,CAAN),它将所有资产的表征作为输入,以提取捕捉资产之间相互关系的表征。第三部分是投资组合生成器,它从CAAN中获取每项资产的标量赢家得分,并得出最佳投资组合权重。重要的是,我们将这个AlphaPortfolio策略嵌入到一个强化学习框架中,以训练模型参数,使评估标准最大化,如OOS夏普比率。我们在Cong, Tang, Wang, and Zhang (2020)中描述了深度序列建模的发展,在附录A中描述了强化深度学习的基础知识。

AlphaPortfolio的整体架构 为什么要用RL进行一步式组合优化?正如我们在引言和第2节中所描述的,一步法可能比两步法间接优化的组合效果更好。此外,RL可以更好地处理复杂的目标和与环境的相互作用,这允许纳入预算约束、长期目标等。
4.1.序列表征的提取
一项资产的收益分布与它的历史状态有着密切的关系。资产的历史状态自然地形成于序列的历史观察值。我们用向量 来表示资产i在时间t的状态历史,它由资产特征/公司特征组成,例如,在第4.1节中给出的。我们把时间t的最后K个历史持有期,即从时间t-K到时间t的时期,命名为t的回望窗口。一个例子是当我们构建第13个月的投资组合时,前12个月的特征。一个资产在回望窗口的历史状态被表示为一个序列:,其中。
对于每个资产i,SREM从其状态历史中学习表征(我们省略时间t)。值得注意的是,SREM可以是任何一种深度序列模型,如RNN、LSTM等。在本文中,我们关注两个最前沿的深度序列模型之一(Cong, Tang, Wang, and Zhang, 2020),即Transformer编码器(TE)。我们在第5节和附录C中讨论了另一个,即带有历史注意力的LSTM(LSTM-HA)。TE和LSTM-HA都是专门为处理序列信息而设计的,在表示非线性时间序列模块的复杂信息方面很出色。
循环神经网络(RNN)的变种和我们提出的基于TE(或基于LSTM)的SREM最近都被用于神经机器翻译中。与RNN不同,TE通过减少网络路径长度使序列中的长距离依赖关系更容易学习,并通过减少对输入的禁止性顺序的依赖,从而允许更多的并行运算。

Transformer编码器构造,好像是一样的? 图2展示了一个普通TE的结构。这里的编码器是由几个相同的层堆叠而成。每层有两个子层。第一个子层是一个多头自我关注机制,我们为AlphaPortfolio采用并修改了这个机制,第二个子层是一个简单的位置全连接前馈网络。此外,每个子层都采用了残差连接和层的归一化。我们在附录C中详细介绍了实施细节。总的来说,TE将序列输入编码到向量空间中,为
其中。是步骤k的被编码的隐藏状态,它考虑到了所有其他步骤。我们把中的所有步骤合并(concat)起来,作为资产的表征:,这其中包含了中所有元素的全局依赖。在我们的模型中,所有资产的表征向量都是由同一个TE提取的,这意味着所有资产的参数是共享的。通过这种方式,TE提取的表征是相对稳定的,一般适用于所有可用的资产,而不是某个特定的资产。
如前所述,学习长程依赖是使用基于递归的序列模型(即RNN和LSTM)时的一个关键挑战。在我们设计的序列表示提取模块中,LSTM-HA通过引入历史注意力机制来解决这个问题,Transformer架构连接了序列中的所有位置,可以有效地提取短期和长期依赖关系。接下来我们分别使用LSTM-HA和TE作为第五步SREM,并比较它们的性能。对于时间t的第i只股票,由SREM提取的表征被称为。它包含了股票i从时间t - K + 1到时间t的历史状态的顺序和全局依赖。
4.2.跨资产注意网络和赢家得分估算
之前在计算机科学中应用基于RL的模型的尝试通常止于具有softmax归一化的资产表示(Jin和El-Saawy,2016;Deng、Bao、Kong、Ren和Dai,2017;Ding、Liu、Bian、Zhang和Liu,2018)。我们提出一个CAAN来描述资产之间的相互关系。请注意,我们对CAAN模块的设计部分受到机器翻译中自注意机制的启发(Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez, Kaiser, and Polosukhin, 2017)。

CAAN的整体构造,这里把收益和线性层相乘形成QKV,又不失经济意义,妙啊! 图3说明了CAAN的结构。具体来说,给定资产表征(我们省略时间t,但不失一般性),我们计算出资产i的查询向量、密钥向量和价值向量,(反正就是qkv)具体如下:
其中,、和是与资产无关的待学习参数矩阵。资产j与资产i的相互关系被建模为使用资产i的 来查询资产j的密钥,即与之间的内积(但被调整大小)。
然后,我们用归一化的相互关系作为权重,将其他资产的值向量加起来,成为一个衰减分数。
请注意,赢家得分是根据所有其他资产的注意力来计算的。这样,CAAN就说明了所有资产之间的相互关系。
我们使用全连接层将注意力向量转化为赢家得分,即,其中和是连接权重和学习偏差。赢家得分表示资产i在第t个持有期被选为多头的可能性。到目前为止,该模型嵌入的经济意义不大,因为赢家得分较高的资产不一定对投资组合的业绩有积极的贡献。它只是一个灵活的结构(具有高维参数),用于生成投资组合,以后用RL进行训练。
4.3.组合生成
给定个资产的赢家得分为。 接下来,AP构建了一个多空组合,在赢家得分高的资产中持有多头,在赢家得分低的资产中持有空头。具体来说,我们首先按照胜者得分从高到低的顺序对资产进行排序,并获得每个资产i的序列号。让表示投资组合的多头和空头部分的分界线,将组合分为和。即如果,资产i进入组合,每个资产的权重计算为;如果,则。
其余的资产没有明确的买/卖信号,因此不包括在投资组合中。为了简单起见,我们用一个向量来记录两个组合的所有信息。我们设置了一个长度为向量,值为的拼接。
请注意,在我们充分训练模型之前,由于TE和CAAN的参数都是随机启动的,AlphaPortfolio在开始时可能表现得很糟糕。在适当的训练之前,高的赢家得分并不意味着它是更好的投资资产。经过训练后,根据赢家得分构建投资组合可以产生导致高绩效指标的投资组合。我们接下来介绍一下训练过程。
4.4.强化学习优化
我们将AP嵌入到一个具有连续代理行动的RL游戏中来训练模型。其中一个情节 - 代理在RL中与环境互动的一个完整回合(在我们的背景下为T期投资)被建模为一个RL代理的“状态-行动-奖励”轨迹。即:
在历史时间的市场历史状态,被表达为一个张量。被指定为AP给出的组合向量,其中元素表示代理在t时刻投资于资产i的组合权重。然后,就是的回报。
让表示投资组合经理的目标,以奖励的轨迹作为输入。例如,可以是一个投资组合的构建和交易,是持有该投资组合的回报,而可以是使用12个月窗口的回报计算的夏普比率。构建投资组合的目标可以非常普遍,包括交易成本(将回报率定义为回报率减去交易成本)或预算约束(将预算作为状态的一个变量)或投资组合经理的失败(例如,如果轨迹中的某个回报率太负,为零)。我们在实证分析中探讨了的各种版本。
一般来讲,平均奖励可以表示为。回顾一下,对应的是拟议的AP的参数。第五个部分来自SREM(序列再现提取模块)。对于基于TE的SREM,参数包括多头转换矩阵、注意力转换矩阵和Ward网络的权重矩阵。第二部分来自CAAN模块,为此我们有一个查询转换矩阵、一个关键转换矩阵和一个值转换矩阵。这些矩阵中的条目都是需要估计的参数。此外,还包括权重矩阵和偏置,这些都是用来将注意力向量转化为赢家得分的。
强化学习模型的优化目标是找到一组参数。我们用梯度提升的方法来迭代优化模型参数:,其中为学习率。在实证检验部分,一个事件被定义为一年的投资,包含12个交易期,是使用我们采用的深度学习框架自动计算的。
5.实证表现:美国权益市场研究
5.1.数据描述
我们现在将AlphaPortfolio模型应用于美国的公共股票。我们的基线样本期是1965年7月至2016年6月,有176万个月度资产观测值。月度股票回报数据来自证券价格研究中心(CRSP)。我们遵循文献的标准,关注在美国注册并在Amex、Nasdaq或NYSE交易的公司的普通股。公司的资产负债表数据来自标准普尔的Compustat数据库。为了减少由于回填造成的生存偏差,我们还要求一个公司在数据集中至少出现两年来训练模型。对于OOS测试,我们只要求一个公司在数据集中出现一年。
与Freyberger, Neuhierl, and Weber (2020)类似,我们将公司特征和市场信号作为原始输入特征来构建,这些特征分为六类:价格信号,如月度回报率;投资相关特征,如库存占总资产的变化;盈利能力相关特征,如经营性资产回报率;无形资产,如经营性应计费用;价值相关特征,如账面市值比;交易摩擦,如日平均买卖价差。我们考虑了投资组合构建月份之前12个月的滞后特征。每个输入变量都被视为只在其公开后的一个月内可用,这个日期滞后于报告日期开始。如果一个变量没有以月度频率报告,我们将其视为与前一个月没有变化。总的来说,我们在任何时候对每项资产都有51次12个输入特征。附录B描述了输入特征的构建。AP框架允许纳入宏观经济变量和其他替代数据,这可能会改善其性能,我们把它留给未来的研究。
5.2.实证检验和结果
我们为AP指定的基线目标是OOS夏普比率,这是很自然的,而且被学术界和从业人员广泛使用。为了训练模型,我们使用了从1965年7月到1989年底的数据,并遵循第3节中概述的投资组合的构建,选择G,使多头和空头各占所有可用股票的10%。虽然已知RL允许行动(在我们的环境中的交易)和环境(如市场状态变量,价格影响等)之间的相互作用,但在基线中,我们关闭了相互作用,专注于RL带来的试错搜索好处。正如我们在第4.4节中所说明的那样,与市场环境相互作用的其他目标可以很容易地被接纳。请注意,RL并不区分训练集和验证集。我们用历史数据来代表环境,用奖励来判断训练的质量并调整AP的超参数。在这个意义上,模型的选择被嵌入到训练期间的探索步骤中。OOS测试确保在评估AP性能时不会出现过度拟合和模型选择偏差。
开始时,我们随机初始化参数(在参数空间的大范围内),从训练集中随机抽出一个月,不做替换,并使用前12个月的输入(包括抽出的月份),然后评估随后12个月的表现(例如,基于12个月的回报观察计算的夏普比率)作为更新参数的奖励。我们并不假设这些月份是即期的,而是在本质上绘制一个24个月的窗口,而不重复使用任何窗口。我们对训练集的剩余月份重复这一步骤,直到我们用尽训练集的所有月份。我们把这个多步骤的过程称为epoch。在我们的实施中,我们使用了30个epochs,这足以让参数收敛。
训练结束后,我们对从1990年开始的样本进行AP测试,每月进行一次再平衡。我们所有的结果都是在样本外获得的,而不是依靠传统统计测试中采用的样本内预测性。这对于防止低信噪比金融数据的过度拟合至关重要。请注意,AP模型在我们的测试样本中每年都会进行微调(滚动更新),这使得我们的模型一旦被部署为实战策略,就会成为离线和在线RL的混合。换言之,在看到一年的表现后,我们使用额外的数据来更新模型参数。在这里,我们使用6个 epochs,每个包含12个步骤。学习率同样设置为1e-4,然后在2个epochs后为5e-5,4个epochs后为1e-5。即使人们可以在更高的频率下对模型进行微调,比如每月一次,我们使用年度频率来避免对每月变化的过度拟合和在高频率下更新深度学习模型的高计算成本——这一点在Gu, Kelly, and Xiu (2020)中也有讨论。由于信息陈旧,以较低的频率更新往往会降低OOS性能,这不利于获得卓越的性能。
表1报告了主要结果。第(1)-(3)栏显示了AP收益的各个时刻以及换手率等指标。在完整的测试数据集中,AP达到了2.0的OOS夏普比率,当我们将训练和测试限制在大型和流动的股票上时,甚至更高(在第(2)和(3)栏中,我们要求股票在市值的前90或80百分位)。显然,AP的表现不是由微型股票驱动的,可以在没有流动性问题的情况下实施。如果我们把注意力限制在市值前90个百分点的股票上,1990年初AP投资的一千美元到2016年底将变成91,140美元。

实证检验的主要结果,在样本外(OOS)AP有着十分惊艳的效果。 请注意,AP并没有像许多其他模型一样,根据回测结果挑选小型和非流动性的股票--这个结果有些令人惊讶。我们将此归因于这样一个事实,即,即使小型和非流动性的股票倾向于高预期收益,它们也会大大增加投资组合的波动性。我们采用夏普比率的直接优化,而不是特征排序,有效地避免了小型和非流动性股票。
表2进一步证明了RL和AI在投资方面的功效。A组将AP与Freyberger, Neuhierl和Weber(2020)的 "非参数"(NP)模型和投资组合策略进行了比较。AP的表现优于文献中大多数其他基于机器学习的策略。我们选择NP作为基准,除了因为我们使用了与他们论文中类似的公司特征作为投入外,NP很可能是资产定价领域表现最好的3-5个机器学习模型之一。1991-2014年,NP在其测试样本上取得了更高的夏普比率。一旦我们排除了非流通股和小股票,AP就明显优于NP,这与Avramov、Cheng和Metzker(2019)的研究结果一致,即最近的机器学习策略的表现往往来自小盘股和非流通股。这里的优越性能并没有使NP等其他模型失效,因为它们的重点是最小化定价误差或估计定价内核,而不是直接优化投资组合性能。

除了说AP很好,还需要对已有模型进行拉踩。 值得一提的是,赢家得分并不只是另一个预期收益的估算器。RL同时考虑到了预期收益和其他可用资产的时刻。为了了解RL如何增加AP的性能,表2的B组显示了当我们按照传统的两步法,首先使用监督学习下的TE来预测股票收益,然后形成预期收益排序的投资组合时的OOS性能。我们注意到,OOS的夏普比率在经过市值调整的权重下可以达到0.8,在同等权重(组合等权)下接近2。一方面,这表明传统的两步投资组合构建下的TE仍然优于许多其他策略(基于机器学习或基于异常/排序,因为TE作为一个灵活的深度神经网络更好地捕捉了非线性和路径依赖信息)。另一方面,传统模型与基于RL的AP模型相比,其性能相形见绌,突出了我们一步到位的RL的效用。例如,在实践中比等权重更可行的全样本上的价值加权投资组合,其OOS夏普比率为0.36,而AP的夏普比率为2。换句话说,如果我们使用赢家得分作为预期收益的估计,并使用等权重或价值加权,该投资组合将大大低于AP的表现。
最后,表2中的C组显示了我们对CAAN的创新是如何进一步促进AP性能的。仅仅使用TE,RL仍然取得了比其他ML模型(在小组A中通常表现不如NP开始)和两步法(如小组B所示)更高的OOS回报和夏普比率,以及更低的换手率和最大回撤。然而,CAAN在RL的基础上大大改善了OOS的表现,在三个测试样本中平均增加了0.33的夏普比率和近4%的年化收益,同时降低了40%的换手率。虽然这里没有报告,但当我们使用LSTM实现AP时,CAAN对性能的影响甚至更大(附录C2)。
5.3.经济限制和模型稳健性
太多了,感兴趣看原文吧,反正就是很显著。
6.经济提炼
我们必须认识到,与遗传学和物理规律不同,商业环境和金融市场是不断发展的。政策和消费者的偏好一直在变化。我们不能总是把机器学习包和大数据分析从货架上拿下来,盲目地应用于经济和金融领域的问题,只因为它在回测中似乎预测得很好。此外,大数据和人工智能的使用可能会出现对个人群体的偏见。由于社会科学中的快速和非平稳动态,这些危险尤其令人担忧。解决这个问题的一个必要步骤是了解复杂的人工智能和机器学习模型。
为此,我们引入了一个 "经济提炼 "程序。在这一部分,我们描述了多项式特征敏感性分析。其主要思想是将AP投射到一个更简单、更透明的建模空间。蒸馏后的模型 "代表 "或模仿复杂的人工智能模型,因此可以揭示原始模型的重要属性,并有助于对其进行经济解释。
为了说明问题,我们使用算法1将AP投射到线性回归的建模空间。我们首先表达了一只股票的历史特征对其在TE-CAAN系统中的得分的功能。然后,我们检查每个特征的边际贡献,并在其他特征发生变化时检查其比较静态。该程序使我们能够确定模型中最重要的变量(或其高阶项或交互项)。接下来,我们使用这些变量及其高阶项和交互项作为输入变量来估计Lasso回归模型。我们设置惩罚参数,使50-60个输入被选中,这与AP中输入时间序列的数量相当。
为了补充分析,在附录D中,我们还将AP的赢家得分回归到每个公司在公司文件中讨论的各种主题的相应文本负荷。使用文本因素将模型投射到自然语言空间(Cong, Liang, and Zhang, 2018; Cong, Liang, Yang, and Zhang, 2019)有助于增强我们对AlphaPortfolio行为方式的理解。
6.1. 多项式敏感性分析
对于经济提炼,我们采用基于梯度的特征重要性方法来确定AP主要取决于哪些特征。我们用来表示TE和CAAN的组合网络,它将资产的状态历史X映射到其赢家得分s。被用于表示的元素,为特征的值。给定资产状态历史数据,网络s对特征的敏感性可以被计算为:
其中表示中除去特征的其他元素。
在我们使用PyTorch实现AP的过程中,梯度来自深度学习包中的autograd模块。对于一个市场中所有可能的股票状态,股票状态特征xq对赢家得分s的平均影响是:
其中代表随机变量的概率密度函数;是一个遍历所有的积分。根据大数定律,给定一个包含I个股票和N个持有期历史状态的数据集,可近似的表示为:
其中是第i个股票第n个持有期的历史状态;表示与第i只股票的历史状态同时存在的其他股票的历史状态。
我们使用来衡量单资产特征的对整体赢家得分的影响。
然后我们生成具有最重要特征的多项式的项。对于OOS时期的每个月,我们可以通过使用Lasso将赢家的分数与选定的项进行回归来提炼AP模型。表12中的结果显示,即使是提炼出来的线性模型在OOS测试中也取得了显著的性能。这里poly = 1基本上是一个线性回归。人们可以在蒸馏练习中包括更高等级的多项式项,为了简洁起见,我们停止在2度(2阶)。请注意,提炼利用了训练有素的AlphaPortfolio模型的知识,并在原始模型中表现不佳。因此,我们不应该或不可能有效地使用提炼出来的模型,来代替AlphaPortfolio进行交易。

经济蒸馏的具体算法 
即使是使用多项式,也能用已有的知识,获得惊艳的效果。 6.2.重要特征和动态模式
我们发现,一小部分特征决定了我们算法的性能。例如,库存变化(ivc)在我们的算法中起着关键作用,在1度和2度多项式中都有超过80%的概率被列入最高贡献因素。Thomas和Zhang(2002)首次记录了ivc可以负向预测股票的未来收益,这与企业的盈利管理是一致的。鉴于2002年后ivc仍然发挥着重要的作用,该反常现象并没有被交易掉。短期以前的回报率(ret 11和ret 10)是强烈的负值,特别是对于有大型股票的投资组合,意味着短期逆转,这与Avramov、Cheng和Metzker(2019)一致。请注意,某些公司特征的符号在不同的滞后期是不同的,这可能反映了AP的路径依赖性质。
其他因素包括托宾Q值、税前利润率(ipm)、现金和短期投资与总资产的比率(C)、特异性波动率(Idol vol)等也很突出。其中,特异性波动率(Idol vol)、一个月内每日最大收益率(Ret max)等是与交易有关的套利约束和市场信号;外部融资增长(fcf)、折旧和税收前营业收入(ipm)等是与公司基本面有关的财务信号。交易信号通过错误定价渠道影响股票收益,而金融信号则可能通过风险渠道影响股票收益(Livdan, Sapriza, and Zhang, 2009)。这些模式不仅意味着未来的研究可以专注于一小部分经济机制和变量的时变相关性,而且还告诉研究人员要考虑哪些特征的非线性效应。

蒸馏出来的一些显著影响特征,与前人的研究是相符的。 7.文章结论
我们提出了基于深度强化学习(RL)的投资组合管理,这是一种比传统的间接投资组合构建框架更好的选择。我们开发了一个建立在最新人工智能创新基础上的多序列学习模型,以有效捕捉经济数据和市场环境的高维、非线性、噪音、互动和动态性质,然后使用RL对其进行优化。由此产生的AlphaPortfolio在各种经济和交易限制以及管理目标下产生了极好的OOS性能,使该框架可被从业者部署到交易和投资建议中。
我们的框架和经验发现对RL在社会科学中的效用和经济上可解释的人工智能的重要性有更广泛的影响。与需要通过理想行为的例子来了解环境的监督学习不同,RL代表了一种在复杂环境或行动空间中进行目标导向学习的新方法。深度RL经常被用于语音识别、自然语言处理、计算机视觉、互动游戏等方面的应用,并取得了巨大的商业成功。(亚马逊Alexa、苹果Siri、AlphaGo和谷歌Android是领先的例子)。此外,大多数使用回归、SVM和神经网络的模型都有基于RL的实现方式。投资组合管理只是RL处理复杂社会科学问题的潜在应用之一,这些问题具有明确的目标,但用于得出完整解决方案的预先存在的知识或标记数据有限。
此外,我们的 "经济提炼 "不仅揭示了驱动AlphaPortfolio业绩的关键公司特征(包括其旋转和非线性),而且还为解释机器学习和人工智能在商业实践和社会科学中的应用提供了具体的支柱和增量步骤。我们的多项式敏感性分析对计算机科学的现行做法进行了创新,并允许极大的灵活性。例如,如果人们认为一个特征的三阶和四阶项很重要,就可以把它们放进去。文本因素分析源于主题建模和词嵌入,构成了使用自然语言来更好地解释模型行为的许多可能性之一。这两个程序都是将复杂的模型投射到透明和可解释的空间中。我们的经济提炼方法的其他应用构成了有趣的未来研究。
Share Http URL: http://www.wittx.cn/get_news_message.do?new_id=1050

Best Last Month
Information industry by wittx
Information industry by wittx

Office culture and education by wittx
Information industry by wittx

Computer software and hardware by wittx

Information industry by wittx

Information industry by wittx

Information industry by wittx
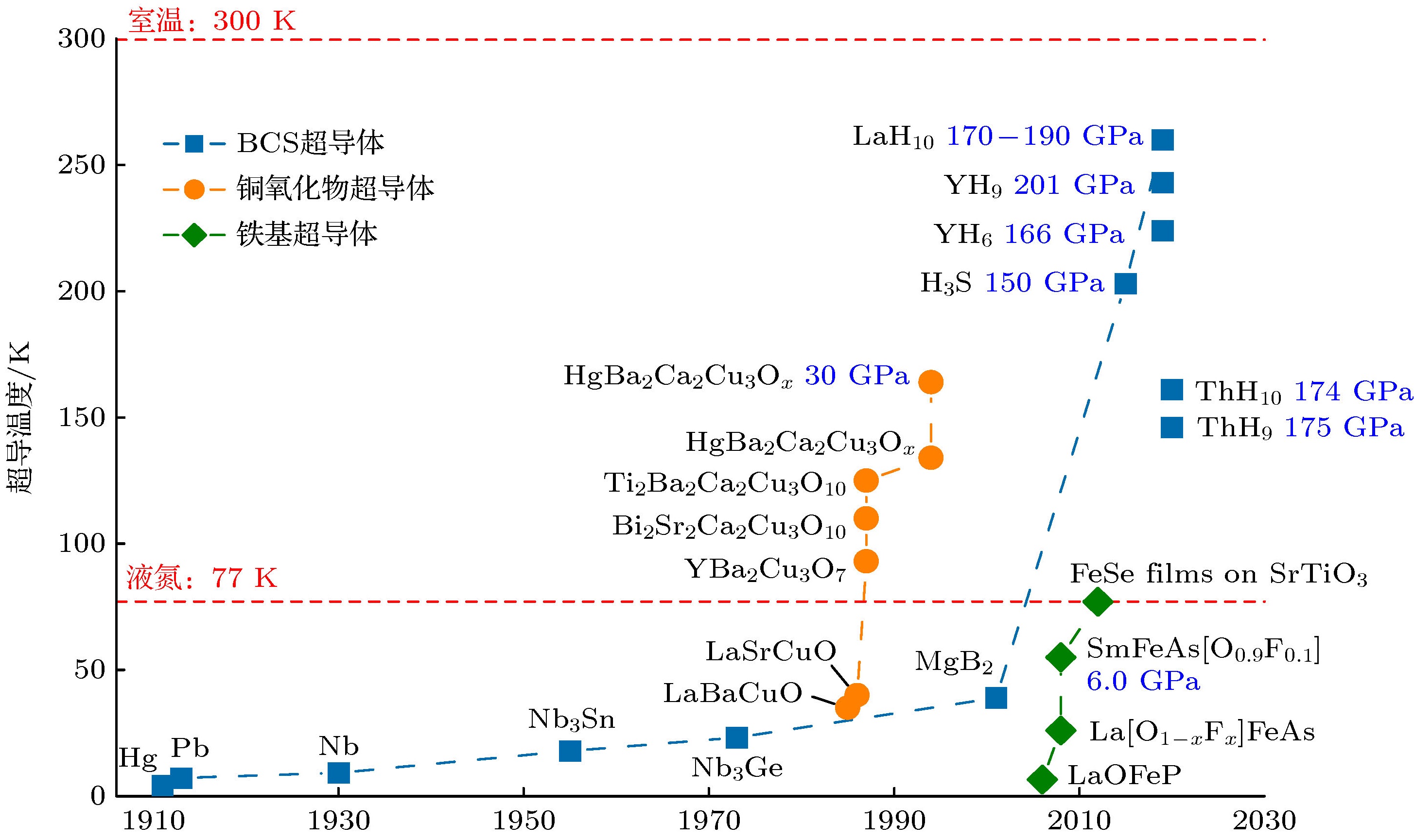
Information industry by wittxSuperconductor Pb10-xCux(PO4)6O showing levitation at room temperature and atmospheric pressure
Information industry by wittx
