
-
News Message
强化学习在金融领域中应用的论文推荐
- by wittx 2022-11-23
Reinforcement learning in market games(arxiv 0710.0114)
Edward W. Piotrowski, Jan Sladkowski, Anna Szczypinska
金融市场投资就像许多的多人游戏一样——必须与其他代理人互动以实现自己目标。其中就包括与在市场上的活动直接相关的因素,和影响人类决策及其作为投资者表现的其他方面。如果区分所有子博弈通常是超出希望和资源消耗的。在这篇论文中研究了投资者如何面对许多不同的选择、收集信息并在不了解游戏的完整结构的情况下做出决策。论文将强化学习方法应用于市场信息理论模型 (ITMM)。尝试区分第 i 个代理的一类博弈和可能的动作(策略)。任何代理都将整个游戏类划分为她/他认为子类,因此对给定的子类采用相同的策略。划分标准基于利润和成本分析。类比类和策略通过学习过程在各个阶段更新。
Dreaming machine learning: Lipschitz extensions for reinforcement learning on financial markets(arXiv 1909.03278)
J. M. Calabuig, H. Falciani, E. A. Sánchez-Pérez
论文考虑了一种用于在金融市场框架内构建新的强化学习模型的准度量拓扑结构。它基于在度量空间中定义的奖励函数的 Lipschitz 型扩展。具体来说,McShane 和 Whitney 被用于奖励函数,该函数由给定时间投资决策产生的收益的总评估定义。将度量定义为欧几里得距离和角度度量分量的线性组合。从时间间隔开始的所有关于系统演化的信息都被用来支持奖励函数的扩展,并且通过添加一些人为产生的状态来丰富这个数据集。论文中说到,这种方法的主要新颖之处在于产生了更多状态(论文中称之为“dreams”)以丰富学习的方式。使用代表金融市场演变的动态系统的一些已知状态,使用现有的技术可以通过插入真实状态和引入一些随机变量来模拟新状态。这些新状态用于为学习算法提供训练数据,该算法的目的是通过遵循典型的强化学习方案来改进投资策略。
Automatic Financial Trading Agent for Low-risk Portfolio Management using Deep Reinforcement Learning(arXiv 1909.03278)
自主交易代理是人工智能解决资本市场投资组合管理问题最活跃的研究领域之一。投资组合管理问题的两个主要目标是最大化利润和抑制风险。大多数解决这个问题的方法只考虑最大化回报。但是这篇论文提出了一种基于深度强化学习的交易代理,它在管理投资组合时,不仅考虑利润最大化,还考虑风险约束。论文中还提出了一个新的目标策略,让交易代理学会更偏向低风险的行动。这个新的目标策略可以通过超参数来调整最优行为的贪心程度来降低行动的风险。论文所提出的交易代理通过加密货币市场的数据来验证性能,因为加密货币市场是测试交易代理的最佳试验场,因为每分钟积累的数据量巨大,市场波动性极大。作为实验结果,在测试期间,代理实现了 1800% 的回报,并提供了现有方法中风险最小的投资策略。并且在另一个实验表明,即使市场波动很大或训练周期很短,交易的代理也能保持稳健的泛化性能。
Application of deep reinforcement learning for Indian stock trading automation(arXiv 2106.16088)
Author : Supriya Bajpai
在股票交易中,特征提取和交易策略设计是利用机器学习技术实现长期收益的两项重要任务。通过获取交易信号来设计交易策略可以实现交易收益最大化。论文中将深度强化学习理论应用于印度市场的股票交易策略和投资决策。利用三个经典的深度强化学习模型Deep Q-Network、Double Deep Q-Network和Dueling Double Deep Q-Network对10个印度股票数据集进行了系统的实验。并对模型的性能进行了评价和比较
Robo-Advising: Enhancing Investment with Inverse Optimization and Deep ReinforcementLearning(arXiv 2105.09264)
Author : Haoran Wang, Shi Yu
机器学习(ML)已被金融行业视为一种强大的工具,在投资管理等各个领域都有显著的应用。论文提出了一个全周期数据驱动的投资机器人咨询框架,由两个ML代理组成。第一代理是一种逆投资组合优化代理,它利用在线逆优化方法直接从投资者的历史配置数据中推断投资者的风险偏好和预期收益。第二个是深度强化学习(deep reinforcement learning, RL)代理,它将所推断的预期收益序列聚合在一起,形成一个新的多周期均值-方差投资组合优化问题,这样就可以使用深度强化学习方法进行求解。论文中的投资计划应用于2016年4月1日至2021年2月1日的实际市场数据,表现持续优于代表总体市场最优配置的标准普尔500基准投资组合。这种优异表现可能归因于多周期规划(相对于单周期规划)和数据驱动的RL方法(相对于经典估计方法)。
Reinforcement learning in market games(arxiv 0710.0114)
Edward W. Piotrowski, Jan Sladkowski, Anna Szczypinska
金融市场投资就像许多的多人游戏一样——必须与其他代理人互动以实现自己目标。其中就包括与在市场上的活动直接相关的因素,和影响人类决策及其作为投资者表现的其他方面。如果区分所有子博弈通常是超出希望和资源消耗的。在这篇论文中研究了投资者如何面对许多不同的选择、收集信息并在不了解游戏的完整结构的情况下做出决策。论文将强化学习方法应用于市场信息理论模型 (ITMM)。尝试区分第 i 个代理的一类博弈和可能的动作(策略)。任何代理都将整个游戏类划分为她/他认为子类,因此对给定的子类采用相同的策略。划分标准基于利润和成本分析。类比类和策略通过学习过程在各个阶段更新。
Dreaming machine learning: Lipschitz extensions for reinforcement learning on financial markets(arXiv 1909.03278)
J. M. Calabuig, H. Falciani, E. A. Sánchez-Pérez
论文考虑了一种用于在金融市场框架内构建新的强化学习模型的准度量拓扑结构。它基于在度量空间中定义的奖励函数的 Lipschitz 型扩展。具体来说,McShane 和 Whitney 被用于奖励函数,该函数由给定时间投资决策产生的收益的总评估定义。将度量定义为欧几里得距离和角度度量分量的线性组合。从时间间隔开始的所有关于系统演化的信息都被用来支持奖励函数的扩展,并且通过添加一些人为产生的状态来丰富这个数据集。论文中说到,这种方法的主要新颖之处在于产生了更多状态(论文中称之为“dreams”)以丰富学习的方式。使用代表金融市场演变的动态系统的一些已知状态,使用现有的技术可以通过插入真实状态和引入一些随机变量来模拟新状态。这些新状态用于为学习算法提供训练数据,该算法的目的是通过遵循典型的强化学习方案来改进投资策略。
Automatic Financial Trading Agent for Low-risk Portfolio Management using Deep Reinforcement Learning(arXiv 1909.03278)
自主交易代理是人工智能解决资本市场投资组合管理问题最活跃的研究领域之一。投资组合管理问题的两个主要目标是最大化利润和抑制风险。大多数解决这个问题的方法只考虑最大化回报。但是这篇论文提出了一种基于深度强化学习的交易代理,它在管理投资组合时,不仅考虑利润最大化,还考虑风险约束。论文中还提出了一个新的目标策略,让交易代理学会更偏向低风险的行动。这个新的目标策略可以通过超参数来调整最优行为的贪心程度来降低行动的风险。论文所提出的交易代理通过加密货币市场的数据来验证性能,因为加密货币市场是测试交易代理的最佳试验场,因为每分钟积累的数据量巨大,市场波动性极大。作为实验结果,在测试期间,代理实现了 1800% 的回报,并提供了现有方法中风险最小的投资策略。并且在另一个实验表明,即使市场波动很大或训练周期很短,交易的代理也能保持稳健的泛化性能。
Application of deep reinforcement learning for Indian stock trading automation(arXiv 2106.16088)
Author : Supriya Bajpai
在股票交易中,特征提取和交易策略设计是利用机器学习技术实现长期收益的两项重要任务。通过获取交易信号来设计交易策略可以实现交易收益最大化。论文中将深度强化学习理论应用于印度市场的股票交易策略和投资决策。利用三个经典的深度强化学习模型Deep Q-Network、Double Deep Q-Network和Dueling Double Deep Q-Network对10个印度股票数据集进行了系统的实验。并对模型的性能进行了评价和比较
Robo-Advising: Enhancing Investment with Inverse Optimization and Deep ReinforcementLearning(arXiv 2105.09264)
Author : Haoran Wang, Shi Yu
机器学习(ML)已被金融行业视为一种强大的工具,在投资管理等各个领域都有显著的应用。论文提出了一个全周期数据驱动的投资机器人咨询框架,由两个ML代理组成。第一代理是一种逆投资组合优化代理,它利用在线逆优化方法直接从投资者的历史配置数据中推断投资者的风险偏好和预期收益。第二个是深度强化学习(deep reinforcement learning, RL)代理,它将所推断的预期收益序列聚合在一起,形成一个新的多周期均值-方差投资组合优化问题,这样就可以使用深度强化学习方法进行求解。论文中的投资计划应用于2016年4月1日至2021年2月1日的实际市场数据,表现持续优于代表总体市场最优配置的标准普尔500基准投资组合。这种优异表现可能归因于多周期规划(相对于单周期规划)和数据驱动的RL方法(相对于经典估计方法)。
Share Http URL: http://www.wittx.cn/get_news_message.do?new_id=1045

Best Last Month
Electronic electrician by wittx

Information industry by wittx
Computer software and hardware by wittx
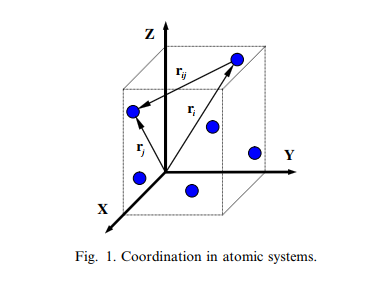
Information industry by wittxAn introduction to computational nanomechanics and materials
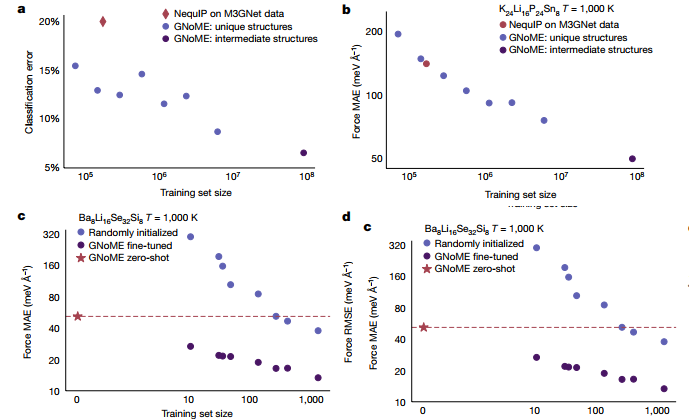
Information industry by wittx
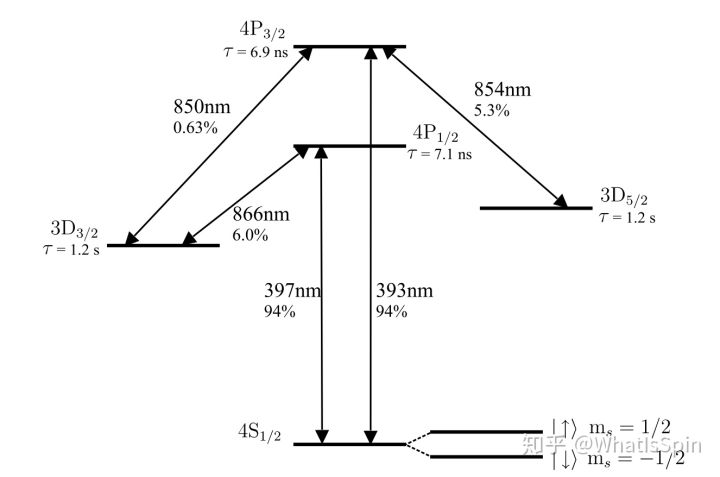
Electronic electrician by wittx
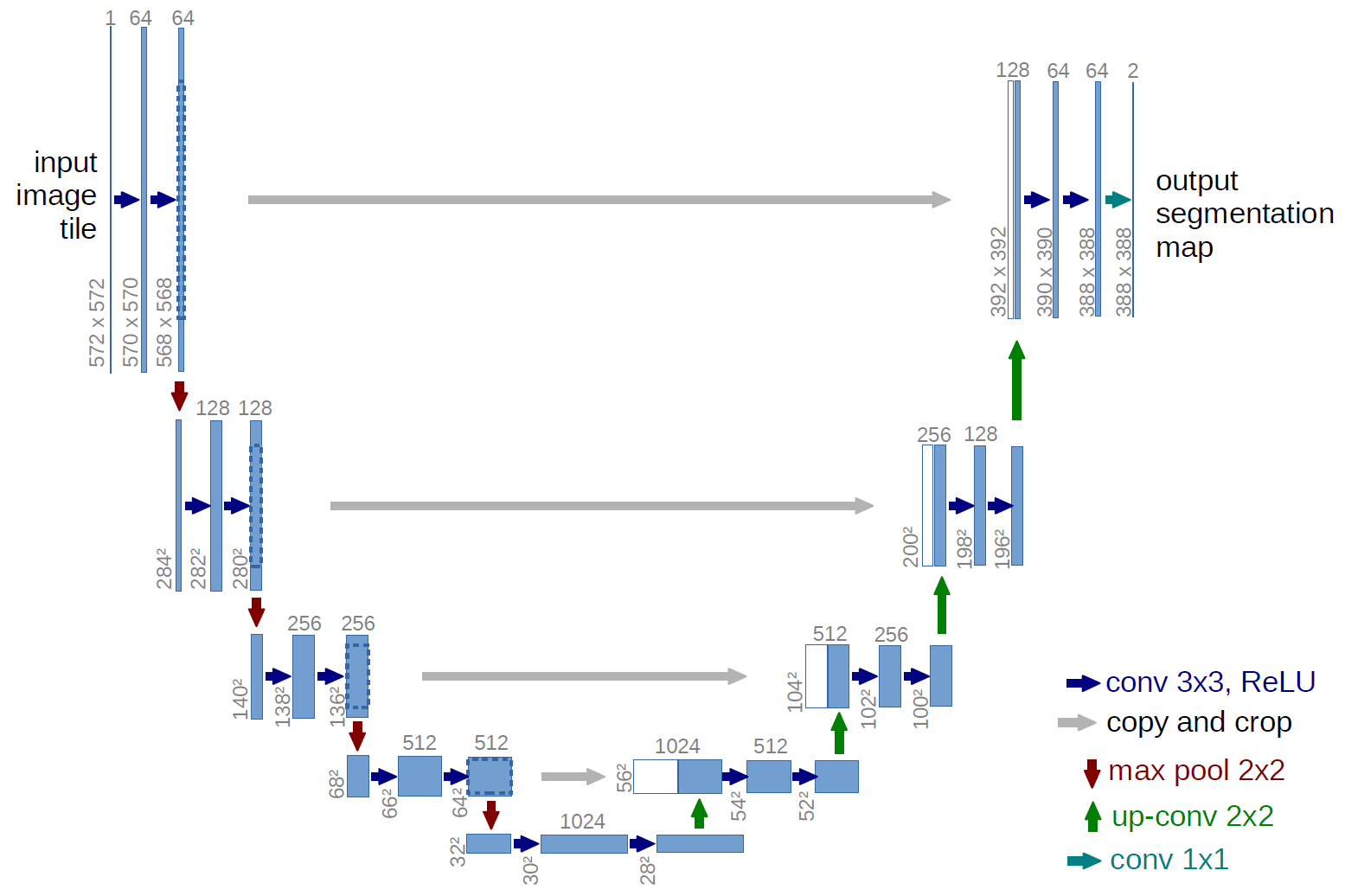
Information industry by wittxHigh-Resolution Model for Segmenting and Predicting Brain Tumor Based on Deep UNet with Multi Attent
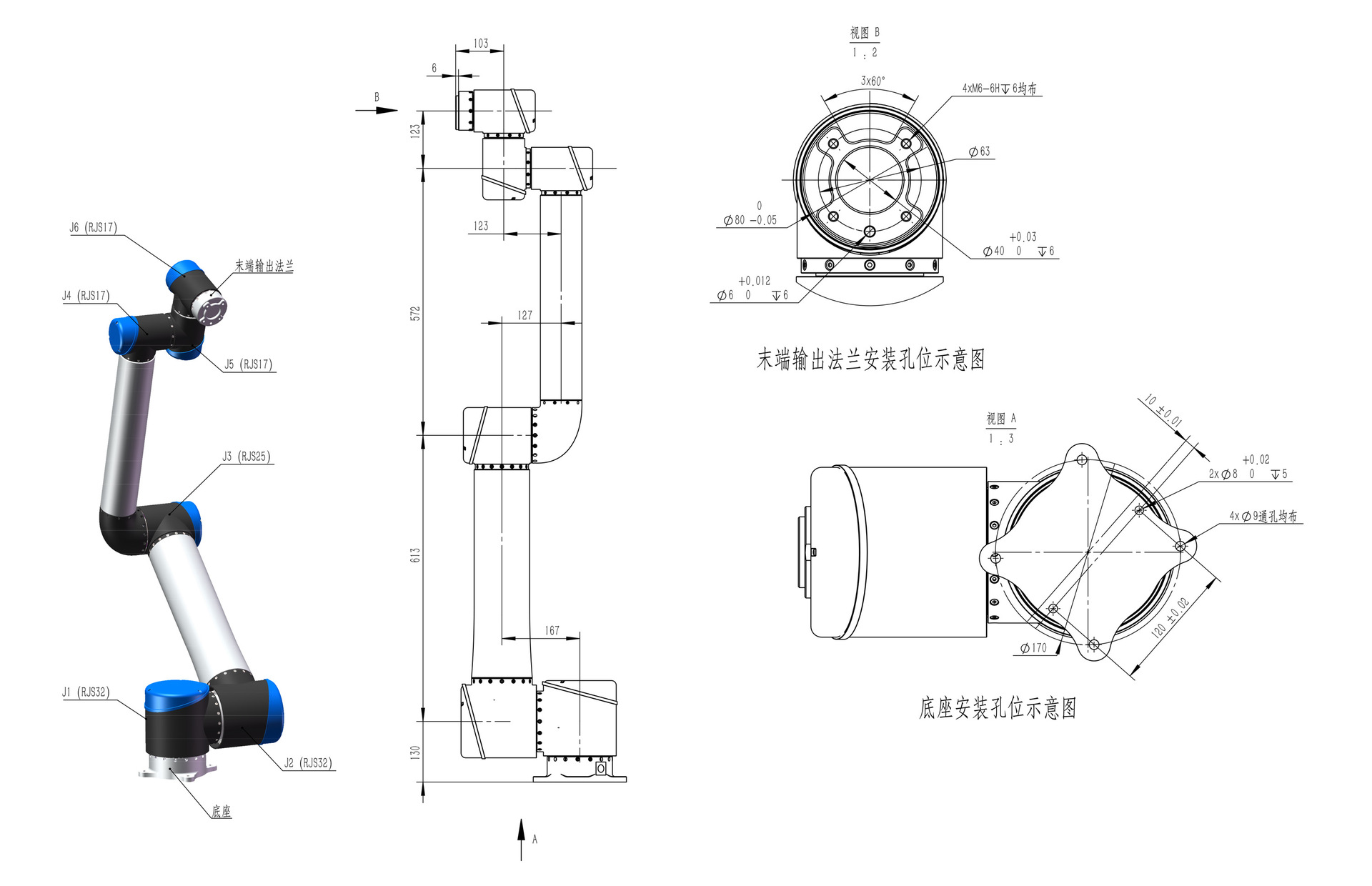
Information industry by wittx

Information industry by wittx

Information industry by wittx
